Spark SQL将数据写入Mysql表的一些坑
2017-11-30 11:58
141 查看
但是将数据处理完了之后,存入Mysql时,报错了:
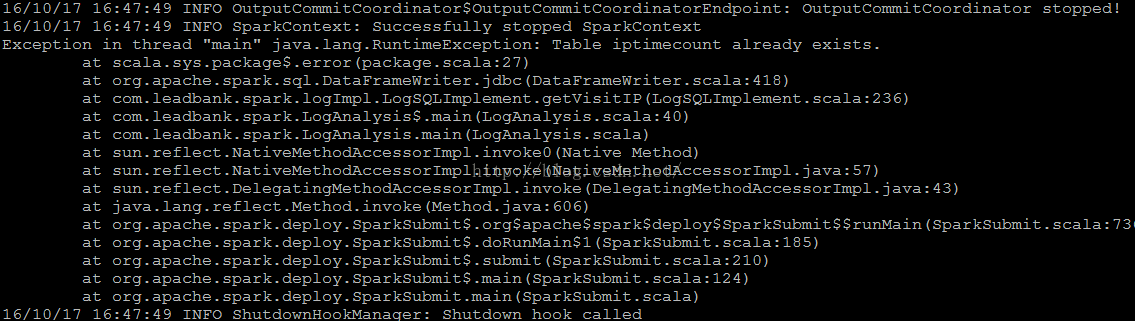
代码的基本形式为:
[java] view
plain copy
val r1: Dataset[Row] = data.groupBy(***)...
r1.write.jdbc(url,"iptimecount",prop)
根据图片中的报错,搜索资料,得知是由于Spark SQL 中的Save Mode导致的,Spark
SQL的官方文档中对Savemode进行了说明:
默认情况下,使用SaveMode.ErrorIfExists,也就是说,当从Spark中插入到MySQL表中的时候,如果表已经存在,则直接报错,想想真觉得这默认值有点坑。
于是修改Savemode,将代码改成:
[java] view
plain copy
r1.write.mode(SaveMode.Append).jdbc(url,"iptimecount",prop)
再次执行,本以为应该会顺利存入到数据库中了,没想到还是报错:
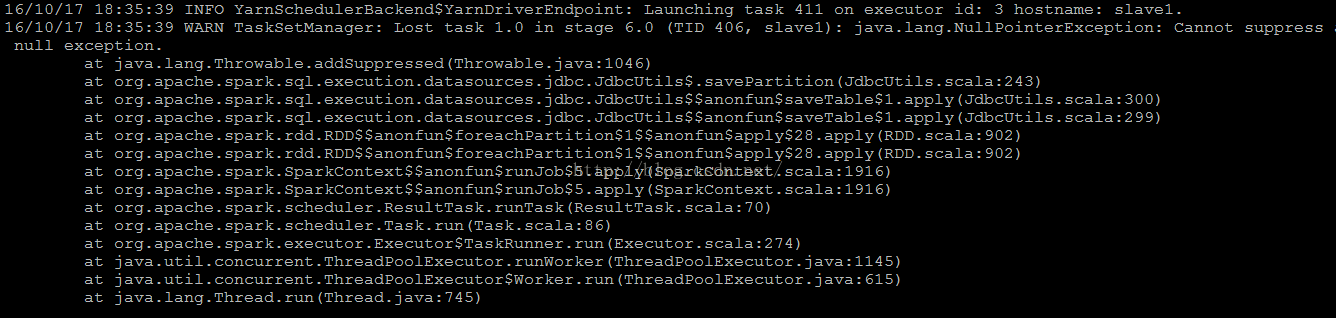
看到这个错误,我有点茫然,不清楚是哪里的问题。
后来,在一次测试中,将MySQL中将原来的表格删除后,再次提交任务,能顺利将数据存入到MySQL中,但是,使用desc查看表的结构,发现在Spark SQL中列类型为String类型的,在MySQL中对应为Text类型,于是我猜测应该是我之前创建的表格中,将列的类型定义为char和varchar导致的。
于是,我删除表格,重新创建表格,将char和varchar类型改为Text,再次执行,顺利的将数据从Spark SQL中存入到了Mysql.
另附一些注意事项:
数据存入Mysql注意事项
A. 尽量先设置好存储模式
默认为SaveMode.ErrorIfExists模式,该模式下,如果数据库中已经存在该表,则会直接报异常,导致数据不能存入数据库.另外三种模式如下:
SaveMode.Append 如果表已经存在,则追加在该表中;若该表不存在,则会先创建表,再插入数据;
SaveMode.Overwrite 重写模式,其实质是先将已有的表及其数据全都删除,再重新创建该表,最后插入新的数据;
SaveMode.Ignore 若表不存在,则创建表,并存入数据;在表存在的情况下,直接跳过数据的存储,不会报错。
B. 设置存储模式的步骤为:
org.apache.spark.sql.SaveMode
......
df.write.mode(SaveMode.Append)
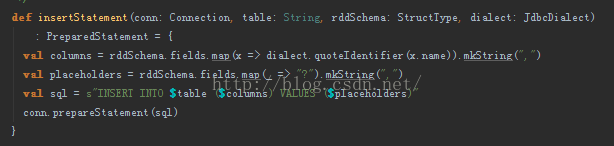
C. 若提前在数据库中手动创建表,需要注意列名称和数据类型,
下面的源码说明了,需要保证Spark SQL中schema中的field name与Mysql中的列名称一致!
若提前手动创建Mysql表,需要注意Spark SQL 中Schema中的数据类型与Mysql中的数据类型的对应关系,如下图所示:
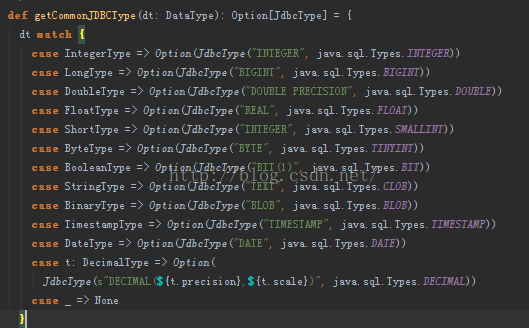
特别注意: Scala中的String类型,在MySQL中对应的是Text类型(经过亲自测试所知)
上面是本人在Spark SQL 读取与写入Mysql方面的遇到的一些坑,特在此备忘。

相关文章推荐
- Spark SQL将数据写入Mysql表的一些坑
- Spark SQL将数据写入Mysql表的一些坑
- Spark-SQL从MySQL中加载数据以及将数据写入到mysql中(Spark Shell方式,Spark SQL程序)
- python往mysql的blob字段写入二进制数据
- mysql没有oracle 那样一次性把data buffer 数据写入磁盘
- mysql 多线程写入后查询丢失数据的一个bug
- 如何从Mysqll读取数据写入csv文件
- mysql中避免大数据写入或者更新失败
- mysql中max_allowed_packet参数的配置方法(避免大数据写入或者更新失败)
- php从memcache读取数据再批量写入mysql的方法
- Hbase通过 Mapreduce 写入数据到Mysql
- PHP¥MYSQL注册登陆数据的一些处理
- Pandas写入数据到MySQL
- Mysql实现数据的不重复写入(insert if not exists)以及新问题:ID自增不连续的解答
- mysql一些基本数据查询
- 用python将excel数据写入mysql
- Oracle、PostgreSQL与Mysql数据写入性能对比
- Mysql 1秒200笔GPS数据批量写入优化
- Packet for query is too large(mysql写入数据过大)
- Mysql写入数据的错误,很容易忽视掉!