深度学习:语言模型的评估标准
2017-11-30 17:03
369 查看
http://blog.csdn.net/pipisorry/article/details/78677580
语言模型的评估主要measure the closeness,即生成语言和真实语言的近似度。
Test set perplexity is the most widely accepted method for evaluating language models, both for use in recognition/translation applications and generation. It has the advantage that it is easy to measure and is widely used as a criteria for model fit, but the limitation that it is not directly matched to most tasks that language models are directly used for. For fair comparison, when computing the perplexity with the 5-gram LM, exclude all test words marked as 〈unk〉 (i.e., with low counts or OOVs) from consideration.
Meteor
[S. Banerjee and A. Lavie, “Meteor: An automatic metric for MT evaluation with improved correlation with human judgments,” in Proc. ACL Workshop Intrinsic Extrinsic Eval. Measures Mach. Transl. Summarization]
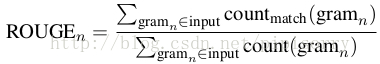
where count match denotes the number of n-grams co-occurring in the input and output.
一般ROUGE-1, 2 and W (based on weighted longest common subsequence).
[C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in Proc. ACL Workshop Text Summarization Branches Out, 2004]
n-gram precision scores are given by:
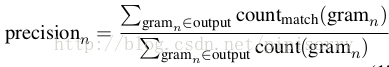
BLEU then combines the average logarithm of precision scores with exceeded length penalization.
most previous work report BLEU-1, i.e., they only compute precision at the unigram level, whereas BLEU-n is a geometric average of precision over 1- to n-grams.
[K. Papineni, S. Roukos, T. Ward, and W. J. Zhu, “BLEU: A method for automatic evaluation of machine translation,” ACL2002]
某小皮
Cider
it measures consistency between n-gram occurrences in generated and reference sentences, where this consistency is weighted by n-gram saliency and rarity.
不同评估方法的缺点讨论亦可参考[Vedantam, R., Lawrence Zitnick, C., & Parikh, D. Cider: Consensus-based image description evaluation. CVPR2015]
使用Amazon Mechanical Turk
如imge caption中following the guidelines proposed in [M. Hodosh, P. Young, and J. Hockenmaier, “Framing image description as a ranking task: Data, models and evaluation metrics,” J. Artif. Intell. Res.2013]
或者[Jaech, et al "Low-Rank RNN Adaptation for Context-Aware Language Modeling." arXiv2017]
from: http://blog.csdn.net/pipisorry/article/details/78677580
ref: [Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. TPAMI2017]
[Hoang, et al "Incorporating Side Information into Recurrent Neural Network Language Models." NAACL2016]
语言模型的评估主要measure the closeness,即生成语言和真实语言的近似度。
Classification accuracy
provides additional information about the power of a model, even if it is not being designed explicitly for text classification. [Jaech, et al. "Low-Rank RNN Adaptation for Context-Aware Language Modeling." arXiv 2017]Perplexity
perplexity is the geometric mean of the inverse probability for each predicted word.Test set perplexity is the most widely accepted method for evaluating language models, both for use in recognition/translation applications and generation. It has the advantage that it is easy to measure and is widely used as a criteria for model fit, but the limitation that it is not directly matched to most tasks that language models are directly used for. For fair comparison, when computing the perplexity with the 5-gram LM, exclude all test words marked as 〈unk〉 (i.e., with low counts or OOVs) from consideration.
Meteor
[S. Banerjee and A. Lavie, “Meteor: An automatic metric for MT evaluation with improved correlation with human judgments,” in Proc. ACL Workshop Intrinsic Extrinsic Eval. Measures Mach. Transl. Summarization]ROUGE
is a recall-oriented measure widely used in the summarization literature. It measures the n-gram recall between the candidate text and the reference text(s).where count match denotes the number of n-grams co-occurring in the input and output.
一般ROUGE-1, 2 and W (based on weighted longest common subsequence).
[C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in Proc. ACL Workshop Text Summarization Branches Out, 2004]
Blue
a form of precision of word n-grams between generated and reference sentences.Purely measuring recall will inappropriately reward long outputs. BLEU is designed to address such an issue by emphasizing precision.n-gram precision scores are given by:
BLEU then combines the average logarithm of precision scores with exceeded length penalization.
most previous work report BLEU-1, i.e., they only compute precision at the unigram level, whereas BLEU-n is a geometric average of precision over 1- to n-grams.
[K. Papineni, S. Roukos, T. Ward, and W. J. Zhu, “BLEU: A method for automatic evaluation of machine translation,” ACL2002]
某小皮
Coherence Evaluation
Neither BLEU nor ROUGE attempts to evaluate true coherence. There is no generally accepted and readily available coherence evaluation metric. simple approximations like number of overlapped tokens or topic distribution similarity (e.g., (Yan et al., 2011b; Yan et al., 2011a; Celikyilmaz and Hakkani-Tür, 2011)). [Li, Jiwei, et al. "A hierarchical neural autoencoder for paragraphs and documents." ACL2015] Cider
it measures consistency between n-gram occurrences in generated and reference sentences, where this consistency is weighted by n-gram saliency and rarity.不同评估方法的缺点讨论亦可参考[Vedantam, R., Lawrence Zitnick, C., & Parikh, D. Cider: Consensus-based image description evaluation. CVPR2015]
人工评估
ask for raters to give a subjective score使用Amazon Mechanical Turk
如imge caption中following the guidelines proposed in [M. Hodosh, P. Young, and J. Hockenmaier, “Framing image description as a ranking task: Data, models and evaluation metrics,” J. Artif. Intell. Res.2013]
或者[Jaech, et al "Low-Rank RNN Adaptation for Context-Aware Language Modeling." arXiv2017]
from: http://blog.csdn.net/pipisorry/article/details/78677580
ref: [Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. TPAMI2017]
[Hoang, et al "Incorporating Side Information into Recurrent Neural Network Language Models." NAACL2016]

相关文章推荐
- 深度学习语言模型的通俗讲解(Deep Learning for Language Modeling)
- R语言深度学习不同模型对比分析案例
- 应用于深度学习和自然语言处理的注意机制和记忆模型
- 深度学习-自然语言模型
- 如何利用深度学习技术训练聊天机器人语言模型?
- 3-深度学习-自然语言模型
- 如何利用深度学习技术训练聊天机器人语言模型?
- 深度学习与自然语言处理(7)_斯坦福cs224d 语言模型,RNN,LSTM与GRU
- 深度学习和自然语言处理的注意机制和记忆模型
- 深度学习和自然语言处理的应用和脉络2-复杂模型,最大熵-隐马尔科夫模型-条件随机场
- 应用于深度学习和自然语言处理的注意机制和记忆模型
- 深度学习在语音识别中的声学模型以及语言模型的应用
- OCR技术浅探:基于深度学习和语言模型的印刷文字OCR系统
- 深度学习-自然语言模型
- 深度学习-->NLP-->语言模型
- 深度学习之六,基于RNN(GRU,LSTM)的语言模型分析与theano代码实现
- TensorFlow实现经典深度学习网络(6):TensorFlow实现基于LSTM的语言模型
- 【深度学习】常用的模型评估指标
- 机器学习实战:模型评估和优化
- 神经网络不胜语, M-P模型似可寻(深度学习入门系列之三)