cs231n 笔记 --- 训练配置细节
2017-11-26 11:22
183 查看
cs231n Stanford
包含:交叉验证,梯度弥散与梯度爆炸,激活函数,数据预处理,权重初始化,Batch Normalization 。
交叉验证
一般将数据划分成训练集,验证集和测试集三部分。测试集只有在训练完成后才能动,用来评估模型的泛化能力。而验证集是用来选择最优超参数 ( 如:学习率,正则化系数等 ) ,即利用训练集,并以一系列的超参数组合配置模型,训练出多个模型,用验证集评估模型的好坏,选取最优模型对应的超参数组合用于后续的训练。但是这种方法不能充分利用验证集,因此就有了交叉验证。

交叉验证就是将训练数据 ( 训练集 + 验证集 ) 切分成 n 份,以 n-1 份作为训练集,剩下的 1 份作为验证集,然后对某组超参数配置进行训练,迭代而不重复地更换验证集,训练出 n 份结果,对这 n 份结果取平均,就得到这组超参数配置的训练结果。最后取平均值最好的那组超参数配置,对所有训练数据进行训练就行。
梯度弥散与梯度爆炸
反向传播时,某一权值的梯度一般等于:输入 * 激励导数 * 上一层梯度,并且根据 chain rule 多层间的梯度是要累乘的,小于 1 的数垒乘将趋于 0 ,大于 1 的数垒乘将趋于 ∞ 。因此 输入 * 激励导数 过大时会导致梯度很大,即梯度爆炸,网络无法收敛;输入 * 激励导数 过小时会导致梯度很小,即梯度弥散,网络收敛极慢或无法收敛。
激活函数
sigmoid
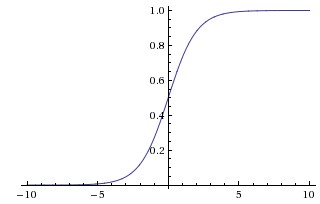
该激活函数有三个不好的特性:
当输入 x 过大或过小时 ( 曲线的左右两端 ) 梯度几乎等于 0 ,在反向传播时,由 chain rule 可知,反向传播的梯度也将等于 0 ,从而出现梯度弥散。
其输出不是 0 中心的,全大于 0 ,后面的神经元的输入将全为正数,那么其反向传播过程中,权重的梯度也将全为正数或全为负数。出现锯齿形步进式收敛,收敛速度慢。
exp() 的计算速度较慢。
tanh
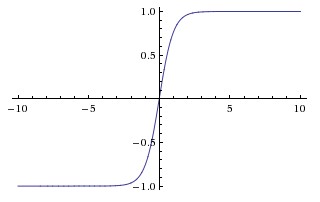
相对于 sigmoid 解决了输出不是 0 中心化的问题,不会出现锯齿形收敛问题。但其他问题仍然存在。
ReLu
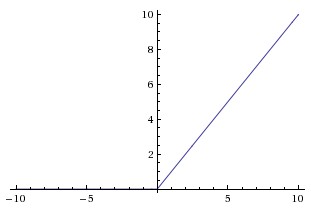
表达式:max(0, x) ,x 为输入。
特点:
不限制 x > 0 的梯度,但当 x < 0 时,梯度等于 0 ,即出现部分梯度弥散。
输出不是 0 中心化。
因为当 x < 0 时,梯度等于 0 ,所以可能出现对于某部分数据,ReLu 将不被激活,也就不再更新权重,即 Dead ReLu 问题。可以通过调低学习率,重新初始化,并把神经元的 bias 初始化为一个小的正值,如 0.01 。
Leaky ReLu
表达式:max(0.01*x, x) 。改善了 dead ReLu 问题。
Parame ReLu
表达式:max(α*x, x) 。α 可学习。
ELU Exp Linear Unit
表达式:max(α(exp(x)-1), x) 。接近 0 中心输出。
Maxout Neuron
表达式:max(WT1x+b1,WT2x+b2) 。一个神经元有两套权重。没有梯度弥散和 Dead ReLu ,但有两倍的参数量。
数据预处理
0 中心化
减去训练集求得的均值。AlexNet:减去平均 image ( [32, 32, 3] ) ;VGGNet:减去平均 channel ( [3] ) 。
标准化
减去均值后,除以标准差。图像中不常用。
PCA
PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。CodingLabs
图像处理中不常用
白化处理
举例来说,假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的。白化的目的就是降低输入的冗余性;更正式的说,我们希望通过白化过程使得学习算法的输入具有如下性质:(i)特征之间相关性较低;(ii)所有特征具有相同的方差。ufldl
权重初始化
初始化为 0
若所有权重都初始化为 0 ,那么所有的神经元的数值运算将完全一样。
初始化为小随机值
这种初始化对于较浅的网络 ( 2~3 层 ) 可以工作,但对于深层网络,其输出将趋于 0 ,从而导致梯度趋于 0 。
