Android逆向之旅---解析编译之后的Dex文件格式
2017-11-24 14:27
567 查看
转自:http://blog.csdn.net/jiangwei0910410003/article/details/50668549
新的一年又开始了,大家是否还记得去年年末的时候,我们还有一件事没有做,那就是解析Android中编译之后的classes.dex文件格式,我们在去年的时候已经介绍了:
如何解析编译之后的xml文件格式:
http://blog.csdn.net/jiangwei0910410003/article/details/50568487
如何解析编译之后的resource.arsc文件格式:
http://blog.csdn.net/jiangwei0910410003/article/details/50628894
那么我们还剩下一个文件格式就是classes.dex了,那么今天我们就来看看最后一个文件格式解析,关于Android中的dex文件的相关知识这里就不做太多的解释了,网上有很多资料可以参考,而且,我们在之前介绍的一篇加固apk的那篇文章中也介绍了一点dex的格式知识点:http://blog.csdn.net/jiangwei0910410003/article/details/48415225,我们按照之前的解析思路来,首先还是来一张神图(非虫大大的杰作):

有了这张神图,那么接下来我们就可以来介绍dex的文件结构了,首先还是来看一张大体的结构图:

我们在讲解数据结构之前,我们需要先创建一个简单的例子来帮助我们来解析,我们需要得到一个简单的dex文件,这里我们不借助任何的IDE工具,就可以构造一个dex文件出来。借助的工具很简单:javac,dx命令即可。
创建 java 源文件 ,内容如下
代码:
public class Hello
{
public static void main(String[] argc)
{
System.out.println("Hello, Android!\n");
}
}
在当前工作路径下 , 编译方法如下 :
(1) 编译成 java class 文件
执行命令 : javac Hello.java
编译完成后 ,目录下生成 Hello.class 文件 。可以使用命令 java Hello 来测试下 ,会输出代码中的 “Hello, Android!” 的字符串 。
(2) 编译成 dex 文件
编译工具在 Android SDK 的路径如下 ,其中 19.0.1 是Android SDK build_tools 的版本 ,请按照在本地安装的 build_tools 版本来 。建议该路径加载到 PATH 路径下 ,否则引用 dx 工具时需要使用绝对路径 :./build-tools/19.0.1/dx
执行命令 : dx --dex --output=Hello.dex Hello.class
编译正常会生成 Hello.dex 文件 。
3. 使用 ADB 运行测试
测试命令和输出结果如下 :
$ adb root
$ adb push Hello.dex /sdcard/
$ adb shell
root@maguro:/ # dalvikvm -cp /sdcard/Hello.dex Hello
Hello, Android!
4. 重要说明
(1) 测试环境使用真机和 Android 虚拟机都可以的 。核心的命令是
dalvikvm -cp /sdcard/Hello.dex Hello
-cp 是 class path 的缩写 ,后面的 Hello 是要运行的 Class 的名称 。网上有描述说输入 dalvikvm --help
可以看到 dalvikvm 的帮助文档 ,但是在 Android4.4 的官方模拟器和自己的手机上测试都提示找不到
Class 路径 ,在Android 老的版本 ( 4.3 ) 上测试还是有输出的 。
(2) 因为命令在执行时 , dalvikvm 会在 /data/dalvik-cache/ 目录下创建 .dex 文件 ,因此要求 ADB 的
执行 Shell 对目录 /data/dalvik-cache/ 有读、写和执行的权限 ,否则无法达到预期效果 。
下面我们按照这张大体的思路图来一一讲解各个数据结构
dex文件里的header。除了描述.dex文件的文件信息外,还有文件里其它各个区域的索引。header对应成结构体类型,逻辑上的描述我用结构体header_item来理解它。先给出结构体里面用到的数据类型ubyte和uint的解释,然后再是结构体的描述,后面对各种结构描述的时候也是用的这种方法。
代码定义:
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class HeaderType {
/**
* struct header_item
{
ubyte[8] magic;
unit checksum;
ubyte[20] siganature;
uint file_size;
uint header_size;
unit endian_tag;
uint link_size;
uint link_off;
uint map_off;
uint string_ids_size;
uint string_ids_off;
uint type_ids_size;
uint type_ids_off;
uint proto_ids_size;
uint proto_ids_off;
uint method_ids_size;
uint method_ids_off;
uint class_defs_size;
uint class_defs_off;
uint data_size;
uint data_off;
}
*/
public byte[] magic = new byte[8];
public int checksum;
public byte[] siganature = new byte[20];
public int file_size;
public int header_size;
public int endian_tag;
public int link_size;
public int link_off;
public int map_off;
public int string_ids_size;
public int string_ids_off;
public int type_ids_size;
public int type_ids_off;
public int proto_ids_size;
public int proto_ids_off;
public int field_ids_size;
public int field_ids_off;
public int method_ids_size;
public int method_ids_off;
public int class_defs_size;
public int class_defs_off;
public int data_size;
public int data_off;
@Override
public String toString(){
return "magic:"+Utils.bytesToHexString(magic)+"\n"
+ "checksum:"+checksum + "\n"
+ "siganature:"+Utils.bytesToHexString(siganature) + "\n"
+ "file_size:"+file_size + "\n"
+ "header_size:"+header_size + "\n"
+ "endian_tag:"+endian_tag + "\n"
+ "link_size:"+link_size + "\n"
+ "link_off:"+Utils.bytesToHexString(Utils.int2Byte(link_off)) + "\n"
+ "map_off:"+Utils.bytesToHexString(Utils.int2Byte(map_off)) + "\n"
+ "string_ids_size:"+string_ids_size + "\n"
+ "string_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(string_ids_off)) + "\n"
+ "type_ids_size:"+type_ids_size + "\n"
+ "type_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(type_ids_off)) + "\n"
+ "proto_ids_size:"+proto_ids_size + "\n"
+ "proto_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(proto_ids_off)) + "\n"
+ "field_ids_size:"+field_ids_size + "\n"
+ "field_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(field_ids_off)) + "\n"
+ "method_ids_size:"+method_ids_size + "\n"
+ "method_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(method_ids_off)) + "\n"
+ "class_defs_size:"+class_defs_size + "\n"
+ "class_defs_off:"+Utils.bytesToHexString(Utils.int2Byte(class_defs_off)) + "\n"
+ "data_size:"+data_size + "\n"
+ "data_off:"+Utils.bytesToHexString(Utils.int2Byte(data_off));
}
}
查看Hex如下:

我们用一张图来描述各个字段的长度:

里面一对一对以_size和_off为后缀的描述:data_size是以Byte为单位描述data区的大小,其余的
_size都是描述该区里元素的个数;_off描述相对与文件起始位置的偏移量。其余的6个是描述.dex文件信
息的,各项说明如下:
(1) magic value
这 8 个 字节一般是常量 ,为了使 .dex 文件能够被识别出来 ,它必须出现在 .dex 文件的最开头的
位置 。数组的值可以转换为一个字符串如下 :
{ 0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00 } = "dex\n035\0"
中间是一个 ‘\n' 符号 ,后面 035 是 Dex 文件格式的版本 。
(2) checksum 和 signature
文件校验码 ,使用alder32 算法校验文件除去 maigc ,checksum 外余下的所有文件区域 ,用于检
查文件错误 。
signature , 使用 SHA-1 算法 hash 除去 magic ,checksum 和 signature 外余下的所有文件区域 ,
用于唯一识别本文件 。
(3) file_size
Dex 文件的大小 。
(4) header_size
header 区域的大小 ,单位 Byte ,一般固定为 0x70 常量 。
(5) endian_tag
大小端标签 ,标准 .dex 文件格式为 小端 ,此项一般固定为 0x1234 5678 常量 。
(6) link_size和link_off
这个两个字段是表示链接数据的大小和偏移值
(7) map_off
map item 的偏移地址 ,该 item 属于 data 区里的内容 ,值要大于等于 data_off 的大小 。结构如
map_list 描述 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class MapList {
/**
* struct maplist
{
uint size;
map_item list [size];
}
*/
public int size;
public List<MapItem> map_item = new ArrayList<MapItem>();
}
定义位置 : data区
引用位置 :header 区 。
map_list 里先用一个 uint 描述后面有 size 个 map_item , 后续就是对应的 size 个 map_item 描述 。
map_item 结构有 4 个元素 : type 表示该 map_item 的类型 ,本节能用到的描述如下 ,详细Dalvik
Executable Format 里 Type Code 的定义 ;size 表示再细分此 item , 该类型的个数 ;offset 是第一个元
素的针对文件初始位置的偏移量 ; unuse 是用对齐字节的 ,无实际用处 。结构定义如下:
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
public class MapItem {
/**
* struct map_item
{
ushort type;
ushort unuse;
uint size;
uint offset;
}
*/
public short type;
public short unuse;
public int size;
public int offset;
public static int getSize(){
return 2 + 2 + 4 + 4;
}
@Override
public String toString(){
return "type:"+type+",unuse:"+unuse+",size:"+size+",offset:"+offset;
}
}
header->map_off = 0x0244 , 偏移为 0244 的位置值为 0x 000d 。
每个 map_item 描述占用 12 Byte , 整个 map_list 占用 12 * size + 4 个字节 。所以整个 map_list 占用空
间为 12 * 13 + 4 = 160 = 0x00a0 , 占用空间为 0x 0244 ~ 0x 02E3 。从文件内容上看 ,也是从 0x 0244
到文件结束的位置 。

地址 0x0244 的一个 uinit 的值为 0x0000 000d ,map_list - > size = 0x0d = 13 ,说明后续有 13 个
map_item 。根据 map_item 的结构描述在0x0248 ~ 0x02e3 里的值 ,整理出这段二进制所表示的 13 个
map_item 内容 ,汇成表格如下 :
map_list - > map_item 里的内容 ,有部分 item 跟 header 里面相应 item 的 offset 地址描述相同 。但
map_list 描述的更为全面些 ,又包括了 HEADER_ITEM , TYPE_LIST , STRING_DATA_ITEM 等 ,
最后还有它自己 TYPE_MAP_LIST 。
至此 , header 部分描述完毕 ,它包括描述 .dex 文件的信息 ,其余各索引区和 data 区的偏移信息 , 一个
map_list 结构 。map_list 里除了对索引区和数据区的偏移地址又一次描述 ,也有其它诸如 HEAD_ITEM ,
DEBUG_INFO_ITEM 等信息 。
(8) string_ids_size和string_ids_off
这两个字段表示dex中用到的所有的字符串内容的大小和偏移值,我们需要解析完这部分,然后用一个字符串池存起来,后面有其他的数据结构会用索引值来访问字符串,这个池子也是非常重要的。后面会详细介绍string_ids的数据结构
(9) type_ids_size和type_ids_off
这两个字段表示dex中的类型数据结构的大小和偏移值,比如类类型,基本类型等信息,后面会详细介绍type_ids的数据结构
(10) proto_ids_size和type_ids_off
这两个字段表示dex中的元数据信息数据结构的大小和偏移值,描述方法的元数据信息,比如方法的返回类型,参数类型等信息,后面会详细介绍proto_ids的数据结构
(11) field_ids_size和field_ids_off
这两个字段表示dex中的字段信息数据结构的大小和偏移值,后面会详细介绍field_ids的数据结构
(12) method_ids_size和method_ids_off
这两个字段表示dex中的方法信息数据结构的大小和偏移值,后面会详细介绍method_ids的数据结构
(13) class_defs_size和class_defs_off
这两个字段表示dex中的类信息数据结构的大小和偏移值,这个数据结构是整个dex中最复杂的数据结构,他内部层次很深,包含了很多其他的数据结构,所以解析起来也很麻烦,所以后面会着重讲解这个数据结构
(14) data_size和data_off
这两个字段表示dex中数据区域的结构信息的大小和偏移值,这个结构中存放的是数据区域,比如我们定义的常量值等信息。
到这里我们就看完了dex的头部信息,头部包含的信息还是很多的,主要就两个个部分:
1) 魔数+签名+文件大小等信息
2) 后面的各个数据结构的大小和偏移值,都是成对出现的
下面我们就来开始介绍各个数据结构的信息
string_ids 区索引了 .dex 文件所有的字符串 。 本区里的元素格式为 string_ids_item , 可以使用结
构体如下描述 。
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class StringIdsItem {
/**
* struct string_ids_item
{
uint string_data_off;
}
*/
public int string_data_off;
public static int getSize(){
return 4;
}
@Override
public String toString(){
return Utils.bytesToHexString(Utils.int2Byte(string_data_off));
}
}
以 _ids 结尾的各个 section 里放置的都是对应数据的偏移地址 ,只是一个索引 ,所以才会在 dex文件布局里把这些区归类为 “索引区” 。
string_data_off 只是一个偏移地址 ,它指向的数据结构为 string_data_item
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class StringDataItem {
/**
* struct string_data_item
{
uleb128 utf16_size;
ubyte data;
}
*/
/**
* 上述描述里提到了 LEB128 ( little endian base 128 ) 格式 ,是基于 1 个 Byte 的一种不定长度的
编码方式 。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高
位为 0 。每个 Byte 的其余 Bit 用来表示数据
*/
public List<Byte> utf16_size = new ArrayList<Byte>();
public byte data;
}
延展
上述描述里提到了 LEB128 ( little endian base 128 ) 格式 ,是基于 1 个 Byte 的一种不定长度的编码方式 。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高位为 0 。每个 Byte 的其余 Bit 用来表示数据 。这里既然介绍了uleb128这种数据类型,就在这里解释一下,因为后面会经常用到这个数据类型,这个数据类型的出现其实就是为了解决一个问题,那就是减少内存的浪费,他就是表示int类型的数值,但是int类型四个字节有时候在使用的时候有点浪费,所以就应运而生了,他的原理也很简单:

