我对分布式计算框架的理解与设计
2017-12-06 12:07
267 查看
谢谢大家来看这篇文章,我想花点时间分享一下我对分布式计算的理解。
分布式服务有很多,比如hbase, hadoop, spark等,我所要讲述的重点不是这些服务的原理,而是用更浅显的话讲述更深刻的设计。
如何把多个的机器组合起来完成一件简单的计算任务,所以这方面的架构设计更多的关注服务器间的关系。
下面我们来设计一个框架,以进行简单的分布式计算。
我们假设计算目标有三类:
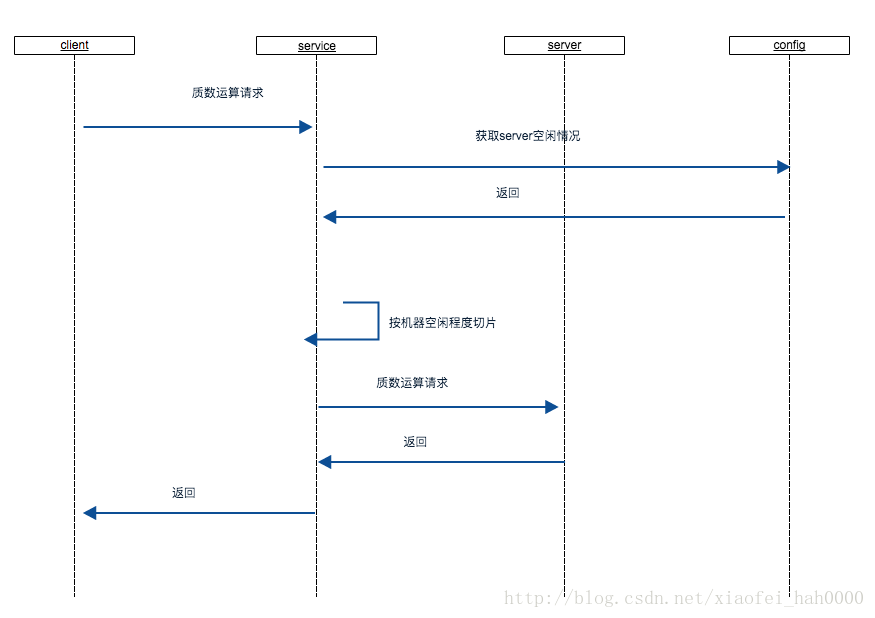
1.分布计算能力,简单多节点计算, 计算1万以内的质数。
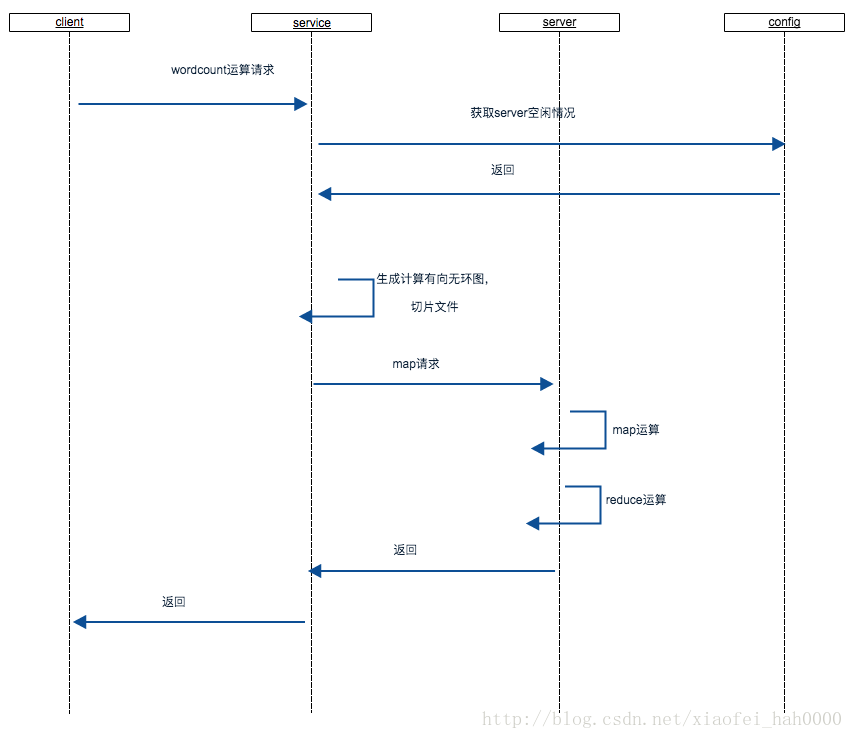
2.map-reduce,以wordcount为例。
3.资源查询,分布式查询数据库
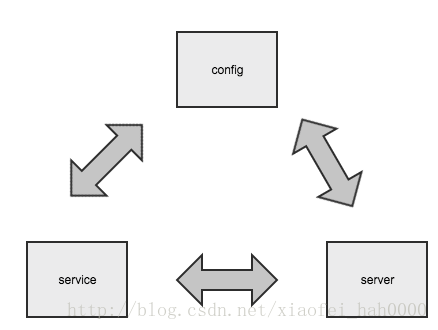
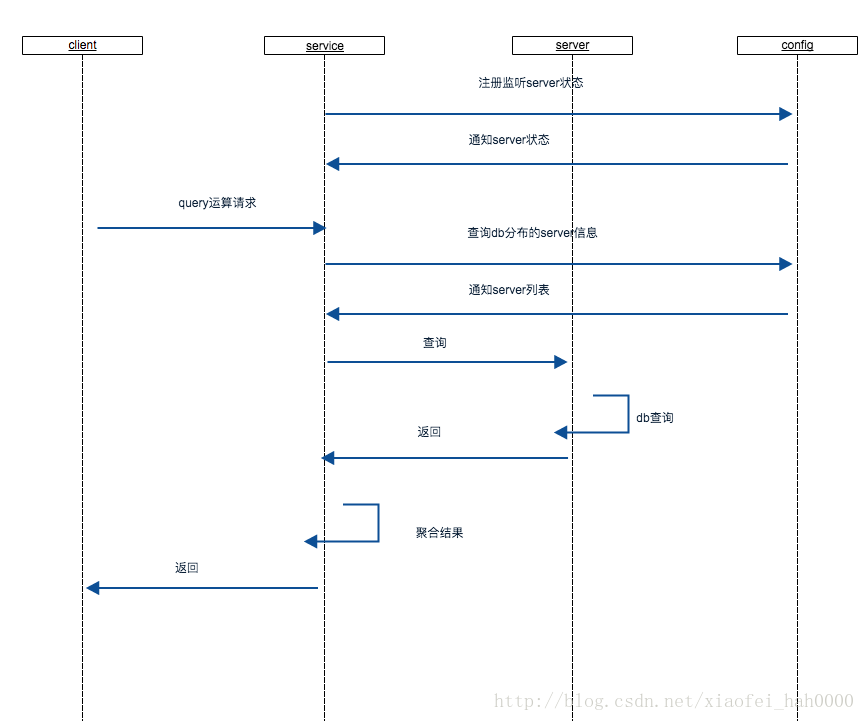
我想让service接受请求,server进行计算, 流程会是怎样的呢。
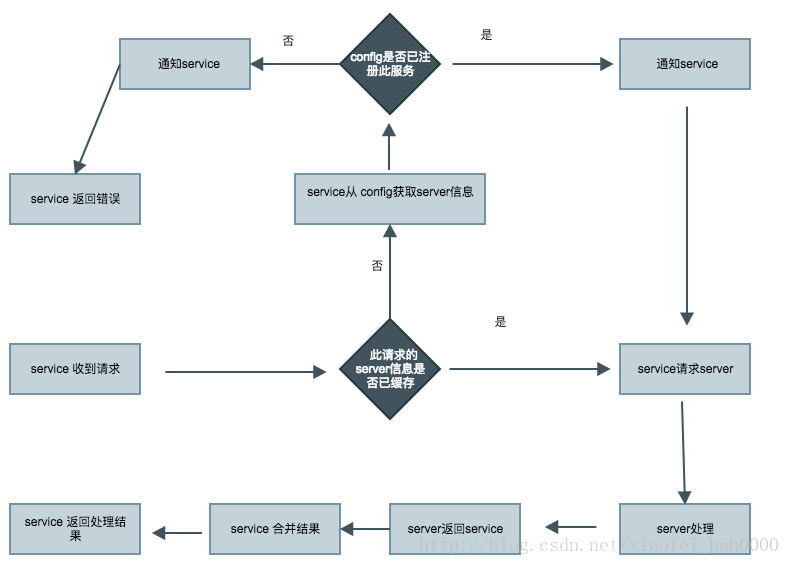
实际的处理比这个要复杂,比如请求过期处理等。
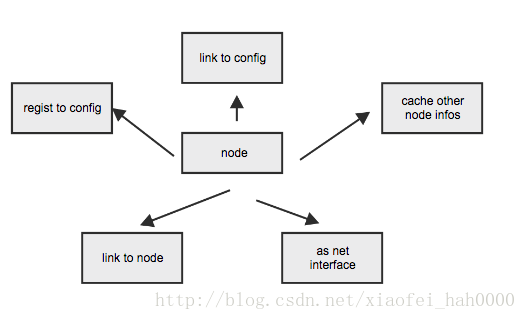
相似的逻辑实现,所以很自然地,我把节点的关系重新定义为 config-node
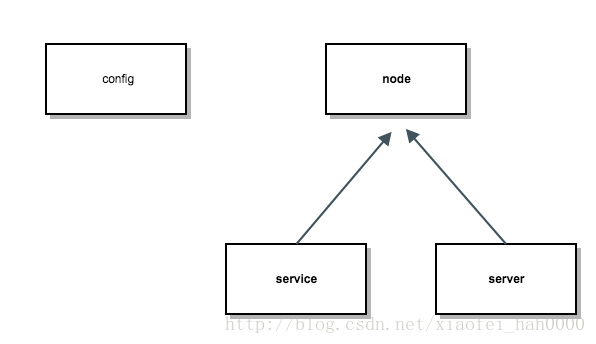
为了简单处理,抽象了一个node,service与server共同继承node, 由node负责与config通信。
下面我将对系统设计的协议进行设计。
(实际上在通用对外服务是不能用protobuf的,请大家思考为什么。)
下面来定义我们的代码结构
