Batch Gradient Descent
2017-11-30 21:32
225 查看
Batch Gradient Descent
We use linear regression as example to explain this optimization algorithm.1. Formula
1.1. Cost Function
We prefer residual sum of squared to evaluate linear regression.J(θ)=12m∑i=1n[hθ(xi)−yi]2
1.2. Visualize Cost Function
E.g. 1 :one parameter only θ1 –> hθ(x)=θ1x1
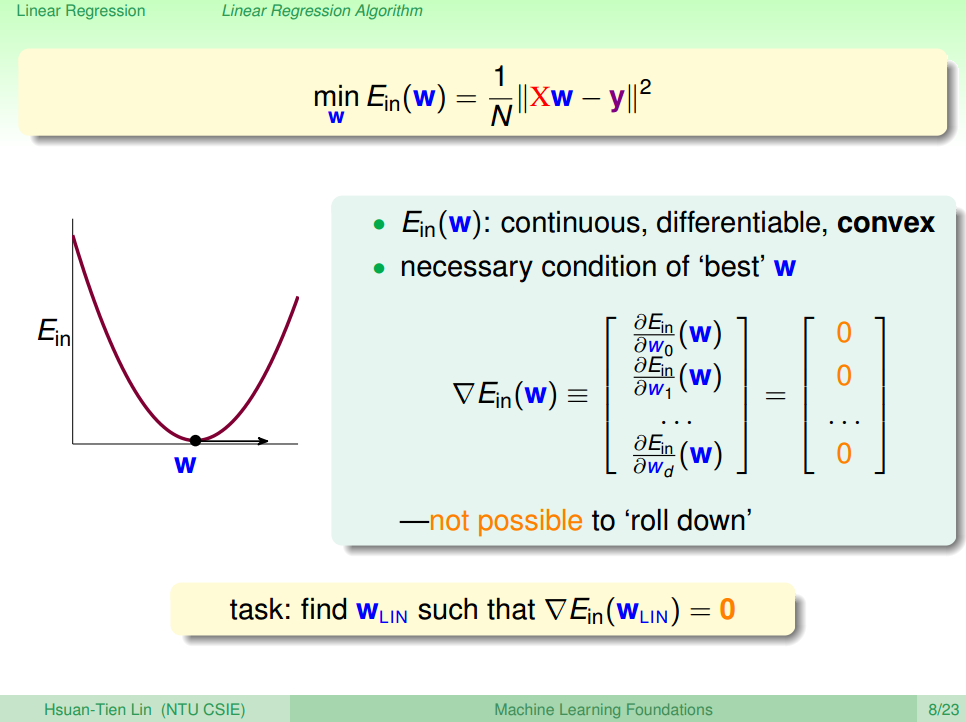
1. Learning Curve 1 [1]
E.g. 2 :
two parameters θ0,θ1 –> hθ(x)=θ0+θ1x1
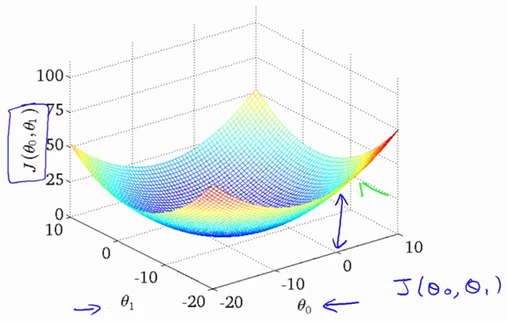
2. Learning Curve 2 [2]
Switch to contour plot
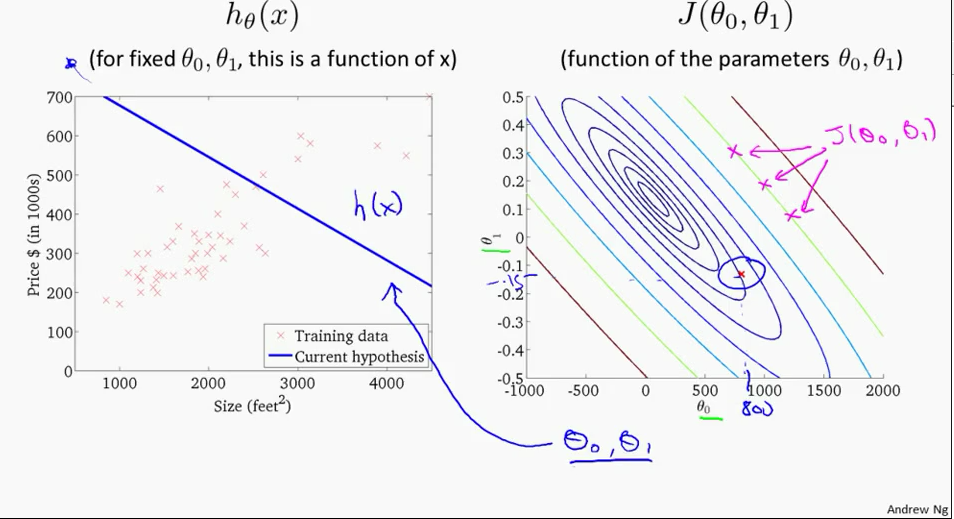
3. Learning Curve 2 - contour[2]
1.3. Gradient Descent Formula
For all θi∂Jθ∂θi=1m∑i=1n[hθ(xi)−yi]⋅(xi)
E.g.,
two parameters θ0,θ1 –> hθ(x)=θ0+θ1x1
For i = 0 :
∂Jθ∂θ0=1m∑i=1n[hθ(xi)−yi]⋅(x0)
For i = 1:
∂Jθ∂θ1=1m∑i=1n[hθ(xi)−yi]⋅(x1)