图只是指示性的用两个字节表示。编码的每个字节有效部分只有低7bits,每个字节的最高bit用来指示是否是最后一个字节。
非最高字节的bit7为0
最高字节的bit7为1
将leb128编码的数字转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
比如:
LEB128编码的0x02b0 ---> 转换后的数字0x0130
转换过程:
0x02b0 => 0000 0010 1011 0000 =>去除最高位=> 000 0010 011 0000 =>按4bits重排 => 00 0001 0011 0000 => 0x130
底层代码位于:android/dalvik/libdex/leb128.h
Java中也写了一个工具类:
[java] view
plain copy
/**
* 读取C语言中的uleb类型
* 目的是解决整型数值浪费问题
* 长度不固定,在1~5个字节中浮动
* @param srcByte
* @param offset
* @return
*/
public static byte[] readUnsignedLeb128(byte[] srcByte, int offset){
List<Byte> byteAryList = new ArrayList<Byte>();
byte bytes = Utils.copyByte(srcByte, offset, 1)[0];
byte highBit = (byte)(bytes & 0x80);
byteAryList.add(bytes);
offset ++;
while(highBit != 0){
bytes = Utils.copyByte(srcByte, offset, 1)[0];
highBit = (byte)(bytes & 0x80);
offset ++;
byteAryList.add(bytes);
}
byte[] byteAry = new byte[byteAryList.size()];
for(int j=0;j<byteAryList.size();j++){
byteAry[j] = byteAryList.get(j);
}
return byteAry;
}
这个方法是读取dex中uleb128类型的数据,遇到一个字节最高位=0就停止读下个字节的原理来实现即可
还有一个方法就是解码uleb128类型的数据:
[java] view
plain copy
/**
* 解码leb128数据
* 每个字节去除最高位,然后进行拼接,重新构造一个int类型数值,从低位开始
* @param byteAry
* @return
*/
public static int decodeUleb128(byte[] byteAry) {
int index = 0, cur;
int result = byteAry[index];
index++;
if(byteAry.length == 1){
return result;
}
if(byteAry.length == 2){
cur = byteAry[index];
index++;
result = (result & 0x7f) | ((cur & 0x7f) << 7);
return result;
}
if(byteAry.length == 3){
cur = byteAry[index];
index++;
result |= (cur & 0x7f) << 14;
return result;
}
if(byteAry.length == 4){
cur = byteAry[index];
index++;
result |= (cur & 0x7f) << 21;
return result;
}
if(byteAry.length == 5){
cur = byteAry[index];
index++;
result |= cur << 28;
return result;
}
return result;
}
这个原理很简单,就是去除每个字节的最高位,然后拼接剩下的7位,然后从新构造一个int类型的数据,位不够就从低位开始左移。
我们通过上面的uleb128的解释来看,其实uleb128类型就是1~5个字节来回浮动,为什么是5呢?因为他要表示一个4个字节的int类型,但是每个字节要去除最高位,那么肯定最多只需要5个字节就可以表示4个字节的int类型数据了。这里就解释了uleb128数据类型,下面我们回归正题,继续来看string_ids数据结构
根据 string_ids_item 和 string_data_item 的描述 ,加上 header 里提供的入口位置 string_ids_size
= 0x0e , string_ids_off = 0x70 ,我们可以整理出 string_ids 及其对应的数据如下 :

string_ids_item 和 string_data_item 里提取出的对应数据表格 :
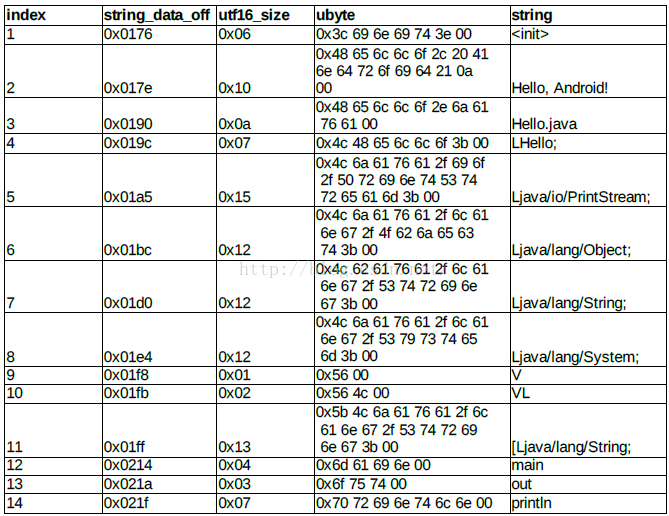
string 里的各种标志符号 ,诸如 L , V , VL , [ 等在 .dex 文件里有特殊的意思 。
string_ids 的终极奥义就是找到这些字符串 。其实使用二进制编辑器打开 .dex 文件时 ,一般工具默认翻译成 ASCII 码 ,总会一大片熟悉的字符白生生地很是亲切, 也很是晃眼 。刚才走过的一路子分析流程 ,就是顺藤摸瓜找到它们是怎么来的。以后的一些 type-ids , method_ids 也会引用到这一片熟悉的字符串。
注意:我们后面的解析代码会看到,其实我们没必要用那么复杂的去解析uleb128类型,因为我们会看到这个字符串和我们之前解析xml和resource.arsc格式一样,每个字符串的第一个字节表示字符串的长度,那么我们只要知道每个字符串的偏移地址就可以解析出字符串的内容了,而每个字符串的偏移地址是存放在string_ids_item中的。
到这里我们就解析完了dex中所有的字符串内容,我们用一个字符串池来进行存储即可。下面我们来继续看type_ids数据结构
这个数据结构中存放的数据主要是描述dex中所有的类型,比如类类型,基本类型等信息。type_ids 区索引了 dex 文件里的所有数据类型 ,包括 class 类型 ,数组类型(array types)和基本类型(primitive types) 。 本区域里的元素格式为 type_ids_item , 结构描述如下 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class TypeIdsItem {
/**
* struct type_ids_item
{
uint descriptor_idx;
}
*/
public int descriptor_idx;
public static int getSize(){
return 4;
}
@Override
public String toString(){
return Utils.bytesToHexString(Utils.int2Byte(descriptor_idx));
}
}
type_ids_item 里面 descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串 。
根据 header 里 type_ids_size = 0x07 , type_ids_off = 0xa8 , 找到对应的二进制描述区 。00000a0: 1a02

根据 type_id_item 的描述 ,整理出表格如下 。因为 type_id_item - > descriptor_idx 里存放的是指向 string_ids 的 index 号 ,所以我们也能得到该 type 的字符串描述 。这里出现了 3 个 type descriptor :
L 表示 class 的详细描述 ,一般以分号表示 class 描述结束 ;
V 表示 void 返回类型 ,只有在返回值的时候有效 ;
[ 表示数组 ,[Ljava/lang/String; 可以对应到 java 语言里的 java.lang.String[] 类型 。
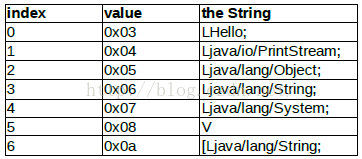
我们后面的其他数据结构也会使用到type_ids类型,所以我们这里解析完type_ids也是需要用一个池子来存放的,后面直接用索引index来访问即可。
proto 的意思是 method prototype 代表 java 语言里的一个 method 的原型 。proto_ids 里的元素为 proto_id_item , 结构如下 。
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class ProtoIdsItem {
/**
* struct proto_id_item
{
uint shorty_idx;
uint return_type_idx;
uint parameters_off;
}
*/
public int shorty_idx;
public int return_type_idx;
public int parameters_off;
//这个不是公共字段,而是为了存储方法原型中的参数类型名和参数个数
public List<String> parametersList = new ArrayList<String>();
public int parameterCount;
public static int getSize(){
return 4 + 4 + 4;
}
@Override
public String toString(){
return "shorty_idx:"+shorty_idx+",return_type_idx:"+return_type_idx+",parameters_off:"+parameters_off;
}
}
shorty_idx :跟 type_ids 一样 ,它的值是一个 string_ids 的 index 号 ,最终是一个简短的字符串描述 ,用来说明该 method 原型
return_type_idx :它的值是一个 type_ids 的 index 号 ,表示该 method 原型的返回值类型 。
parameters_off :后缀 off 是 offset , 指向 method 原型的参数列表 type_list ; 若 method 没有参数 ,值为0 。参数列表的格式是 type_list ,结构从逻辑上如下描述 。size 表示参数的个数 ;type_idx 是对应参数的类型 ,它的值是一个 type_ids 的 index 号 ,跟 return_type_idx 是同一个品种的东西 。
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class TypeList {
/**
* struct type_list
{
uint size;
ushort type_idx[size];
}
*/
public int size;//参数的个数
public List<Short> type_idx = new ArrayList<Short>();//参数的类型
}
header 里 proto_ids_size = 0x03 , proto_ids_off = 0xc4 , 它的二进制描述区如下 :

根据 proto_id_item 和 type_list 的格式 ,对照这它们的二进制部分 ,整理出表格如下 :

可以看出 ,有 3 个 method 原型 ,返回值都为 void ,index = 0 的没有参数传入 ,index = 1 的传入一个
String 参数 ,index=2 的传入一个 String[] 类型的参数 。
注意:我们在这里会看到很多idx结尾的字段,这个一般都是索引值,所以我们要注意的是,区分这个索引值到底是对应的哪张表格,是字符串池,还是类型池等信息,这个如果弄混淆的话,那么解析就会出现混乱了。这个后面其他数据结构都是需要注意的。
filed_ids 区里面存放的是dex 文件引用的所有的 field 。本区的元素格式是 field_id_item ,逻辑结构描述如
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
public class FieldIdsItem {
/**
* struct filed_id_item
{
ushort class_idx;
ushort type_idx;
uint name_idx;
}
*/
public short class_idx;
public short type_idx;
public int name_idx;
public static int getSize(){
return 2 + 2 + 4;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",type_idx:"+type_idx+",name_idx:"+name_idx;
}
}
class_idx :表示本 field 所属的 class 类型 , class_idx 的值是 type_ids 的一个 index , 并且必须指向一个class 类型 。
type_idx :表示本 field 的类型 ,它的值也是 type_ids 的一个 index 。
name_idx : 表示本 field 的名称 ,它的值是 string_ids 的一个 index 。
header 里 field_ids_size = 1 , field_ids_off = 0xe8 。说明本 .dex 只有一个 field ,这部分的二进制描述如下 :