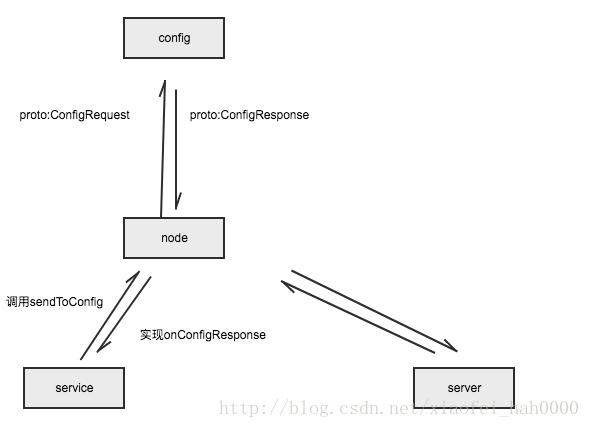
config请求处理:
相应的node接口
service与server继承node后实现onConfigResponse即可。
例:http://dist.alibaba-inc.com/calc/prime?start=1&end=10000
分布式查询
[post] http://dist.alibaba-inc.com/calc/query



对于map reduce运算,实际处理过程是这样的
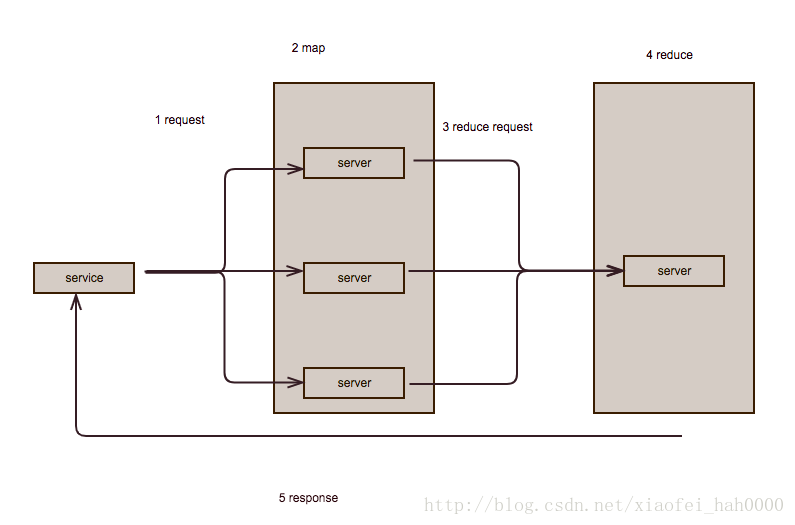
这里的query在设计上是简化处理了的,生产上可能需要注意结果缓存,主从同步等。
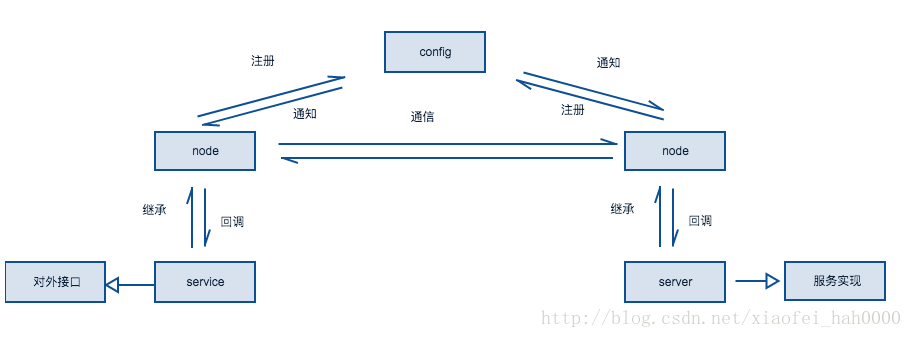
从上面的设计上,我们可以发现,分布式处理的基础需要有一个config(配置服务器),及内部通信协议。
另外,节点的备份机制也很重要, 比如 config崩溃或者server崩溃的结果要做到不受影响。
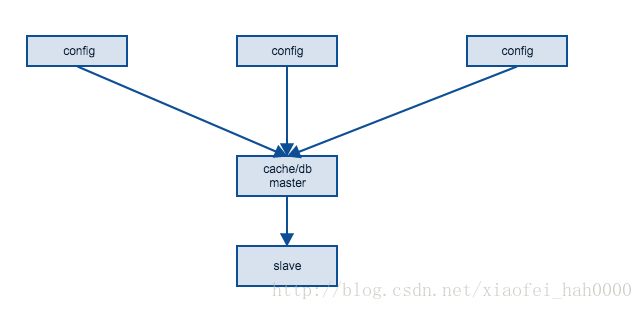
其自身的功能崩溃恢复可以采用一种简单有效的方法。每个config节点都存有所有config的信息并且同步到各个node(service/server)。
每当新起一个config或者关掉一个,信息更新一次,node与config失联后再主动选择一个连接。
分布式服务有很多,比如hbase, hadoop, spark等,我所要讲述的重点不是这些服务的原理,而是用更浅显的话讲述更深刻的设计。
如何把多个的机器组合起来完成一件简单的计算任务,所以这方面的架构设计更多的关注服务器间的关系。
下面我们来设计一个框架,以进行简单的分布式计算。
我们假设计算目标有三类:
1.分布计算能力,简单多节点计算, 计算1万以内的质数。
2.map-reduce,以wordcount为例。