% Octave %% =================== Gradient Descent =================== % Add a column(x0) of ones to X X = [ones(len, 1), data(:,1)]; theta = zeros(2, 1); alpha = 0.01; ITERATION = 1500; jTheta = zeros(ITERATION, 1); for iter = 1:ITERATION % Perform a single gradient descent on the parameter vector % Note: since the theta will be updated, a tempTheta is needed to store the data. tempTheta = theta; theta(1) = theta(1) - (alpha / len) * (sum(X * tempTheta - Y)); % ignore the X(:,1) since the values are all ones. theta(2) = theta(2) - (alpha / len) * (sum((X * tempTheta - Y) .* X(:,2))); %% =================== Compute Cost =================== jTheta(iter) = sum((X * theta - Y) .^ 2) / (2 * len); endfor
2. Algorithm
For all θiθi:=θi−α∂∂θiJ(θ1,θ2,…,θn)
E.g.,
two parameters θ0,θ1 –> hθ(x)=θ0+θ1x1
For i = 0 :
θ0:=θ0−α1m∑i=1n[hθ(xi)−yi]
For i = 1 :
θ1:=θ1−α1m∑i=1n[hθ(xi)−yi]⋅(x1)
Iterative for multiple times (depends on data content, data size and step size). Finally, we could see the result as below.