注意:这里的字段都是索引值,一定要区分是哪个池子的索引值,还有就是,这个数据结构我们后面也要使用到,所以需要用一个池子来存储。
method_ids 是索引区的最后一个条目 ,它索引了 dex 文件里的所有的 method.
method_ids 的元素格式是 method_id_item , 结构跟 fields_ids 很相似:
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
public class MethodIdsItem {
/**
* struct filed_id_item
{
ushort class_idx;
ushort proto_idx;
uint name_idx;
}
*/
public short class_idx;
public short proto_idx;
public int name_idx;
public static int getSize(){
return 2 + 2 + 4;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",proto_idx:"+proto_idx+",name_idx:"+name_idx;
}
}
class_idx :表示本 method 所属的 class 类型 , class_idx 的值是 type_ids 的一个 index , 并且必须指向一个 class 类型 。
name_idx :表示本 method 的名称 ,它的值是 string_ids 的一个 index 。
proto_idx :描述该 method 的原型 ,指向 proto_ids 的一个 index 。
header 里 method_ids_size = 0x04 , method_ids_off = 0xf0 。本部分的二进制描述如下 :

对 dex 反汇编的时候 ,常用的 method 表示方法是这种形式 :
Lpackage/name/ObjectName;->MethodName(III)Z
将上述表格里的字符串再次整理下 ,method 的描述分别为 :
0:Lhello; -> <init>()V
1:LHello; -> main([Ljava/lang/String;)V
2:Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
3: Ljava/lang/Object; -> <init>()V
至此 ,索引区的内容描述完毕 ,包括 string_ids , type_ids,proto_ids , field_ids , method_ids 。每个索引区域里存放着指向具体数据的偏移地址 (如 string_ids ) , 或者存放的数据是其它索引区域里面的 index 号。
注意:这里的字段都是索引值,一定要区分是哪个池子的索引值,还有就是,这个数据结构我们后面也要使用到,所以需要用一个池子来存储。
上面我们介绍了所有的索引区域,终于到了最后一个数据结构了,但是我们现在还不能开心,因为这个数据结构是最复杂的,所以解析下来还是很费劲的。因为他的层次太深了。
1、class_def_item
从字面意思解释 ,class_defs 区域里存放着 class definitions , class 的定义 。它的结构较 dex 区都要复杂些 ,因为有些数据都直接指向了data 区里面 。
class_defs 的数据格式为 class_def_item , 结构描述如下 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
public class ClassDefItem {
/**
* struct class_def_item
{
uint class_idx;
uint access_flags;
uint superclass_idx;
uint interfaces_off;
uint source_file_idx;
uint annotations_off;
uint class_data_off;
uint static_value_off;
}
*/
public int class_idx;
public int access_flags;
public int superclass_idx;
public int iterfaces_off;
public int source_file_idx;
public int annotations_off;
public int class_data_off;
public int static_value_off;
public final static int
ACC_PUBLIC = 0x00000001, // class, field, method, ic
ACC_PRIVATE = 0x00000002, // field, method, ic
ACC_PROTECTED = 0x00000004, // field, method, ic
ACC_STATIC = 0x00000008, // field, method, ic
ACC_FINAL = 0x00000010, // class, field, method, ic
ACC_SYNCHRONIZED = 0x00000020, // method (only allowed on natives)
ACC_SUPER = 0x00000020, // class (not used in Dalvik)
ACC_VOLATILE = 0x00000040, // field
ACC_BRIDGE = 0x00000040, // method (1.5)
ACC_TRANSIENT = 0x00000080, // field
ACC_VARARGS = 0x00000080, // method (1.5)
ACC_NATIVE = 0x00000100, // method
ACC_INTERFACE = 0x00000200, // class, ic
ACC_ABSTRACT = 0x00000400, // class, method, ic
ACC_STRICT = 0x00000800, // method
ACC_SYNTHETIC = 0x00001000, // field, method, ic
ACC_ANNOTATION = 0x00002000, // class, ic (1.5)
ACC_ENUM = 0x00004000, // class, field, ic (1.5)
ACC_CONSTRUCTOR = 0x00010000, // method (Dalvik only)
ACC_DECLARED_SYNCHRONIZED = 0x00020000, // method (Dalvik only)
ACC_CLASS_MASK =
(ACC_PUBLIC | ACC_FINAL | ACC_INTERFACE | ACC_ABSTRACT
| ACC_SYNTHETIC | ACC_ANNOTATION | ACC_ENUM),
ACC_INNER_CLASS_MASK =
(ACC_CLASS_MASK | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC),
ACC_FIELD_MASK =
(ACC_PUBLIC | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC | ACC_FINAL
| ACC_VOLATILE | ACC_TRANSIENT | ACC_SYNTHETIC | ACC_ENUM),
ACC_METHOD_MASK =
(ACC_PUBLIC | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC | ACC_FINAL
| ACC_SYNCHRONIZED | ACC_BRIDGE | ACC_VARARGS | ACC_NATIVE
| ACC_ABSTRACT | ACC_STRICT | ACC_SYNTHETIC | ACC_CONSTRUCTOR
| ACC_DECLARED_SYNCHRONIZED);
public static int getSize(){
return 4 * 8;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",access_flags:"+access_flags+",superclass_idx:"+superclass_idx+",iterfaces_off:"+iterfaces_off
+",source_file_idx:"+source_file_idx+",annotations_off:"+annotations_off+",class_data_off:"+class_data_off
+",static_value_off:"+static_value_off;
}
}
(1) class_idx:描述具体的 class 类型 ,值是 type_ids 的一个 index 。值必须是一个 class 类型 ,不能是数组类型或者基本类型 。
(2) access_flags: 描述 class 的访问类型 ,诸如 public , final , static 等 。在 dex-format.html 里 “access_flagsDefinitions” 有具体的描述 。
(3) superclass_idx:描述 supperclass 的类型 ,值的形式跟 class_idx 一样 。
(4) interfaces_off:值为偏移地址 ,指向 class 的 interfaces , 被指向的数据结构为 type_list 。class 若没有interfaces ,值为 0。
(5) source_file_idx:表示源代码文件的信息 ,值是 string_ids 的一个 index 。若此项信息缺失 ,此项值赋值为NO_INDEX=0xffff ffff
(6) annotions_off:值是一个偏移地址 ,指向的内容是该 class 的注释 ,位置在 data 区,格式为annotations_direcotry_item 。若没有此项内容 ,值为 0 。
(7) class_data_off:值是一个偏移地址 ,指向的内容是该 class 的使用到的数据 ,位置在 data 区,格式为class_data_item 。若没有此项内容 ,值为 0 。该结构里有很多内容 ,详细描述该 class 的 field ,method, method 里的执行代码等信息 ,后面有一个比较大的篇幅来讲述 class_data_item 。
(8) static_value_off:值是一个偏移地址 ,指向 data 区里的一个列表 ( list ) ,格式为 encoded_array_item。若没有此项内容 ,值为 0 。
header 里 class_defs_size = 0x01 , class_defs_off = 0x 0110 。则此段二进制描述为 :

其实最初被编译的源码只有几行 ,和 class_def_item 的表格对照下 ,一目了然 。
source file : Hello.java
public class Hello
{
element value associated strinigs
class_idx 0x00 LHello;
access_flags 0x01 ACC_PUBLIC
superclass_idx 0x02 Ljava/lang/Object;
interface_off 0x00
source_file_idx 0x02 Hello.java
annotations_off 0x00
class_data_off 0x0234
static_value_off 0x00
public static void main(String[] argc)
{
System.out.println("Hello, Android!\n");
}
}
2、 class_def_item => class_data_item
class_data_off 指向 data 区里的 class_data_item 结构 ,class_data_item 里存放着本 class 使用到的各种数据 ,下面是 class_data_item 的逻辑结构 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
public class ClassDataItem {
/**
* uleb128 unsigned little-endian base 128
struct class_data_item
{
uleb128 static_fields_size;
uleb128 instance_fields_size;
uleb128 direct_methods_size;
uleb128 virtual_methods_size;
encoded_field static_fields [ static_fields_size ];
encoded_field instance_fields [ instance_fields_size ];
encoded_method direct_methods [ direct_method_size ];
encoded_method virtual_methods [ virtual_methods_size ];
}
*/
//uleb128只用来编码32位的整型数
public int static_fields_size;
public int instance_fields_size;
public int direct_methods_size;
public int virtual_methods_size;
public EncodedField[] static_fields;
public EncodedField[] instance_fields;
public EncodedMethod[] direct_methods;
public EncodedMethod[] virtual_methods;
@Override
public String toString(){
return "static_fields_size:"+static_fields_size+",instance_fields_size:"
+instance_fields_size+",direct_methods_size:"+direct_methods_size+",virtual_methods_size:"+virtual_methods_size
+"\n"+getFieldsAndMethods();
}
private String getFieldsAndMethods(){
StringBuilder sb = new StringBuilder();
sb.append("static_fields:\n");
for(int i=0;i<static_fields.length;i++){
sb.append(static_fields[i]+"\n");
}
sb.append("instance_fields:\n");
for(int i=0;i<instance_fields.length;i++){
sb.append(instance_fields[i]+"\n");
}
sb.append("direct_methods:\n");
for(int i=0;i<direct_methods.length;i++){
sb.append(direct_methods[i]+"\n");
}
sb.append("virtual_methods:\n");
for(int i=0;i<virtual_methods.length;i++){
sb.append(virtual_methods[i]+"\n");
}
return sb.toString();
}
}
关于元素的格式 uleb128 在 string_ids 里有讲述过 ,不赘述 。
encoded_field 的结构如下 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class EncodedField {
/**
* struct encoded_field
{
uleb128 filed_idx_diff; // index into filed_ids for ID of this filed
uleb128 access_flags; // access flags like public, static etc.
}
*/
public byte[] filed_idx_diff;
public byte[] access_flags;
@Override
public String toString(){
return "field_idx_diff:"+Utils.bytesToHexString(filed_idx_diff) + ",access_flags:"+Utils.bytesToHexString(filed_idx_diff);
}
}
encoded_method 的结构如下 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class EncodedMethod {
/**
* struct encoded_method
{
uleb128 method_idx_diff;
uleb128 access_flags;
uleb128 code_off;
}
*/
public byte[] method_idx_diff;
public byte[] access_flags;
public byte[] code_off;
@Override
public String toString(){
return "method_idx_diff:"+Utils.bytesToHexString(method_idx_diff)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(method_idx_diff)))
+",access_flags:"+Utils.bytesToHexString(access_flags)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(access_flags)))
+",code_off:"+Utils.bytesToHexString(code_off)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(code_off)));
}
}
(1) method_idx_diff:前缀 methd_idx 表示它的值是 method_ids 的一个 index ,后缀 _diff 表示它是于另外一个 method_idx 的一个差值 ,就是相对于 encodeed_method [] 数组里上一个元素的 method_idx 的差值 。其实 encoded_filed
- > field_idx_diff 表示的也是相同的意思 ,只是编译出来的 Hello.dex 文件里没有使用到class filed 所以没有仔细讲 ,详细的参考 dex_format.html 的官网文档
(2) access_flags:访问权限 , 比如 public、private、static、final 等 。
(3) code_off:一个指向 data 区的偏移地址 ,目标是本 method 的代码实现 。被指向的结构是
code_item ,有近 10 项元素 ,后面再详细解释 。
class_def_item -- > class_data_off = 0x 0234 。