3.资源查询,分布式查询数据库
模块设计
在架构上, 可以将服务中的服务器分三个模块:| 模块 | 含义 |
|---|---|
| config | 配置服务 |
| service | 对外接口服务 |
| server | 工作服务(worker) |
流程设计
一条简单的请求过来,可能经过的处理过程:实际的处理比这个要复杂,比如请求过期处理等。
抽象设计
在框架内通个上,service与server都会向config注册,通信以及获取节点情况等,因此会有很多相似的逻辑实现,所以很自然地,我把节点的关系重新定义为 config-node
为了简单处理,抽象了一个node,service与server共同继承node, 由node负责与config通信。
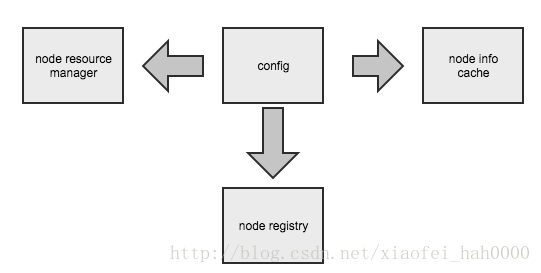
功能设计
config在框架里起到分配资源与注册服务的功能。
node功能
整体功能
下面我将对系统设计的协议进行设计。
协议设计
为了简单方便,我将模块间的通信采用protobuf。(实际上在通用对外服务是不能用protobuf的,请大家思考为什么。)
config:
message ConfigRequest{
optional ConfigAuthReq auth= 1;
optional ConfigGetNodesReq get_nodes= 2;
}
message ConfigResponse{
optional ConfigAuthRsp auth = 1;
optional ConfigGetNodesRsp get_nodes= 2;
optional ConfigNotifyNodes notify_nodes= 3;
}server
message ServerRequest{
required ServerDiag diags = 1;