初始化为大的随机值
将导致 tanh 或 sigmoid 输出饱和,从而梯度也为 0 。
Xavier初始化
目的:使所有神经元的的输出近似同分布。
在使用 tanh 作为激励函数效果较好,方差下降较慢 ( 由于 tanh 的非线性变换,方差下降即输出趋于 0 ) 。但是使用 ReLu 时,方差下降较快 ( 由于 ReLu 截断负值输出,使输出标准差减半 ) ,初始化可修改为:
可以看出,我们希望神经元的输出接近高斯分布,才能让网络有效地学习。
Batch Normalization
作用:对输入的每个特征进行近似高斯化处理。

其中的 γ 和 β 都是可学习的,当学习到的 γ 和 β 分别为输入的方差和均值时,能抵消 BN 的作用。并且 BN 是可微的,能反向传播,可查看 BN 反向传播推导。在测试阶段,BN 中的均值和方差不再改变,可取训练时记录的平均,即能近似得到全部数据的均值和方差。
一般在 FC 或 CONV 与 激励函数之间插入 BN 层,形如 FC–BN–ReLu 或 Conv–BN–ReLu 。
BN能发挥的作用:
增加了梯度的流动,能同时解决梯度弥散和梯度爆炸问题
支持更高的学习率
对初始化要求小
能起到正则化的左右,可减少 Dropout 的使用 ( 可能是因为 BN 把 batch 中的样本融合了,能有效防止过拟合 )
包含:交叉验证,梯度弥散与梯度爆炸,激活函数,数据预处理,权重初始化,Batch Normalization 。
交叉验证
一般将数据划分成训练集,验证集和测试集三部分。测试集只有在训练完成后才能动,用来评估模型的泛化能力。而验证集是用来选择最优超参数 ( 如:学习率,正则化系数等 ) ,即利用训练集,并以一系列的超参数组合配置模型,训练出多个模型,用验证集评估模型的好坏,选取最优模型对应的超参数组合用于后续的训练。但是这种方法不能充分利用验证集,因此就有了交叉验证。
交叉验证就是将训练数据 ( 训练集 + 验证集 ) 切分成 n 份,以 n-1 份作为训练集,剩下的 1 份作为验证集,然后对某组超参数配置进行训练,迭代而不重复地更换验证集,训练出 n 份结果,对这 n 份结果取平均,就得到这组超参数配置的训练结果。最后取平均值最好的那组超参数配置,对所有训练数据进行训练就行。
梯度弥散与梯度爆炸
反向传播时,某一权值的梯度一般等于:输入 * 激励导数 * 上一层梯度,并且根据 chain rule 多层间的梯度是要累乘的,小于 1 的数垒乘将趋于 0 ,大于 1 的数垒乘将趋于 ∞ 。因此 输入 * 激励导数 过大时会导致梯度很大,即梯度爆炸,网络无法收敛;输入 * 激励导数 过小时会导致梯度很小,即梯度弥散,网络收敛极慢或无法收敛。
激活函数
sigmoid
该激活函数有三个不好的特性:
当输入 x 过大或过小时 ( 曲线的左右两端 ) 梯度几乎等于 0 ,在反向传播时,由 chain rule 可知,反向传播的梯度也将等于 0 ,从而出现梯度弥散。
其输出不是 0 中心的,全大于 0 ,后面的神经元的输入将全为正数,那么其反向传播过程中,权重的梯度也将全为正数或全为负数。出现锯齿形步进式收敛,收敛速度慢。
exp() 的计算速度较慢。
tanh
相对于 sigmoid 解决了输出不是 0 中心化的问题,不会出现锯齿形收敛问题。但其他问题仍然存在。
ReLu
表达式:max(0, x) ,x 为输入。
特点:
不限制 x > 0 的梯度,但当 x < 0 时,梯度等于 0 ,即出现部分梯度弥散。
输出不是 0 中心化。
因为当 x < 0 时,梯度等于 0 ,所以可能出现对于某部分数据,ReLu 将不被激活,也就不再更新权重,即 Dead ReLu 问题。可以通过调低学习率,重新初始化,并把神经元的 bias 初始化为一个小的正值,如 0.01 。
Leaky ReLu
表达式:max(0.01*x, x) 。改善了 dead ReLu 问题。
Parame ReLu
表达式:max(α*x, x) 。α 可学习。
ELU Exp Linear Unit
表达式:max(α(exp(x)-1), x) 。接近 0 中心输出。
Maxout Neuron
表达式:max(WT1x+b1,WT2x+b2) 。一个神经元有两套权重。没有梯度弥散和 Dead ReLu ,但有两倍的参数量。
数据预处理
0 中心化
减去训练集求得的均值。AlexNet:减去平均 image ( [32, 32, 3] ) ;VGGNet:减去平均 channel ( [3] ) 。
