keras 搬砖系列-自编码器
2017-12-05 15:56
323 查看
自编码器(AutoEncoder)
本文大致分为理论介绍、公式推导,代码实现这几个部分。自编码器与PCA算法类似,是数据的一种降维。它将数据从f(x)变为g(x'),编码过程就是一个维度降低的过程。所以我们通常利用自编码器的前半部分来作为特征提取。
自编码器:
一、压缩:将图片用几个神经元点表现出来
二、解压:将压缩后的图片解压出来
几种自编码器:
自编码器是神经网络的一种,经过训练后能尝试将输入复制到输出。自编码器内部有一个隐藏层,可以产生编码表示输入。该网络可以看作两部分组成:一个由函数表示的编码器和一个生成重构的解码器。如果一个自编码器只是简单地将g(f(x)) = x,那么这个自编码器没什么用处。相反,我们不应该将自编码器设计输入到输出完全相等。这通常需要向自编码器增加一个约束,使它只能近似地复制,并只能复制与训练数据相似的输入。这些约束强制模型考虑输入数据的哪些部分会被优先复制,因此它往往能学习到数据的有用特性。
1,欠完备自编码器
从自编码器获得有用的特征的一种方法是限制h的维度比x小,这种编码器维度小于输入维度的自编码器称为欠完备自编码器。欠完备自编码器会学习出与PCA相同的子空间。这种情况下自编码器在训练执行任务的同时学习到了数据的主元子空间,如果编码器器和解码器被赋予了过大的容量,自编码器会执行任务而捕捉不大任何有关的分布有用的信息。
ae0c
2,正则自编码器
正则自编码器使用的损失函数可以鼓励模型学习其他特性,而不必限制使用浅层的编码器和解码器以及小的编码维数来限制模型的容量。这些特性包括稀疏表示,表示的小导数、以及对噪声或输入缺失的鲁棒性。即使模型容量大到足以学习一个无意义的恒等函数,非线性且过完备的正则自编码器仍然从数据中学习到一些关于数据分布的有用的信息。
3,稀疏自编码器
稀疏自编码器简单地在训练编码层的稀疏惩罚和重构误差。其中g(h)是解码器的输出,通常h是编码器的输出。稀疏编码器一般用来学习特征,以便使用分类这样的任务。稀疏正则化的自编码器必须反应训练数据集的独特统计特征,而不是简单地充当恒等函数。以这种方式训练,执行附带稀疏惩罚的复制任务可以学习到有用的特征模型。
4,去噪自编码器
去噪自编码器(DAE)最小化L(x,g(f(x'))),其中x'是被某种噪声破坏的x的副本。因此去噪自编码器必须撤销这些损坏,而不是简单的复制输入。是一类接受损坏数据作为输入,并训练来预测原始未被破坏数据作为输出的自编码。DAE的训练准则是能让自编码器学到能估计数据分布得分的向量场(g(f(x))-x)。
5,收缩自编码器
另一正则化自编码器的策略是使用一个类似稀疏自编码器的惩罚
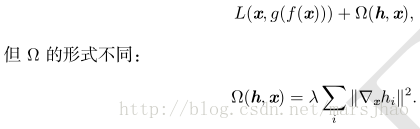

相关文章推荐
- keras搬砖系列-正则化
- keras搬砖系列-Resnet-34详解
- keras搬砖系列-softmax(二)
- keras搬砖系列-线性回归
- keras搬砖系列-Flatten ValueError
- keras搬砖系列-多GPU上使用keras
- keras搬砖系列-VGG19
- keras搬砖系列-inception v2与v3
- keras搬砖系列-GoogLeNet
- keras搬砖系列-重温序贯模型与函数模型
- keras搬砖系列-重新理解ResNet网络
- keras搬砖系列-inception module
- keras搬砖系列-迁移学习与微调
- keras搬砖系列-inception-resnet-v2实现
- keras搬砖系列-模型可视化
- keras搬砖系列-BN层
- keras搬砖系列-inception流派
- keras搬砖系列-vgg16进行分类
- keras搬砖系列-正则项
- keras搬砖系列-细读GoogleNet