required ServerDiagNodeType diag_type = 2;
optional ServerAuthReq auth = 3;
optional PrimeQueryReq prime = 4;
optional ServerWordCountReq wc = 5;
optional ServerQueryReq query = 6;
optional ServerBGReq bg = 7;
}
message ServerResponse{
optional ServerAuthRsp auth = 1;
optional PrimeQueryRsp prime = 2;
optional ServerWordCountRsp wc = 3;
optional ServerQueryRsp query = 4;
optional ServerBGResponse bg = 5;
}下面来定义我们的代码结构
代码架构
下面的代码架构主要争对config-node而设计。config请求处理:
class Config{
public:
void OnRequest(const TcpConnPtr& con, ConfigRequest& request);
}相应的node接口
class Node{
protected:
virtual void onConfigResponse(const TcpConnPtr& con,ConfigResponse& response);
protected:
void sendToConfig(const TcpConnPtr& con,ConfigResponse& response);
};service与server继承node后实现onConfigResponse即可。
对外接口设计
为了接口方便,对外接口均设为http接口,并支持网页。prime:
[get] http://dist.alibaba-inc.com/calc/prime| 参数 | 含义 |
|---|---|
| start | 起始值 |
| end | 结束值 |
wordcount
[post] http://dist.alibaba-inc.com/calc/wordcount| 参数 | 含义 |
|---|---|
| data | 待计算的文件 |
| tokenize | 分隔符 |
[post] http://dist.alibaba-inc.com/calc/query
| 参数 | 含义 |
|---|---|
| app | 应用名 |
| db | 库 |
| collection | 连接 |
| data | 查询条件 |
service与server程序架构
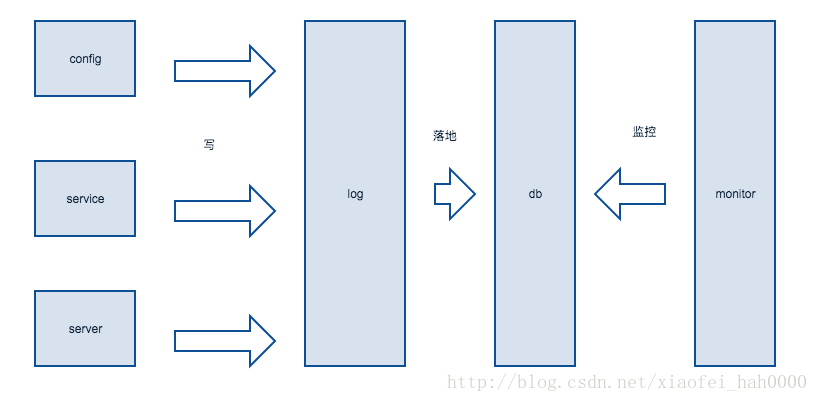
流程监控设计
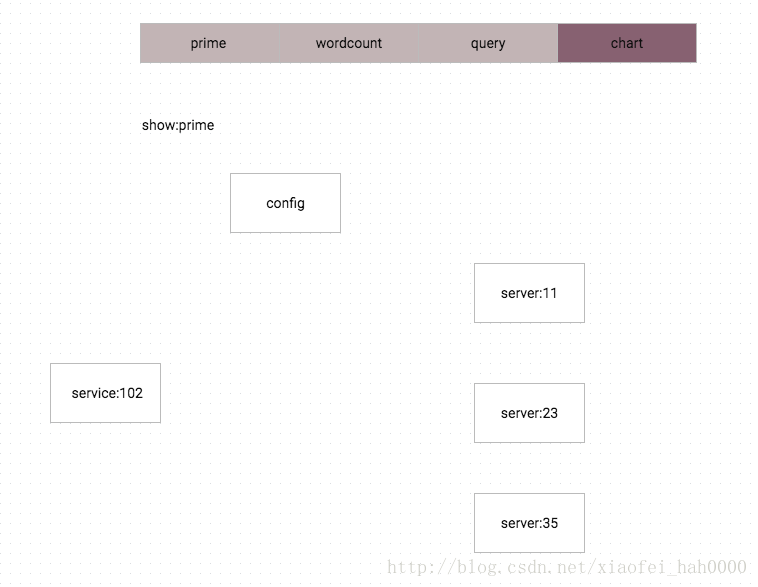
为了方便了解每次请求的全链路情况,我在原架构中添加了日志与监控模块功能显示设计
prime
wordcount
query
chart
业务流程图
prime
wordcount
对于map reduce运算,实际处理过程是这样的
query
这里的query在设计上是简化处理了的,生产上可能需要注意结果缓存,主从同步等。
从上面的设计上,我们可以发现,分布式处理的基础需要有一个config(配置服务器),及内部通信协议。
另外,节点的备份机制也很重要, 比如 config崩溃或者server崩溃的结果要做到不受影响。
崩溃恢复机制
config
对于config的功能,由于其核心功能是当前节点分布,是动态数据,因此数据安全可以采用的方法有很多,比如redis,mysql, mongo等。其自身的功能崩溃恢复可以采用一种简单有效的方法。每个config节点都存有所有config的信息并且同步到各个node(service/server)。