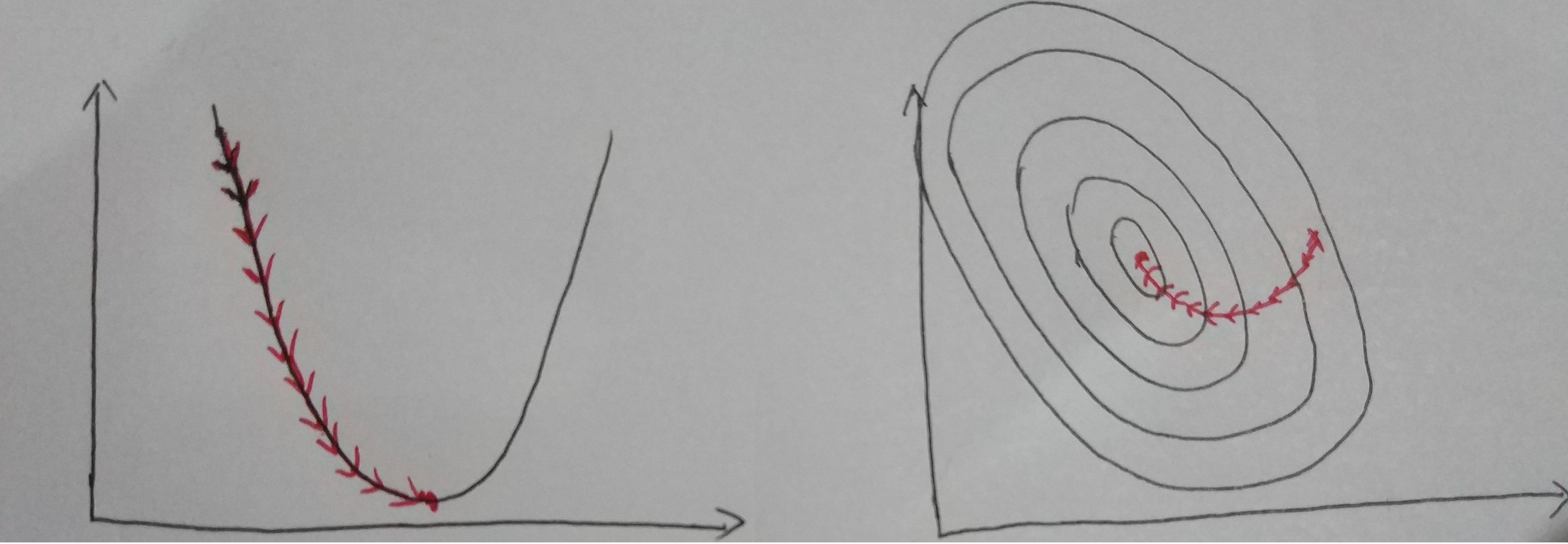
Visualize Convergence
3. Analyze
| Pros | Cons |
|---|---|
| Controllable by manuplate stepsize, datasize | Computing effort is large |
| Easy to program |
4. How to Choose Step Size?
Choose an approriate step size is significant. If the step size is too small, it doesn’t hurt the result, but it took even more times to converge. If the step size is too large, it may cause the algorithm diverge (not converge).The graph below shows that the value is not converge since the step size is too big.
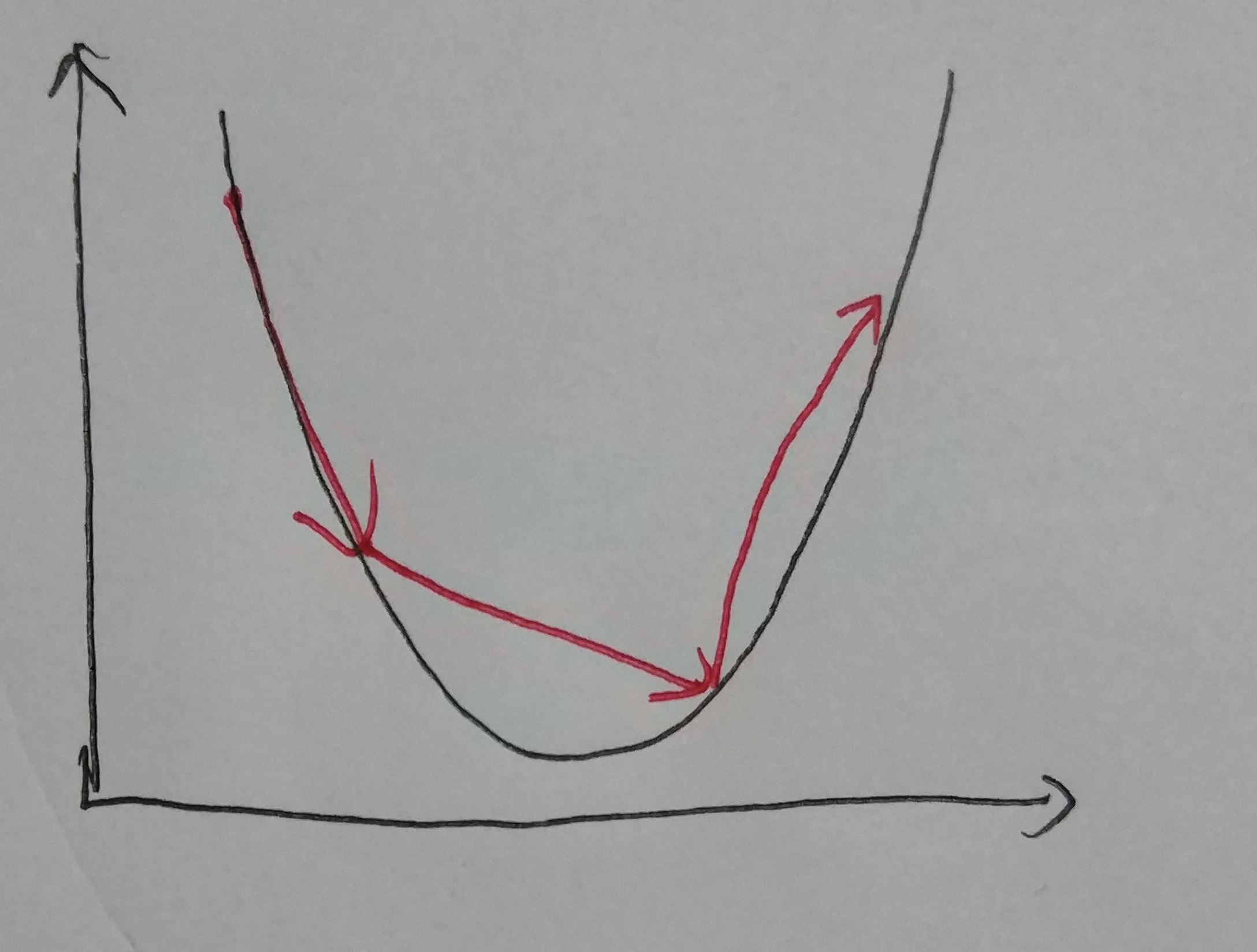
Large Step Size
The best way, as far as I know, is to decrease the step size according to the iteration times.
E.g.,
α(t+1)=αtt
or
α(t+1)=αtt√
Reference
机器学习基石(台湾大学-林轩田)\lecture_slides-09_handout.pdfCoursera-Standard Ford CS229: Machine Learning - Andrew Ng

相关文章推荐
- 多变量线性回归中的批量梯度下降法(Batch Gradient Descent in Linear Regression with Multiple Variable)
- [Machine Learning] 梯度下降(BGD)、随机梯度下降(SGD)、Mini-batch Gradient Descent、带Mini-batch的SGD
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比[转]
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
- 梯度下降(BGD)、随机梯度下降(SGD)、Mini-batch Gradient Descent、带Mini-batch的SGD
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
- [Machine Learning]随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的对比
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
- batch&stochasic gradient descent
- Mini-Batch Gradient Descent
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
- 梯度下降(BGD)、随机梯度下降(SGD)、Mini-batch Gradient Descent、带Mini-batch的SGD
- 深度学习—加快梯度下降收敛速度(一):mini-batch、Stochastic gradient descent
- Batch Gradient Descent vs. Stochastic Gradient Descent
- 【机器学习学习过程中的笔记1——Stochastic gradient descent 和 Batch gradient descent 】
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
- Batch Gradient Descent(python)
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
- Mini-Batch Gradient Descent介绍以及如何决定Batch Size