名称为 LHello; 的 class 里只有 2 个 directive methods 。 directive_methods 里的值都是 uleb128 的原始二
进制值 。按照 directive_methods 的格式 encoded_method 再整理一次这 2 个 method 描述 ,得到结果如下
表格所描述 :

method 一个是 <init> , 一个是 main , 这里我们需要用我们在string_ids那块介绍到的一个方法就是解码uleb125类型的方法得到正确的value值。
3、class_def_item => class_data_item => code_item
到这里 ,逻辑的描述有点深入了 。我自己都有点分析不过来 ,先理一下是怎么走到这一步的 ,code_item
在 dex 里处于一个什么位置 。
(1) 一个 .dex 文件被分成了 9 个区 ,详细见 “1. dex 整个文件的布局 ” 。其中有一个索引区叫做
class_defs , 索引了 .dex 里面用到的 class ,以及对这个 class 的描述 。
(2) class_defs 区 , 这里面其实是class_def_item 结构 。这个结构里描述了 LHello; 的各种信息 ,诸如名称 ,superclass , access flag, interface 等 。class_def_item 里有一个元素 class_data_off , 指向data 区里的一个 class_data_item 结构 ,用来描述 class 使用到的各种数据 。自此以后的结构都归于 data区了 。
(3) class_data_item 结构 ,里描述值着 class 里使用到的 static field , instance field , direct_method ,和 virtual_method 的数目和描述 。例子 Hello.dex 里 ,只有 2 个 direct_method , 其余的 field 和method 的数目都为 0 。描述 direct_method 的结构叫做 encoded_method ,是用来详细描述某个 method的 。
(4) encoded_method 结构 ,描述某个 method 的 method 类型 , access flags 和一个指向 code_item的偏移地址 ,里面存放的是该 method 的具体实现 。
(5) code_item , 一层又一层 ,盗梦空间啊!简要的说 ,code_item 结构里描述着某个 method 的具体实现 。它的结构如下描述 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class CodeItem {
/**
* struct code_item
{
ushort registers_size;
ushort ins_size;
ushort outs_size;
ushort tries_size;
uint debug_info_off;
uint insns_size;
ushort insns [ insns_size ];
ushort paddding; // optional
try_item tries [ tyies_size ]; // optional
encoded_catch_handler_list handlers; // optional
}
*/
public short registers_size;
public short ins_size;
public short outs_size;
public short tries_size;
public int debug_info_off;
public int insns_size;
public short[] insns;
@Override
public String toString(){
return "regsize:"+registers_size+",ins_size:"+ins_size
+",outs_size:"+outs_size+",tries_size:"+tries_size+",debug_info_off:"+debug_info_off
+",insns_size:"+insns_size + "\ninsns:"+getInsnsStr();
}
private String getInsnsStr(){
StringBuilder sb = new StringBuilder();
for(int i=0;i<insns.length;i++){
sb.append(Utils.bytesToHexString(Utils.short2Byte(insns[i]))+",");
}
return sb.toString();
}
}
末尾的 3 项标志为 optional , 表示可能有 ,也可能没有 ,根据具体的代码来 。
(1) registers_size:本段代码使用到的寄存器数目。
(2) ins_size:method传入参数的数目 。
(3) outs_size: 本段代码调用其它method 时需要的参数个数 。
(4) tries_size: try_item 结构的个数 。
(5) debug_off:偏移地址 ,指向本段代码的 debug 信息存放位置 ,是一个 debug_info_item 结构。
(6) insns_size:指令列表的大小 ,以 16-bit 为单位 。 insns 是 instructions 的缩写 。
(7) padding:值为 0 ,用于对齐字节 。
(8) tries 和 handlers:用于处理 java 中的 exception , 常见的语法有 try catch 。
4、 分析 main method 的执行代码并与 smali 反编译的结果比较
在 8.2 节里有 2 个 method , 因为 main 里的执行代码是自己写的 ,分析它会熟悉很多 。偏移地址是
directive_method [1] -> code_off = 0x0148 ,二进制描述如下 :

insns 数组里的 8 个二进制原始数据 , 对这些数据的解析 ,需要对照官网的文档 《Dalvik VM Instruction
Format》和《Bytecode for Dalvik VM》。
分析思路整理如下
(1) 《Dalvik VM Instruction Format》 里操作符 op 都是位于首个 16bit 数据的低 8 bit ,起始的是 op =0x62。
(2) 在 《Bytecode for Dalvik VM》 里找到对应的 Syntax 和 format 。
syntax = sget_object
format = 0x21c 。
(3) 在《Dalvik VM Instruction Format》里查找 21c , 得知 op = 0x62 的指令占据 2 个 16 bit 数据 ,格式是 AA|op BBBB ,解释为 op vAA, type@BBBB 。因此这 8 组 16 bit 数据里 ,前 2 个是一组 。对比数据得 AA=0x00, BBBB = 0x0000。
(4)返回《Bytecode for Dalvik VM》里查阅对 sget_object 的解释, AA 的值表示 Value Register ,即0 号寄存器; BBBB 表示 static field 的 index ,就是之前分析的field_ids 区里 Index = 0 指向的那个东西 ,当时的 fields_ids 的分析结果如下 :

对 field 常用的表述是
包含 field 的类型 -> field 名称 :field 类型 。
此次指向的就是 Ljava/lang/System; -> out:Ljava/io/printStream;
(5) 综上 ,前 2 个 16 bit 数据 0x 0062 0000 , 解释为
sget_object v0, Ljava/lang/System; -> out:Ljava/io/printStream;
其余的 6 个 16 bit 数据分析思路跟这个一样 ,依次整理如下 :
0x011a 0x0001: const-string v1, “Hello, Android!”
0x206e 0x0002 0x0010:
invoke-virtual {v0, v1}, Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
0x000e: return-void
(6) 最后再整理下 main method , 用容易理解的方式表示出来就是 。
ACC_PUBLIC ACC_STATIC LHello;->main([Ljava/lang/String;)V
{
sget_object v0, Ljava/lang/System; -> out:Ljava/io/printStream;
const-string v1,Hello, Android!
invoke-virtual {v0, v1}, Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
return-void
}
看起来很像 smali 格式语言 ,不妨使用 smali 反编译下 Hello.dex , 看看 smali 生成的代码跟方才推导出
来的有什么差异 。
.method public static main([Ljava/lang/String;)V
.registers 3
.prologue
.line 5
sget-object v0, Ljava/lang/System;->out:Ljava/io/PrintStream;
const-string v1, "Hello, Android!\n"
index 0
class_idx 0x04
type_idx 0x01
name_idx 0x0c
class string Ljava/lang/System;
type string Ljava/io/PrintStream;
name string out
invoke-virtual {v0, v1}, Ljava/io/PrintStream;->println(Ljava/lang/String;)V
.line 6
return-void
从内容上看 ,二者形式上有些差异 ,但表述的是同一个 method 。这说明刚才的分析走的路子是没有跑偏
的 。另外一个 method 是 <init> , 若是分析的话 ,思路和流程跟 main 一样 。走到这里,心里很踏实了。
上面我们解析完了所有的数据结构区域,下面就来看看具体的解析代码,由于篇幅的原因,这里就不贴出全部的代码了,只贴出核心的代码:
[java] view
plain copy
public static void praseDexHeader(byte[] byteSrc){
HeaderType headerType = new HeaderType();
//解析魔数
byte[] magic = Utils.copyByte(byteSrc, 0, 8);
headerType.magic = magic;
//解析checksum
byte[] checksumByte = Utils.copyByte(byteSrc, 8, 4);
headerType.checksum = Utils.byte2int(checksumByte);
//解析siganature
byte[] siganature = Utils.copyByte(byteSrc, 12, 20);
headerType.siganature = siganature;
//解析file_size
byte[] fileSizeByte = Utils.copyByte(byteSrc, 32, 4);
headerType.file_size = Utils.byte2int(fileSizeByte);
//解析header_size
byte[] headerSizeByte = Utils.copyByte(byteSrc, 36, 4);
headerType.header_size = Utils.byte2int(headerSizeByte);
//解析endian_tag
byte[] endianTagByte = Utils.copyByte(byteSrc, 40, 4);
headerType.endian_tag = Utils.byte2int(endianTagByte);
//解析link_size
byte[] linkSizeByte = Utils.copyByte(byteSrc, 44, 4);
headerType.link_size = Utils.byte2int(linkSizeByte);
//解析link_off
byte[] linkOffByte = Utils.copyByte(byteSrc, 48, 4);
headerType.link_off = Utils.byte2int(linkOffByte);
//解析map_off
byte[] mapOffByte = Utils.copyByte(byteSrc, 52, 4);
headerType.map_off = Utils.byte2int(mapOffByte);
//解析string_ids_size
byte[] stringIdsSizeByte = Utils.copyByte(byteSrc, 56, 4);
headerType.string_ids_size = Utils.byte2int(stringIdsSizeByte);
//解析string_ids_off
byte[] stringIdsOffByte = Utils.copyByte(byteSrc, 60, 4);
headerType.string_ids_off = Utils.byte2int(stringIdsOffByte);
//解析type_ids_size
byte[] typeIdsSizeByte = Utils.copyByte(byteSrc, 64, 4);
headerType.type_ids_size = Utils.byte2int(typeIdsSizeByte);
//解析type_ids_off
byte[] typeIdsOffByte = Utils.copyByte(byteSrc, 68, 4);
headerType.type_ids_off = Utils.byte2int(typeIdsOffByte);
//解析proto_ids_size
byte[] protoIdsSizeByte = Utils.copyByte(byteSrc, 72, 4);
headerType.proto_ids_size = Utils.byte2int(protoIdsSizeByte);
//解析proto_ids_off
byte[] protoIdsOffByte = Utils.copyByte(byteSrc, 76, 4);
headerType.proto_ids_off = Utils.byte2int(protoIdsOffByte);
//解析field_ids_size
byte[] fieldIdsSizeByte = Utils.copyByte(byteSrc, 80, 4);
headerType.field_ids_size = Utils.byte2int(fieldIdsSizeByte);
//解析field_ids_off
byte[] fieldIdsOffByte = Utils.copyByte(byteSrc, 84, 4);
headerType.field_ids_off = Utils.byte2int(fieldIdsOffByte);
//解析method_ids_size
byte[] methodIdsSizeByte = Utils.copyByte(byteSrc, 88, 4);
headerType.method_ids_size = Utils.byte2int(methodIdsSizeByte);
//解析method_ids_off
byte[] methodIdsOffByte = Utils.copyByte(byteSrc, 92, 4);
headerType.method_ids_off = Utils.byte2int(methodIdsOffByte);
//解析class_defs_size
byte[] classDefsSizeByte = Utils.copyByte(byteSrc, 96, 4);
headerType.class_defs_size = Utils.byte2int(classDefsSizeByte);
//解析class_defs_off
byte[] classDefsOffByte = Utils.copyByte(byteSrc, 100, 4);
headerType.class_defs_off = Utils.byte2int(classDefsOffByte);
//解析data_size
byte[] dataSizeByte = Utils.copyByte(byteSrc, 104, 4);
headerType.data_size = Utils.byte2int(dataSizeByte);
//解析data_off
byte[] dataOffByte = Utils.copyByte(byteSrc, 108, 4);
headerType.data_off = Utils.byte2int(dataOffByte);
System.out.println("header:"+headerType);
stringIdOffset = headerType.header_size;//header之后就是string ids
stringIdsSize = headerType.string_ids_size;
stringIdsOffset = headerType.string_ids_off;
typeIdsSize = headerType.type_ids_size;
typeIdsOffset = headerType.type_ids_off;
fieldIdsSize = headerType.field_ids_size;
fieldIdsOffset = headerType.field_ids_off;
protoIdsSize = headerType.proto_ids_size;
protoIdsOffset = headerType.proto_ids_off;
methodIdsSize = headerType.method_ids_size;
methodIdsOffset = headerType.method_ids_off;
classIdsSize = headerType.class_defs_size;
classIdsOffset = headerType.class_defs_off;
mapListOffset = headerType.map_off;
}
这里没啥说的,就是记录几个索引区的偏移值和大小信息。
解析结果:

[java] view
plain copy
/************************解析字符串********************************/
public static void parseStringIds(byte[] srcByte){
int idSize = StringIdsItem.getSize();
int countIds = stringIdsSize;
for(int i=0;i<countIds;i++){
stringIdsList.add(parseStringIdsItem(Utils.copyByte(srcByte, stringIdsOffset+i*idSize, idSize)));
}
System.out.println("string size:"+stringIdsList.size());
}
public static void parseStringList(byte[] srcByte){
//第一个字节还是字符串的长度
for(StringIdsItem item : stringIdsList){
String str = getString(srcByte, item.string_data_off);
System.out.println("str:"+str);
stringList.add(str);
}
}
解析结果:

[java] view
plain copy
/***************************解析类型******************************/
public static void parseTypeIds(byte[] srcByte){
int idSize = TypeIdsItem.getSize();
int countIds = typeIdsSize;
for(int i=0;i<countIds;i++){
typeIdsList.add(parseTypeIdsItem(Utils.copyByte(srcByte, typeIdsOffset+i*idSize, idSize)));
}
//这里的descriptor_idx就是解析之后的字符串中的索引值
for(TypeIdsItem item : typeIdsList){
System.out.println("typeStr:"+stringList.get(item.descriptor_idx));
}
}
解析结果:

[html] view
plain copy
/***************************解析Proto***************************/
public static void parseProtoIds(byte[] srcByte){
int idSize = ProtoIdsItem.getSize();
int countIds = protoIdsSize;
for(int i=0;i<countIds;i++){
protoIdsList.add(parseProtoIdsItem(Utils.copyByte(srcByte, protoIdsOffset+i*idSize, idSize)));
}
for(ProtoIdsItem item : protoIdsList){
System.out.println("proto:"+stringList.get(item.shorty_idx)+","+stringList.get(item.return_type_idx));
//有的方法没有参数,这个值就是0
if(item.parameters_off != 0){
item = parseParameterTypeList(srcByte, item.parameters_off, item);
}
}
}
//解析方法的所有参数类型
private static ProtoIdsItem parseParameterTypeList(byte[] srcByte, int startOff, ProtoIdsItem item){
//解析size和size大小的List中的内容
byte[] sizeByte = Utils.copyByte(srcByte, startOff, 4);
int size = Utils.byte2int(sizeByte);
List<String> parametersList = new ArrayList<String>();
List<Short> typeList = new ArrayList<Short>(size);
for(int i=0;i<size;i++){
byte[] typeByte = Utils.copyByte(srcByte, startOff+4+2*i, 2);
typeList.add(Utils.byte2Short(typeByte));
}
System.out.println("param count:"+size);
for(int i=0;i<typeList.size();i++){
System.out.println("type:"+stringList.get(typeList.get(i)));
int index = typeIdsList.get(typeList.get(i)).descriptor_idx;
parametersList.add(stringList.get(index));
}
item.parameterCount = size;
item.parametersList = parametersList;
return item;
}
解析结果:

[java] view
plain copy
/***************************解析字段****************************/
public static void parseFieldIds(byte[] srcByte){
int idSize = FieldIdsItem.getSize();
int countIds = fieldIdsSize;
for(int i=0;i<countIds;i++){
fieldIdsList.add(parseFieldIdsItem(Utils.copyByte(srcByte, fieldIdsOffset+i*idSize, idSize)));
}
for(FieldIdsItem item : fieldIdsList){
int classIndex = typeIdsList.get(item.class_idx).descriptor_idx;
int typeIndex = typeIdsList.get(item.type_idx).descriptor_idx;
System.out.println("class:"+stringList.get(classIndex)+",name:"+stringList.get(item.name_idx)+",type:"+stringList.get(typeIndex));
}
}
解析结果:
[java] view
plain copy
/***************************解析方法*****************************/
public static void parseMethodIds(byte[] srcByte){
int idSize = MethodIdsItem.getSize();
int countIds = methodIdsSize;
for(int i=0;i<countIds;i++){
methodIdsList.add(parseMethodIdsItem(Utils.copyByte(srcByte, methodIdsOffset+i*idSize, idSize)));
}
for(MethodIdsItem item : methodIdsList){
int classIndex = typeIdsList.get(item.class_idx).descriptor_idx;
int returnIndex = protoIdsList.get(item.proto_idx).return_type_idx;
String returnTypeStr = stringList.get(typeIdsList.get(returnIndex).descriptor_idx);
int shortIndex = protoIdsList.get(item.proto_idx).shorty_idx;
String shortStr = stringList.get(shortIndex);
List<String> paramList = protoIdsList.get(item.proto_idx).parametersList;
StringBuilder parameters = new StringBuilder();
parameters.append(returnTypeStr+"(");
for(String str : paramList){
parameters.append(str+",");
}
parameters.append(")"+shortStr);
System.out.println("class:"+stringList.get(classIndex)+",name:"+stringList.get(item.name_idx)+",proto:"+parameters);
}
}

[java] view
plain copy
/****************************解析类*****************************/
public static void parseClassIds(byte[] srcByte){
System.out.println("classIdsOffset:"+Utils.bytesToHexString(Utils.int2Byte(classIdsOffset)));
System.out.println("classIds:"+classIdsSize);
int idSize = ClassDefItem.getSize();
int countIds = classIdsSize;
for(int i=0;i<countIds;i++){
classIdsList.add(parseClassDefItem(Utils.copyByte(srcByte, classIdsOffset+i*idSize, idSize)));
}
for(ClassDefItem item : classIdsList){
System.out.println("item:"+item);
int classIdx = item.class_idx;
TypeIdsItem typeItem = typeIdsList.get(classIdx);
System.out.println("classIdx:"+stringList.get(typeItem.descriptor_idx));
int superClassIdx = item.superclass_idx;
TypeIdsItem superTypeItem = typeIdsList.get(superClassIdx);
System.out.println("superitem:"+stringList.get(superTypeItem.descriptor_idx));
int sourceIdx = item.source_file_idx;
String sourceFile = stringList.get(sourceIdx);
System.out.println("sourceFile:"+sourceFile);
classDataMap.put(sourceFile, item);
}
}
解析结果:

这里我们看到解析结果我们可能有点看不懂,其实这里我是没有在继续解读下去了,为什么,因为我们通过class_def的数据结构解析可以看到,我们需要借助《Bytecode for Dalvik VM》这个来进行查阅具体的指令,然后翻译成具体的指令代码,关于这个指令表可以参考这里:http://www.netmite.com/android/mydroid/dalvik/docs/dalvik-bytecode.html,所以具体解析并不复杂,所以这里就不在详细解析了,具体的解析思路,可以参考class_def的数据结构解析那一块的内容,上面又说道。
项目下载地址:https://github.com/fourbrother/parse_androiddex
注意:
我们到这里算是解析完了dex文件了,但是我现在要告诉大家,其实Android中有一个工具可以为我们做这个事,不知道大家还记得我们之前介绍解析AndroidManifest.xml和resource.arsc文件格式的时候,也是一样的,直接用aapt命令就可以查看了,这里也是一样的,只是这个工具是:dexdump
这个命令也是在AndroidSdk目录下的build-tools下面,这里我们可以将打印的结果重定向到demo.txt文件中