每当新起一个config或者关掉一个,信息更新一次,node与config失联后再主动选择一个连接。
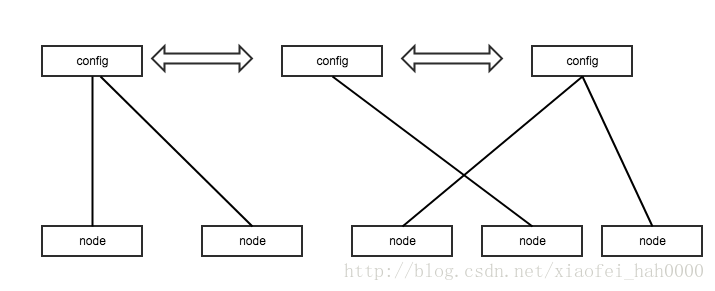
node
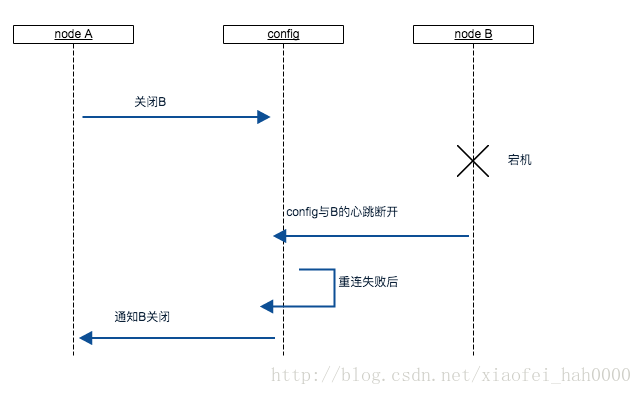
config提供node相互关注的能力, 即node A可以关注node B, 当node B断开后,config会通知像A一样所有关注它的node。

相关文章推荐
- 基于分布式计算平台的流数据挖掘框架设计
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
- 分布式计算开源框架Hadoop介绍
- 高性能分布式计算与存储设计概要
- 分布式计算开源框架Hadoop介绍
- 分布式服务框架原理(一)设计和实现
- 分布式计算开源框架Hadoop入门实践
- 【设计模式 7】从公司的目前框架和API Gateway,谈谈对外观模式的理解
- 分布式计算框架Hadoop
- 深入浅出的理解框架(Struts2、Hibernate、Spring)与 MVC 设计模式
- 【niubi-job——一个分布式的任务调度框架】----框架设计原理以及实现
- 从JAVA多线程理解到集群分布式和网络设计的浅析
- 分布式计算开源框架Hadoop入门实践
- VM Depot 分布式计算框架主题应用精选
- 分布式计算开源框架Hadoop入门实践
- Spark RDDs(弹性分布式数据集):为内存中的集群计算设计的容错抽象
- DCFramework 动态分布式计算框架(01)-- 基础结构
- 分布式计算框架Hadoop原理及架构全解
- 从Storm和Spark 学习流式实时分布式计算的设计
- 分布式计算开源框架Hadoop入门实践(一)