标准化
减去均值后,除以标准差。图像中不常用。
PCA
PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。CodingLabs
图像处理中不常用
白化处理
举例来说,假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的。白化的目的就是降低输入的冗余性;更正式的说,我们希望通过白化过程使得学习算法的输入具有如下性质:(i)特征之间相关性较低;(ii)所有特征具有相同的方差。ufldl
权重初始化
初始化为 0
若所有权重都初始化为 0 ,那么所有的神经元的数值运算将完全一样。
初始化为小随机值
W = 0.01 * np.random.randn()
这种初始化对于较浅的网络 ( 2~3 层 ) 可以工作,但对于深层网络,其输出将趋于 0 ,从而导致梯度趋于 0 。
初始化为大的随机值
W = 1 * np.random.randn()
将导致 tanh 或 sigmoid 输出饱和,从而梯度也为 0 。
Xavier初始化
目的:使所有神经元的的输出近似同分布。
w = np.random.randn(n) / sqrt(n) # n is the shape of input
在使用 tanh 作为激励函数效果较好,方差下降较慢 ( 由于 tanh 的非线性变换,方差下降即输出趋于 0 ) 。但是使用 ReLu 时,方差下降较快 ( 由于 ReLu 截断负值输出,使输出标准差减半 ) ,初始化可修改为:
w = np.random.randn(n) * sqrt(2.0/n)
可以看出,我们希望神经元的输出接近高斯分布,才能让网络有效地学习。
Batch Normalization
作用:对输入的每个特征进行近似高斯化处理。
其中的 γ 和 β 都是可学习的,当学习到的 γ 和 β 分别为输入的方差和均值时,能抵消 BN 的作用。并且 BN 是可微的,能反向传播,可查看 BN 反向传播推导。在测试阶段,BN 中的均值和方差不再改变,可取训练时记录的平均,即能近似得到全部数据的均值和方差。
一般在 FC 或 CONV 与 激励函数之间插入 BN 层,形如 FC–BN–ReLu 或 Conv–BN–ReLu 。
BN能发挥的作用:
增加了梯度的流动,能同时解决梯度弥散和梯度爆炸问题
支持更高的学习率
对初始化要求小
能起到正则化的左右,可减少 Dropout 的使用 ( 可能是因为 BN 把 batch 中的样本融合了,能有效防止过拟合 )

相关文章推荐
- springMVC笔记系列(18)——配置文件细节详解
- 4.Spring学习笔记_属性配置细节(by尚硅谷_佟刚)
- 语义分割学习笔记(一)——SegNet 配置与训练
- CS231n课程笔记6.2:神经网络训练技巧之Ensemble、Dropout
- Spring学习笔记之属性配置细节
- 【深度学习】笔记15 微软官方源码caffe的第一个测例Mnist训练运行配置
- [原创]java WEB学习笔记98:Spring学习---Spring Bean配置及相关细节:如何在配置bean,Spring容器(BeanFactory,ApplicationContext),如何获取bean,属性赋值(属性注入,构造器注入),配置bean细节(字面值,包含特殊字符,引用bean,null值,集合属性list map propert),util 和p 命名空间
- Qt 中的配置文件Pro细节笔记
- spring学习笔记(3)——bean配置细节注意
- Spring 学习笔记 4. 尚硅谷_佟刚_Spring_属性配置细节
- Spring4 学习笔记(4)-Spring 属性配置的一些细节
- 王小草【深度学习】笔记第三弹--神经网络细节与训练注意点
- caffe window的安装配置训练的一些笔记
- 读 说话办事细节训练 笔记
- SpringMVC 4.2.2 - Web.xml,Dispatcher-Servlet及ApplicationContext配置笔记
- 2018-07-04笔记(LNMP配置)
- RTSP服务器配置细节注意(持续更新)
- Gvim开发环境配置笔记--Windows篇
- 笔记之Spring的java配置方式
- RedHat 学习笔记 基于ssl的httpd服务配置 (openssl创建CA)