那么我们上面做的解析工作是不是就没有用了呢?当然不是,我们在后面会说道我们解析dex格式有很多用途的。
到这里我们就解析完了dex文件的所有东东,讲解的内容有点多,在这里就来总结一下:
1、我们学习到了如何不是用任何的IDE工具,就可以构造一个dex文件出来,主要借助于java和dx命令。同时,我们也学会了一个可以执行dex文件的命令:dalvikvm;不过这个命令需要root权限。
2、我们了解到了Android中的DVM指令,如何翻译指令代码。
3、学习了一个数据类型:uleb128,如何将uleb128类型和int类型进行转化。
我们在整个解析的过程中会发现,我们这里只是用一个非常简单的dex来做案例解析,所以解析起来也很容易,但是我们实际的过程中,不会这么简单的,一个类可能实现多个接口,内部类,注解等信息的时候,解析起来肯定还要复杂,那么我们这篇文章主要的目的是介绍一下dex的文件格式,目的不是说去解决实际中项目的问题,所以后面在解析复杂的dex的时候,我们也只能遇到什么问题就去解决一下。
我们开始的时候,并没有介绍说解析dex干啥?那么现在可以说,解析完dex之后我们有很多事都可以做了。
1、我们可以检测一个apk中是否包含了指定系统的api(当然这些api没有被混淆),同样也可以检测这个apk是否包含了广告,以前我们可以通过解析AndroidManifest.xml文件中的service,activity,receiver,meta等信息来判断,因为现在的广告sdk都需要添加这些东西,如果我们可以解析dex的话,那么我们可以得到他的所有字符串内容,就是string_ids池,这样就可以判断调用了哪些api。那么就可以判断这个apk的一些行为了,当然这里还有一个问题,假如dex加密了我们就蛋疼了。好吧,那就牵涉出第二件事了。
2、我们在之前说过如何对apk进行加固,其实就是加密apk/dex文件内容,那么这时候我们必须要了解dex的文件结构信息,因为我们先加密dex,然后在动态加载dex进行解密即可。
3、我们可以更好的逆向工作,其实说到这里,我们看看apktool源码也知道,他内部的反编译原理就是这些,只是他会将指令翻译成smail代码,这个网上是有相对应的jar包api的,所以我们知道了dex的数据结构,那么原理肯定就知道了,同样还有一个dex2jar工具原理也是类似的。
到这里我们就介绍完了dex文件格式的解析工作,至此我们也解析完了Android中编译之后的所有文件格式,我之所以介绍这几篇文章,一来是更好的了解Android中生成apk的流程,其次是我们能更好的的解决反编译过程中遇到的问题,我们需要去解决。这篇文章解析起来还是很费劲的,累死了,也是2016年第一篇文章,谢谢大家的支持~~。记得点赞呀~~
一、前言
新的一年又开始了,大家是否还记得去年年末的时候,我们还有一件事没有做,那就是解析Android中编译之后的classes.dex文件格式,我们在去年的时候已经介绍了:如何解析编译之后的xml文件格式:
http://blog.csdn.net/jiangwei0910410003/article/details/50568487
如何解析编译之后的resource.arsc文件格式:
http://blog.csdn.net/jiangwei0910410003/article/details/50628894
那么我们还剩下一个文件格式就是classes.dex了,那么今天我们就来看看最后一个文件格式解析,关于Android中的dex文件的相关知识这里就不做太多的解释了,网上有很多资料可以参考,而且,我们在之前介绍的一篇加固apk的那篇文章中也介绍了一点dex的格式知识点:http://blog.csdn.net/jiangwei0910410003/article/details/48415225,我们按照之前的解析思路来,首先还是来一张神图(非虫大大的杰作):
有了这张神图,那么接下来我们就可以来介绍dex的文件结构了,首先还是来看一张大体的结构图:
二、准备工作
我们在讲解数据结构之前,我们需要先创建一个简单的例子来帮助我们来解析,我们需要得到一个简单的dex文件,这里我们不借助任何的IDE工具,就可以构造一个dex文件出来。借助的工具很简单:javac,dx命令即可。创建 java 源文件 ,内容如下
代码:
public class Hello
{
public static void main(String[] argc)
{
System.out.println("Hello, Android!\n");
}
}
在当前工作路径下 , 编译方法如下 :
(1) 编译成 java class 文件
执行命令 : javac Hello.java
编译完成后 ,目录下生成 Hello.class 文件 。可以使用命令 java Hello 来测试下 ,会输出代码中的 “Hello, Android!” 的字符串 。
(2) 编译成 dex 文件
编译工具在 Android SDK 的路径如下 ,其中 19.0.1 是Android SDK build_tools 的版本 ,请按照在本地安装的 build_tools 版本来 。建议该路径加载到 PATH 路径下 ,否则引用 dx 工具时需要使用绝对路径 :./build-tools/19.0.1/dx
执行命令 : dx --dex --output=Hello.dex Hello.class
编译正常会生成 Hello.dex 文件 。
3. 使用 ADB 运行测试
测试命令和输出结果如下 :
$ adb root
$ adb push Hello.dex /sdcard/
$ adb shell
root@maguro:/ # dalvikvm -cp /sdcard/Hello.dex Hello
Hello, Android!
4. 重要说明
(1) 测试环境使用真机和 Android 虚拟机都可以的 。核心的命令是
dalvikvm -cp /sdcard/Hello.dex Hello
-cp 是 class path 的缩写 ,后面的 Hello 是要运行的 Class 的名称 。网上有描述说输入 dalvikvm --help
可以看到 dalvikvm 的帮助文档 ,但是在 Android4.4 的官方模拟器和自己的手机上测试都提示找不到
Class 路径 ,在Android 老的版本 ( 4.3 ) 上测试还是有输出的 。
(2) 因为命令在执行时 , dalvikvm 会在 /data/dalvik-cache/ 目录下创建 .dex 文件 ,因此要求 ADB 的
执行 Shell 对目录 /data/dalvik-cache/ 有读、写和执行的权限 ,否则无法达到预期效果 。
三、讲解数据结构
下面我们按照这张大体的思路图来一一讲解各个数据结构
第一、头部信息Header结构
dex文件里的header。除了描述.dex文件的文件信息外,还有文件里其它各个区域的索引。header对应成结构体类型,逻辑上的描述我用结构体header_item来理解它。先给出结构体里面用到的数据类型ubyte和uint的解释,然后再是结构体的描述,后面对各种结构描述的时候也是用的这种方法。代码定义:
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class HeaderType {
/**
* struct header_item
{
ubyte[8] magic;
unit checksum;
ubyte[20] siganature;
uint file_size;
uint header_size;
unit endian_tag;
uint link_size;
uint link_off;
uint map_off;
uint string_ids_size;
uint string_ids_off;
uint type_ids_size;
uint type_ids_off;
uint proto_ids_size;
uint proto_ids_off;
uint method_ids_size;
uint method_ids_off;
uint class_defs_size;
uint class_defs_off;
uint data_size;
uint data_off;
}
*/
public byte[] magic = new byte[8];
public int checksum;
public byte[] siganature = new byte[20];
public int file_size;
public int header_size;
public int endian_tag;
public int link_size;
public int link_off;
public int map_off;
public int string_ids_size;
public int string_ids_off;
public int type_ids_size;
public int type_ids_off;
public int proto_ids_size;
public int proto_ids_off;
public int field_ids_size;
public int field_ids_off;
public int method_ids_size;
public int method_ids_off;
public int class_defs_size;
public int class_defs_off;
public int data_size;
public int data_off;
@Override
public String toString(){
return "magic:"+Utils.bytesToHexString(magic)+"\n"
+ "checksum:"+checksum + "\n"
+ "siganature:"+Utils.bytesToHexString(siganature) + "\n"
+ "file_size:"+file_size + "\n"
+ "header_size:"+header_size + "\n"
+ "endian_tag:"+endian_tag + "\n"
+ "link_size:"+link_size + "\n"
+ "link_off:"+Utils.bytesToHexString(Utils.int2Byte(link_off)) + "\n"
+ "map_off:"+Utils.bytesToHexString(Utils.int2Byte(map_off)) + "\n"
+ "string_ids_size:"+string_ids_size + "\n"
+ "string_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(string_ids_off)) + "\n"
+ "type_ids_size:"+type_ids_size + "\n"
+ "type_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(type_ids_off)) + "\n"
+ "proto_ids_size:"+proto_ids_size + "\n"
+ "proto_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(proto_ids_off)) + "\n"
+ "field_ids_size:"+field_ids_size + "\n"
+ "field_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(field_ids_off)) + "\n"
+ "method_ids_size:"+method_ids_size + "\n"
+ "method_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(method_ids_off)) + "\n"
+ "class_defs_size:"+class_defs_size + "\n"
+ "class_defs_off:"+Utils.bytesToHexString(Utils.int2Byte(class_defs_off)) + "\n"
+ "data_size:"+data_size + "\n"
+ "data_off:"+Utils.bytesToHexString(Utils.int2Byte(data_off));
}
}
查看Hex如下:
我们用一张图来描述各个字段的长度:
里面一对一对以_size和_off为后缀的描述:data_size是以Byte为单位描述data区的大小,其余的
_size都是描述该区里元素的个数;_off描述相对与文件起始位置的偏移量。其余的6个是描述.dex文件信
息的,各项说明如下:
(1) magic value
这 8 个 字节一般是常量 ,为了使 .dex 文件能够被识别出来 ,它必须出现在 .dex 文件的最开头的
位置 。数组的值可以转换为一个字符串如下 :
{ 0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00 } = "dex\n035\0"
中间是一个 ‘\n' 符号 ,后面 035 是 Dex 文件格式的版本 。
(2) checksum 和 signature
文件校验码 ,使用alder32 算法校验文件除去 maigc ,checksum 外余下的所有文件区域 ,用于检
查文件错误 。
signature , 使用 SHA-1 算法 hash 除去 magic ,checksum 和 signature 外余下的所有文件区域 ,
用于唯一识别本文件 。
(3) file_size
Dex 文件的大小 。
(4) header_size
header 区域的大小 ,单位 Byte ,一般固定为 0x70 常量 。
(5) endian_tag
大小端标签 ,标准 .dex 文件格式为 小端 ,此项一般固定为 0x1234 5678 常量 。
(6) link_size和link_off
这个两个字段是表示链接数据的大小和偏移值
(7) map_off
map item 的偏移地址 ,该 item 属于 data 区里的内容 ,值要大于等于 data_off 的大小 。结构如
map_list 描述 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class MapList {
/**
* struct maplist
{
uint size;
map_item list [size];
}
*/
public int size;
public List<MapItem> map_item = new ArrayList<MapItem>();
}
定义位置 : data区
引用位置 :header 区 。
map_list 里先用一个 uint 描述后面有 size 个 map_item , 后续就是对应的 size 个 map_item 描述 。
map_item 结构有 4 个元素 : type 表示该 map_item 的类型 ,本节能用到的描述如下 ,详细Dalvik
Executable Format 里 Type Code 的定义 ;size 表示再细分此 item , 该类型的个数 ;offset 是第一个元
素的针对文件初始位置的偏移量 ; unuse 是用对齐字节的 ,无实际用处 。结构定义如下:
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
public class MapItem {
/**
* struct map_item
{
ushort type;
ushort unuse;
uint size;
uint offset;
}
*/
public short type;
public short unuse;
public int size;
public int offset;
public static int getSize(){
return 2 + 2 + 4 + 4;
}
@Override
public String toString(){
return "type:"+type+",unuse:"+unuse+",size:"+size+",offset:"+offset;
}
}
header->map_off = 0x0244 , 偏移为 0244 的位置值为 0x 000d 。
每个 map_item 描述占用 12 Byte , 整个 map_list 占用 12 * size + 4 个字节 。所以整个 map_list 占用空
间为 12 * 13 + 4 = 160 = 0x00a0 , 占用空间为 0x 0244 ~ 0x 02E3 。从文件内容上看 ,也是从 0x 0244
到文件结束的位置 。
地址 0x0244 的一个 uinit 的值为 0x0000 000d ,map_list - > size = 0x0d = 13 ,说明后续有 13 个
map_item 。根据 map_item 的结构描述在0x0248 ~ 0x02e3 里的值 ,整理出这段二进制所表示的 13 个
map_item 内容 ,汇成表格如下 :
map_list - > map_item 里的内容 ,有部分 item 跟 header 里面相应 item 的 offset 地址描述相同 。但
map_list 描述的更为全面些 ,又包括了 HEADER_ITEM , TYPE_LIST , STRING_DATA_ITEM 等 ,
最后还有它自己 TYPE_MAP_LIST 。
至此 , header 部分描述完毕 ,它包括描述 .dex 文件的信息 ,其余各索引区和 data 区的偏移信息 , 一个
map_list 结构 。map_list 里除了对索引区和数据区的偏移地址又一次描述 ,也有其它诸如 HEAD_ITEM ,
DEBUG_INFO_ITEM 等信息 。
(8) string_ids_size和string_ids_off
这两个字段表示dex中用到的所有的字符串内容的大小和偏移值,我们需要解析完这部分,然后用一个字符串池存起来,后面有其他的数据结构会用索引值来访问字符串,这个池子也是非常重要的。后面会详细介绍string_ids的数据结构
(9) type_ids_size和type_ids_off
这两个字段表示dex中的类型数据结构的大小和偏移值,比如类类型,基本类型等信息,后面会详细介绍type_ids的数据结构
(10) proto_ids_size和type_ids_off
这两个字段表示dex中的元数据信息数据结构的大小和偏移值,描述方法的元数据信息,比如方法的返回类型,参数类型等信息,后面会详细介绍proto_ids的数据结构
(11) field_ids_size和field_ids_off
这两个字段表示dex中的字段信息数据结构的大小和偏移值,后面会详细介绍field_ids的数据结构
(12) method_ids_size和method_ids_off
这两个字段表示dex中的方法信息数据结构的大小和偏移值,后面会详细介绍method_ids的数据结构
(13) class_defs_size和class_defs_off
这两个字段表示dex中的类信息数据结构的大小和偏移值,这个数据结构是整个dex中最复杂的数据结构,他内部层次很深,包含了很多其他的数据结构,所以解析起来也很麻烦,所以后面会着重讲解这个数据结构
(14) data_size和data_off
这两个字段表示dex中数据区域的结构信息的大小和偏移值,这个结构中存放的是数据区域,比如我们定义的常量值等信息。
到这里我们就看完了dex的头部信息,头部包含的信息还是很多的,主要就两个个部分:
1) 魔数+签名+文件大小等信息
2) 后面的各个数据结构的大小和偏移值,都是成对出现的
下面我们就来开始介绍各个数据结构的信息
第二、string_ids数据结构
string_ids 区索引了 .dex 文件所有的字符串 。 本区里的元素格式为 string_ids_item , 可以使用结构体如下描述 。
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class StringIdsItem {
/**
* struct string_ids_item
{
uint string_data_off;
}
*/
public int string_data_off;
public static int getSize(){
return 4;
}
@Override
public String toString(){
return Utils.bytesToHexString(Utils.int2Byte(string_data_off));
}
}
以 _ids 结尾的各个 section 里放置的都是对应数据的偏移地址 ,只是一个索引 ,所以才会在 dex文件布局里把这些区归类为 “索引区” 。
string_data_off 只是一个偏移地址 ,它指向的数据结构为 string_data_item
