Scrapy框架学习(二)----Item Pipeline(管道)和Scrapy Shell
2017-11-29 20:24
736 查看
Scrapy框架学习(二)—-Item Pipeline(管道)和Scrapy Shell
Item Pipeline(管道)
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item进行处理。每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是Item Pipeline的典型应用:
验证爬取的数据(检查爬取的数据是否包含某些字段,数据清洗)
查重(重复的数据丢弃)
将爬取的结果保存到文件或数据库
编写Item Pipeline类
在pipelines.py文件中定义一个Pipeline类,同时必须实现下面的方法:
process_item(self,item,spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个Item对象,或是抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件处理。
代码如下:
import json
class BaiduPipeline(object):
def process_item(self, item, spider):
"""
处理item的方法,处理业务逻辑,保存数据,返回item
:param item: 是items.py中定义item类
:param spider: 是spiders目录中定义的Spider类
:return: 返回需要的item数据(经过清洗,业务逻辑处理后的item数据)
"""
print(spider) # 输出 <BaiDuSpider 'baidu' at 0x2133caee358>
print(type(spider)) # 输出 <class 'scrapydemo.spiders.baidu_spider.BaiDuSpider'>
print(spider.name) # 输出 baidu
print(item) # 输出 {'title': '百度一下'}
print(type(item)) # 输出 <class 'scrapydemo.items.BaiduItem'>
with open('baidu.json', 'w') as f:
jsondata = json.dumps(dict(item))
f.write(jsondata)
return itemPipeline 除此之外还可以实现以下方法:
open_spider(self, spider)
当spider被开启是调用该方法。
spider参数:被开启的spider对象
close_spider(self, spider)
当spider被关闭时,这个方法被调用
spider参数:被关闭的spider对象
在settings配置Item Pipeline
在
settings.py文件中,将
ITEM_PIPELINES,注释打开,将我们编写的Item Pipeline配置好。
ITEM_PIPELINES = {
# 我们写好的Pipeline的路径,300表示优先级,范围(0-1000),越小级别越高
'scrapydemo.pipelines.BaiduPipeline': 300,
}Scrapy Shell
Scrapy shell是一个交互终端,在未启动spider的情况下尝试及调试你的爬取代码。其本意是用来测试提取数据的代码。不过也可以将其当做正常的Python终端,在上面测试任何的Python代码。该终端是用来测试XPath或CSS表达式,查看他们的工作方式及爬取的网页中提取的数据。该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。
启动终端
进入项目的根目录,执行下面的命令,启动shell,以
"http://www.baidu.com"为例,如下:
scrapy shell “http://www.baidu.com”
命令执行后,结果如下图:
在我们执行
scrapy shell url命令后,Scrapy终端根据下载页面会自动创建一些方便使用的对象和可用的快捷命令,如:
可用的对象:
crawler:当前的Crawler的对象
spider:处理URL的spider。
request:最近获取到的页面的Request对象。
response:包含最近获取到的页面的
Response对象。
scrapy:scrapy 模块 (包含 scrapy.Request, scrapy.Selector等)
settings:当前Scrapy项目的settings.py
可用的快捷命令:
shelp():打印可用对象及快捷命令的帮助列表
fetch(request_or_url):根据给定的
url或
request获取到一个
response,并更新相关的对象
view(response):在本机的浏览器打开给定的
response。会在
response的
body中添加一个
<base>tag,使得外部链接(例如图片及
css)能正常显示。
eg:
当我们执行
scrapy shell "http://www.baidu.com"命令时,通过response对象调用selector,在调用xpath()。输出xpath查询结果。
print(response.selector.xpath("//title"))
# 输出结果:[<Selector xpath='//title' data='<title>百度一下</title>'>]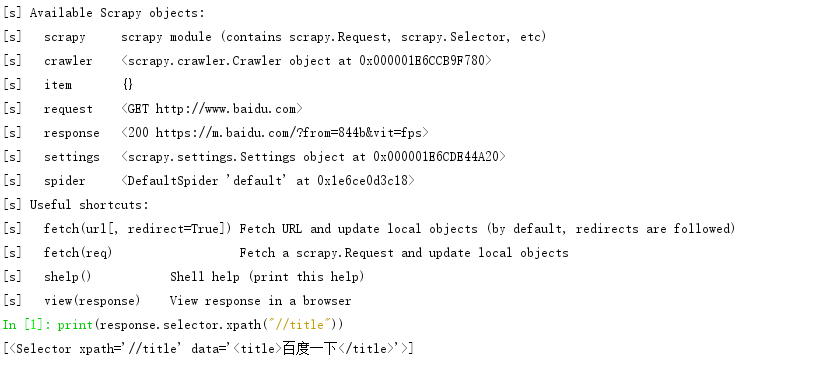
除此之外,我们也可以通过
response.selector.css()来解析响应的页面数据。
Scrapy还提供了快捷方式,如:
response.xpath(),
response.css()。
eg:
print(response.xpath("//title"))
# 输出结果:[<Selector xpath='//title' data='<title>百度一下</title>'>]Selector选择器
Scrapy Selector内置XPath和CSS Selector表达式机制
Selector有四个基本的方法,最常用的还XPath
xpath():传入
xpath表达式,返回该表达式所对应的所有节点的
Selector list列表。
ectract():序列化该节点为
Unicode字符串,并返回list。
css():传入
CSS表达式,返回该表达式所对应的所有节点的
selector list列表,语法同
BeautifulSoup4。
re():根据传入的正则表达式对数据进行提取,返回
Unicode字符串
list列表。
eg:
# 获取 title 标签的值
print(response.xpath("//title/text()")[0].extract())
# 输出: 百度一下

相关文章推荐
- Python:Scrapy框架中Item Pipeline组件(项目管道组件)的使用教程
- scrapy框架学习-爬取腾讯社招信息-item字段和管道文件
- Python爬虫框架Scrapy 学习笔记 7------- scrapy.Item源码剖析
- Scrapy框架学习 - 扩展内置的ImagesPipeline实现图片下载
- 爬虫框架Scrapy之Item Pipeline
- Scrapy学习篇(七)之Item Pipeline
- Scrapy-Item Pipeline(项目管道)
- Scrapy框架学习 - 使用内置的ImagesPipeline下载图片
- Python:Scrapy框架中Item Pipeline组件使用详解
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
- Scrapy 入门学习笔记(3) -- 使用 Item 类转换传输数据以及ItemLoader 机制解析
- python——爬虫学习——Scrapy爬虫框架入门-(6)
- sklearn官方文档学习笔记 管道和特征联合(Pipeline and FeatureUnion):组合估计器
- Scrapy爬虫框架学习笔 二 CrawlSpider的使用
- windows下scrapy框架学习笔记—'scrapy' 不是内部或外部命令
- Python:使用Scrapy框架的ImagesPipeline下载图片如何保持原图片名称呢?
- scrapy框架学习二-如何在eclips中配置scrapy开发环境
- Redis学习笔记7--Redis管道(pipeline)
- scrapy爬虫框架学习----安装scrapy