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class StringDataItem {
/**
* struct string_data_item
{
uleb128 utf16_size;
ubyte data;
}
*/
/**
* 上述描述里提到了 LEB128 ( little endian base 128 ) 格式 ,是基于 1 个 Byte 的一种不定长度的
编码方式 。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高
位为 0 。每个 Byte 的其余 Bit 用来表示数据
*/
public List<Byte> utf16_size = new ArrayList<Byte>();
public byte data;
}
延展
上述描述里提到了 LEB128 ( little endian base 128 ) 格式 ,是基于 1 个 Byte 的一种不定长度的编码方式 。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高位为 0 。每个 Byte 的其余 Bit 用来表示数据 。这里既然介绍了uleb128这种数据类型,就在这里解释一下,因为后面会经常用到这个数据类型,这个数据类型的出现其实就是为了解决一个问题,那就是减少内存的浪费,他就是表示int类型的数值,但是int类型四个字节有时候在使用的时候有点浪费,所以就应运而生了,他的原理也很简单:
图只是指示性的用两个字节表示。编码的每个字节有效部分只有低7bits,每个字节的最高bit用来指示是否是最后一个字节。
非最高字节的bit7为0
最高字节的bit7为1
将leb128编码的数字转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
比如:
LEB128编码的0x02b0 ---> 转换后的数字0x0130
转换过程:
0x02b0 => 0000 0010 1011 0000 =>去除最高位=> 000 0010 011 0000 =>按4bits重排 => 00 0001 0011 0000 => 0x130
底层代码位于:android/dalvik/libdex/leb128.h
Java中也写了一个工具类:
[java] view
plain copy
/**
* 读取C语言中的uleb类型
* 目的是解决整型数值浪费问题
* 长度不固定,在1~5个字节中浮动
* @param srcByte
* @param offset
* @return
*/
public static byte[] readUnsignedLeb128(byte[] srcByte, int offset){
List<Byte> byteAryList = new ArrayList<Byte>();
byte bytes = Utils.copyByte(srcByte, offset, 1)[0];
byte highBit = (byte)(bytes & 0x80);
byteAryList.add(bytes);
offset ++;
while(highBit != 0){
bytes = Utils.copyByte(srcByte, offset, 1)[0];
highBit = (byte)(bytes & 0x80);
offset ++;
byteAryList.add(bytes);
}
byte[] byteAry = new byte[byteAryList.size()];
for(int j=0;j<byteAryList.size();j++){
byteAry[j] = byteAryList.get(j);
}
return byteAry;
}
这个方法是读取dex中uleb128类型的数据,遇到一个字节最高位=0就停止读下个字节的原理来实现即可
还有一个方法就是解码uleb128类型的数据:
[java] view
plain copy
/**
* 解码leb128数据
* 每个字节去除最高位,然后进行拼接,重新构造一个int类型数值,从低位开始
* @param byteAry
* @return
*/
public static int decodeUleb128(byte[] byteAry) {
int index = 0, cur;
int result = byteAry[index];
index++;
if(byteAry.length == 1){
return result;
}
if(byteAry.length == 2){
cur = byteAry[index];
index++;
result = (result & 0x7f) | ((cur & 0x7f) << 7);
return result;
}
if(byteAry.length == 3){
cur = byteAry[index];
index++;
result |= (cur & 0x7f) << 14;
return result;
}
if(byteAry.length == 4){
cur = byteAry[index];
index++;
result |= (cur & 0x7f) << 21;
return result;
}
if(byteAry.length == 5){
cur = byteAry[index];
index++;
result |= cur << 28;
return result;
}
return result;
}
这个原理很简单,就是去除每个字节的最高位,然后拼接剩下的7位,然后从新构造一个int类型的数据,位不够就从低位开始左移。
我们通过上面的uleb128的解释来看,其实uleb128类型就是1~5个字节来回浮动,为什么是5呢?因为他要表示一个4个字节的int类型,但是每个字节要去除最高位,那么肯定最多只需要5个字节就可以表示4个字节的int类型数据了。这里就解释了uleb128数据类型,下面我们回归正题,继续来看string_ids数据结构
根据 string_ids_item 和 string_data_item 的描述 ,加上 header 里提供的入口位置 string_ids_size
= 0x0e , string_ids_off = 0x70 ,我们可以整理出 string_ids 及其对应的数据如下 :
string_ids_item 和 string_data_item 里提取出的对应数据表格 :
string 里的各种标志符号 ,诸如 L , V , VL , [ 等在 .dex 文件里有特殊的意思 。
string_ids 的终极奥义就是找到这些字符串 。其实使用二进制编辑器打开 .dex 文件时 ,一般工具默认翻译成 ASCII 码 ,总会一大片熟悉的字符白生生地很是亲切, 也很是晃眼 。刚才走过的一路子分析流程 ,就是顺藤摸瓜找到它们是怎么来的。以后的一些 type-ids , method_ids 也会引用到这一片熟悉的字符串。
注意:我们后面的解析代码会看到,其实我们没必要用那么复杂的去解析uleb128类型,因为我们会看到这个字符串和我们之前解析xml和resource.arsc格式一样,每个字符串的第一个字节表示字符串的长度,那么我们只要知道每个字符串的偏移地址就可以解析出字符串的内容了,而每个字符串的偏移地址是存放在string_ids_item中的。
到这里我们就解析完了dex中所有的字符串内容,我们用一个字符串池来进行存储即可。下面我们来继续看type_ids数据结构
第三、type_ids数据结构
这个数据结构中存放的数据主要是描述dex中所有的类型,比如类类型,基本类型等信息。type_ids 区索引了 dex 文件里的所有数据类型 ,包括 class 类型 ,数组类型(array types)和基本类型(primitive types) 。 本区域里的元素格式为 type_ids_item , 结构描述如下 :[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class TypeIdsItem {
/**
* struct type_ids_item
{
uint descriptor_idx;
}
*/
public int descriptor_idx;
public static int getSize(){
return 4;
}
@Override
public String toString(){
return Utils.bytesToHexString(Utils.int2Byte(descriptor_idx));
}
}
type_ids_item 里面 descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串 。
根据 header 里 type_ids_size = 0x07 , type_ids_off = 0xa8 , 找到对应的二进制描述区 。00000a0: 1a02
根据 type_id_item 的描述 ,整理出表格如下 。因为 type_id_item - > descriptor_idx 里存放的是指向 string_ids 的 index 号 ,所以我们也能得到该 type 的字符串描述 。这里出现了 3 个 type descriptor :
L 表示 class 的详细描述 ,一般以分号表示 class 描述结束 ;
V 表示 void 返回类型 ,只有在返回值的时候有效 ;
[ 表示数组 ,[Ljava/lang/String; 可以对应到 java 语言里的 java.lang.String[] 类型 。
我们后面的其他数据结构也会使用到type_ids类型,所以我们这里解析完type_ids也是需要用一个池子来存放的,后面直接用索引index来访问即可。
第四、proto_ids数据结构
proto 的意思是 method prototype 代表 java 语言里的一个 method 的原型 。proto_ids 里的元素为 proto_id_item , 结构如下 。[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class ProtoIdsItem {
/**
* struct proto_id_item
{
uint shorty_idx;
uint return_type_idx;
uint parameters_off;
}
*/
public int shorty_idx;
public int return_type_idx;
public int parameters_off;
//这个不是公共字段,而是为了存储方法原型中的参数类型名和参数个数
public List<String> parametersList = new ArrayList<String>();
public int parameterCount;
public static int getSize(){
return 4 + 4 + 4;
}
@Override
public String toString(){
return "shorty_idx:"+shorty_idx+",return_type_idx:"+return_type_idx+",parameters_off:"+parameters_off;
}
}
shorty_idx :跟 type_ids 一样 ,它的值是一个 string_ids 的 index 号 ,最终是一个简短的字符串描述 ,用来说明该 method 原型
return_type_idx :它的值是一个 type_ids 的 index 号 ,表示该 method 原型的返回值类型 。
parameters_off :后缀 off 是 offset , 指向 method 原型的参数列表 type_list ; 若 method 没有参数 ,值为0 。参数列表的格式是 type_list ,结构从逻辑上如下描述 。size 表示参数的个数 ;type_idx 是对应参数的类型 ,它的值是一个 type_ids 的 index 号 ,跟 return_type_idx 是同一个品种的东西 。
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class TypeList {
/**
* struct type_list
{
uint size;
ushort type_idx[size];
}
*/
public int size;//参数的个数
public List<Short> type_idx = new ArrayList<Short>();//参数的类型
}
header 里 proto_ids_size = 0x03 , proto_ids_off = 0xc4 , 它的二进制描述区如下 :
根据 proto_id_item 和 type_list 的格式 ,对照这它们的二进制部分 ,整理出表格如下 :
可以看出 ,有 3 个 method 原型 ,返回值都为 void ,index = 0 的没有参数传入 ,index = 1 的传入一个
String 参数 ,index=2 的传入一个 String[] 类型的参数 。
注意:我们在这里会看到很多idx结尾的字段,这个一般都是索引值,所以我们要注意的是,区分这个索引值到底是对应的哪张表格,是字符串池,还是类型池等信息,这个如果弄混淆的话,那么解析就会出现混乱了。这个后面其他数据结构都是需要注意的。
第五、field_ids数据结构
filed_ids 区里面存放的是dex 文件引用的所有的 field 。本区的元素格式是 field_id_item ,逻辑结构描述如[java] view
plain copy
package com.wjdiankong.parsedex.struct;
public class FieldIdsItem {
/**
* struct filed_id_item
{
ushort class_idx;
ushort type_idx;
uint name_idx;
}
*/
public short class_idx;
public short type_idx;
public int name_idx;
public static int getSize(){
return 2 + 2 + 4;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",type_idx:"+type_idx+",name_idx:"+name_idx;
}
}
class_idx :表示本 field 所属的 class 类型 , class_idx 的值是 type_ids 的一个 index , 并且必须指向一个class 类型 。
type_idx :表示本 field 的类型 ,它的值也是 type_ids 的一个 index 。
name_idx : 表示本 field 的名称 ,它的值是 string_ids 的一个 index 。
header 里 field_ids_size = 1 , field_ids_off = 0xe8 。说明本 .dex 只有一个 field ,这部分的二进制描述如下 :
注意:这里的字段都是索引值,一定要区分是哪个池子的索引值,还有就是,这个数据结构我们后面也要使用到,所以需要用一个池子来存储。
第六、 method_ids数据结构
method_ids 是索引区的最后一个条目 ,它索引了 dex 文件里的所有的 method.method_ids 的元素格式是 method_id_item , 结构跟 fields_ids 很相似:
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
public class MethodIdsItem {
/**
* struct filed_id_item
{
ushort class_idx;
ushort proto_idx;
uint name_idx;
}
*/
public short class_idx;
public short proto_idx;
public int name_idx;
public static int getSize(){
return 2 + 2 + 4;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",proto_idx:"+proto_idx+",name_idx:"+name_idx;
}
}
class_idx :表示本 method 所属的 class 类型 , class_idx 的值是 type_ids 的一个 index , 并且必须指向一个 class 类型 。
name_idx :表示本 method 的名称 ,它的值是 string_ids 的一个 index 。
proto_idx :描述该 method 的原型 ,指向 proto_ids 的一个 index 。
header 里 method_ids_size = 0x04 , method_ids_off = 0xf0 。本部分的二进制描述如下 :
对 dex 反汇编的时候 ,常用的 method 表示方法是这种形式 :
Lpackage/name/ObjectName;->MethodName(III)Z
将上述表格里的字符串再次整理下 ,method 的描述分别为 :
0:Lhello; -> <init>()V
1:LHello; -> main([Ljava/lang/String;)V
2:Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
3: Ljava/lang/Object; -> <init>()V
至此 ,索引区的内容描述完毕 ,包括 string_ids , type_ids,proto_ids , field_ids , method_ids 。每个索引区域里存放着指向具体数据的偏移地址 (如 string_ids ) , 或者存放的数据是其它索引区域里面的 index 号。
注意:这里的字段都是索引值,一定要区分是哪个池子的索引值,还有就是,这个数据结构我们后面也要使用到,所以需要用一个池子来存储。
第八、class_defs数据结构
上面我们介绍了所有的索引区域,终于到了最后一个数据结构了,但是我们现在还不能开心,因为这个数据结构是最复杂的,所以解析下来还是很费劲的。因为他的层次太深了。1、class_def_item
从字面意思解释 ,class_defs 区域里存放着 class definitions , class 的定义 。它的结构较 dex 区都要复杂些 ,因为有些数据都直接指向了data 区里面 。
class_defs 的数据格式为 class_def_item , 结构描述如下 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
public class ClassDefItem {
/**
* struct class_def_item
{
uint class_idx;
uint access_flags;
uint superclass_idx;
uint interfaces_off;
uint source_file_idx;
uint annotations_off;
uint class_data_off;
uint static_value_off;
}
*/
public int class_idx;
public int access_flags;
public int superclass_idx;
public int iterfaces_off;
public int source_file_idx;
public int annotations_off;
public int class_data_off;
public int static_value_off;
public final static int
ACC_PUBLIC = 0x00000001, // class, field, method, ic
ACC_PRIVATE = 0x00000002, // field, method, ic
ACC_PROTECTED = 0x00000004, // field, method, ic
ACC_STATIC = 0x00000008, // field, method, ic
ACC_FINAL = 0x00000010, // class, field, method, ic
ACC_SYNCHRONIZED = 0x00000020, // method (only allowed on natives)
ACC_SUPER = 0x00000020, // class (not used in Dalvik)
ACC_VOLATILE = 0x00000040, // field
ACC_BRIDGE = 0x00000040, // method (1.5)
ACC_TRANSIENT = 0x00000080, // field
ACC_VARARGS = 0x00000080, // method (1.5)
ACC_NATIVE = 0x00000100, // method
ACC_INTERFACE = 0x00000200, // class, ic
ACC_ABSTRACT = 0x00000400, // class, method, ic
ACC_STRICT = 0x00000800, // method
ACC_SYNTHETIC = 0x00001000, // field, method, ic
ACC_ANNOTATION = 0x00002000, // class, ic (1.5)
ACC_ENUM = 0x00004000, // class, field, ic (1.5)
ACC_CONSTRUCTOR = 0x00010000, // method (Dalvik only)
ACC_DECLARED_SYNCHRONIZED = 0x00020000, // method (Dalvik only)
ACC_CLASS_MASK =
(ACC_PUBLIC | ACC_FINAL | ACC_INTERFACE | ACC_ABSTRACT
| ACC_SYNTHETIC | ACC_ANNOTATION | ACC_ENUM),
ACC_INNER_CLASS_MASK =
(ACC_CLASS_MASK | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC),
ACC_FIELD_MASK =
(ACC_PUBLIC | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC | ACC_FINAL
| ACC_VOLATILE | ACC_TRANSIENT | ACC_SYNTHETIC | ACC_ENUM),
ACC_METHOD_MASK =
(ACC_PUBLIC | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC | ACC_FINAL
| ACC_SYNCHRONIZED | ACC_BRIDGE | ACC_VARARGS | ACC_NATIVE
| ACC_ABSTRACT | ACC_STRICT | ACC_SYNTHETIC | ACC_CONSTRUCTOR
| ACC_DECLARED_SYNCHRONIZED);
public static int getSize(){
return 4 * 8;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",access_flags:"+access_flags+",superclass_idx:"+superclass_idx+",iterfaces_off:"+iterfaces_off
+",source_file_idx:"+source_file_idx+",annotations_off:"+annotations_off+",class_data_off:"+class_data_off
+",static_value_off:"+static_value_off;
}
}
(1) class_idx:描述具体的 class 类型 ,值是 type_ids 的一个 index 。值必须是一个 class 类型 ,不能是数组类型或者基本类型 。
(2) access_flags: 描述 class 的访问类型 ,诸如 public , final , static 等 。在 dex-format.html 里 “access_flagsDefinitions” 有具体的描述 。
(3) superclass_idx:描述 supperclass 的类型 ,值的形式跟 class_idx 一样 。
(4) interfaces_off:值为偏移地址 ,指向 class 的 interfaces , 被指向的数据结构为 type_list 。class 若没有interfaces ,值为 0。
(5) source_file_idx:表示源代码文件的信息 ,值是 string_ids 的一个 index 。若此项信息缺失 ,此项值赋值为NO_INDEX=0xffff ffff
(6) annotions_off:值是一个偏移地址 ,指向的内容是该 class 的注释 ,位置在 data 区,格式为annotations_direcotry_item 。若没有此项内容 ,值为 0 。
(7) class_data_off:值是一个偏移地址 ,指向的内容是该 class 的使用到的数据 ,位置在 data 区,格式为class_data_item 。若没有此项内容 ,值为 0 。该结构里有很多内容 ,详细描述该 class 的 field ,method, method 里的执行代码等信息 ,后面有一个比较大的篇幅来讲述 class_data_item 。
(8) static_value_off:值是一个偏移地址 ,指向 data 区里的一个列表 ( list ) ,格式为 encoded_array_item。若没有此项内容 ,值为 0 。
header 里 class_defs_size = 0x01 , class_defs_off = 0x 0110 。则此段二进制描述为 :
其实最初被编译的源码只有几行 ,和 class_def_item 的表格对照下 ,一目了然 。
source file : Hello.java
public class Hello
{
element value associated strinigs
class_idx 0x00 LHello;
access_flags 0x01 ACC_PUBLIC
superclass_idx 0x02 Ljava/lang/Object;
interface_off 0x00
source_file_idx 0x02 Hello.java
annotations_off 0x00
class_data_off 0x0234
static_value_off 0x00
public static void main(String[] argc)
{
System.out.println("Hello, Android!\n");
}
}
2、 class_def_item => class_data_item
class_data_off 指向 data 区里的 class_data_item 结构 ,class_data_item 里存放着本 class 使用到的各种数据 ,下面是 class_data_item 的逻辑结构 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
public class ClassDataItem {
/**
* uleb128 unsigned little-endian base 128
struct class_data_item
{
uleb128 static_fields_size;
uleb128 instance_fields_size;
uleb128 direct_methods_size;
uleb128 virtual_methods_size;
encoded_field static_fields [ static_fields_size ];
encoded_field instance_fields [ instance_fields_size ];
encoded_method direct_methods [ direct_method_size ];
encoded_method virtual_methods [ virtual_methods_size ];
}
*/
//uleb128只用来编码32位的整型数
public int static_fields_size;
public int instance_fields_size;
public int direct_methods_size;
public int virtual_methods_size;
public EncodedField[] static_fields;
public EncodedField[] instance_fields;
public EncodedMethod[] direct_methods;
public EncodedMethod[] virtual_methods;
@Override
public String toString(){
return "static_fields_size:"+static_fields_size+",instance_fields_size:"
+instance_fields_size+",direct_methods_size:"+direct_methods_size+",virtual_methods_size:"+virtual_methods_size
+"\n"+getFieldsAndMethods();
}
private String getFieldsAndMethods(){
StringBuilder sb = new StringBuilder();
sb.append("static_fields:\n");
for(int i=0;i<static_fields.length;i++){
sb.append(static_fields[i]+"\n");
}
sb.append("instance_fields:\n");
for(int i=0;i<instance_fields.length;i++){
sb.append(instance_fields[i]+"\n");
}
sb.append("direct_methods:\n");
for(int i=0;i<direct_methods.length;i++){
sb.append(direct_methods[i]+"\n");
}
sb.append("virtual_methods:\n");
for(int i=0;i<virtual_methods.length;i++){
sb.append(virtual_methods[i]+"\n");
}
return sb.toString();
}
}
关于元素的格式 uleb128 在 string_ids 里有讲述过 ,不赘述 。
encoded_field 的结构如下 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class EncodedField {
/**
* struct encoded_field
{
uleb128 filed_idx_diff; // index into filed_ids for ID of this filed
uleb128 access_flags; // access flags like public, static etc.
}
*/
public byte[] filed_idx_diff;
public byte[] access_flags;
@Override
public String toString(){
return "field_idx_diff:"+Utils.bytesToHexString(filed_idx_diff) + ",access_flags:"+Utils.bytesToHexString(filed_idx_diff);
}
}
encoded_method 的结构如下 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class EncodedMethod {
/**
* struct encoded_method
{
uleb128 method_idx_diff;
uleb128 access_flags;
uleb128 code_off;
}
*/
public byte[] method_idx_diff;
public byte[] access_flags;
public byte[] code_off;
@Override
public String toString(){
return "method_idx_diff:"+Utils.bytesToHexString(method_idx_diff)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(method_idx_diff)))
+",access_flags:"+Utils.bytesToHexString(access_flags)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(access_flags)))
+",code_off:"+Utils.bytesToHexString(code_off)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(code_off)));
}
}
(1) method_idx_diff:前缀 methd_idx 表示它的值是 method_ids 的一个 index ,后缀 _diff 表示它是于另外一个 method_idx 的一个差值 ,就是相对于 encodeed_method [] 数组里上一个元素的 method_idx 的差值 。其实 encoded_filed
- > field_idx_diff 表示的也是相同的意思 ,只是编译出来的 Hello.dex 文件里没有使用到class filed 所以没有仔细讲 ,详细的参考 dex_format.html 的官网文档
(2) access_flags:访问权限 , 比如 public、private、static、final 等 。
(3) code_off:一个指向 data 区的偏移地址 ,目标是本 method 的代码实现 。被指向的结构是
code_item ,有近 10 项元素 ,后面再详细解释 。
class_def_item -- > class_data_off = 0x 0234 。
名称为 LHello; 的 class 里只有 2 个 directive methods 。 directive_methods 里的值都是 uleb128 的原始二
进制值 。按照 directive_methods 的格式 encoded_method 再整理一次这 2 个 method 描述 ,得到结果如下
表格所描述 :
method 一个是 <init> , 一个是 main , 这里我们需要用我们在string_ids那块介绍到的一个方法就是解码uleb125类型的方法得到正确的value值。
3、class_def_item => class_data_item => code_item
到这里 ,逻辑的描述有点深入了 。我自己都有点分析不过来 ,先理一下是怎么走到这一步的 ,code_item
在 dex 里处于一个什么位置 。
(1) 一个 .dex 文件被分成了 9 个区 ,详细见 “1. dex 整个文件的布局 ” 。其中有一个索引区叫做
class_defs , 索引了 .dex 里面用到的 class ,以及对这个 class 的描述 。
(2) class_defs 区 , 这里面其实是class_def_item 结构 。这个结构里描述了 LHello; 的各种信息 ,诸如名称 ,superclass , access flag, interface 等 。class_def_item 里有一个元素 class_data_off , 指向data 区里的一个 class_data_item 结构 ,用来描述 class 使用到的各种数据 。自此以后的结构都归于 data区了 。
(3) class_data_item 结构 ,里描述值着 class 里使用到的 static field , instance field , direct_method ,和 virtual_method 的数目和描述 。例子 Hello.dex 里 ,只有 2 个 direct_method , 其余的 field 和method 的数目都为 0 。描述 direct_method 的结构叫做 encoded_method ,是用来详细描述某个 method的 。
(4) encoded_method 结构 ,描述某个 method 的 method 类型 , access flags 和一个指向 code_item的偏移地址 ,里面存放的是该 method 的具体实现 。
(5) code_item , 一层又一层 ,盗梦空间啊!简要的说 ,code_item 结构里描述着某个 method 的具体实现 。它的结构如下描述 :
[java] view
plain copy
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class CodeItem {
/**
* struct code_item
{
ushort registers_size;
ushort ins_size;
ushort outs_size;
ushort tries_size;
uint debug_info_off;
uint insns_size;
ushort insns [ insns_size ];
ushort paddding; // optional
try_item tries [ tyies_size ]; // optional
encoded_catch_handler_list handlers; // optional
}
*/
public short registers_size;
public short ins_size;
public short outs_size;
public short tries_size;
public int debug_info_off;
public int insns_size;
public short[] insns;
@Override
public String toString(){
return "regsize:"+registers_size+",ins_size:"+ins_size
+",outs_size:"+outs_size+",tries_size:"+tries_size+",debug_info_off:"+debug_info_off
+",insns_size:"+insns_size + "\ninsns:"+getInsnsStr();
}
private String getInsnsStr(){
StringBuilder sb = new StringBuilder();
for(int i=0;i<insns.length;i++){
sb.append(Utils.bytesToHexString(Utils.short2Byte(insns[i]))+",");
}
return sb.toString();
}
}
末尾的 3 项标志为 optional , 表示可能有 ,也可能没有 ,根据具体的代码来 。
(1) registers_size:本段代码使用到的寄存器数目。
(2) ins_size:method传入参数的数目 。
(3) outs_size: 本段代码调用其它method 时需要的参数个数 。
(4) tries_size: try_item 结构的个数 。
(5) debug_off:偏移地址 ,指向本段代码的 debug 信息存放位置 ,是一个 debug_info_item 结构。
(6) insns_size:指令列表的大小 ,以 16-bit 为单位 。 insns 是 instructions 的缩写 。
(7) padding:值为 0 ,用于对齐字节 。
(8) tries 和 handlers:用于处理 java 中的 exception , 常见的语法有 try catch 。
4、 分析 main method 的执行代码并与 smali 反编译的结果比较
在 8.2 节里有 2 个 method , 因为 main 里的执行代码是自己写的 ,分析它会熟悉很多 。偏移地址是
directive_method [1] -> code_off = 0x0148 ,二进制描述如下 :
insns 数组里的 8 个二进制原始数据 , 对这些数据的解析 ,需要对照官网的文档 《Dalvik VM Instruction
Format》和《Bytecode for Dalvik VM》。
分析思路整理如下
(1) 《Dalvik VM Instruction Format》 里操作符 op 都是位于首个 16bit 数据的低 8 bit ,起始的是 op =0x62。
(2) 在 《Bytecode for Dalvik VM》 里找到对应的 Syntax 和 format 。
syntax = sget_object
format = 0x21c 。
(3) 在《Dalvik VM Instruction Format》里查找 21c , 得知 op = 0x62 的指令占据 2 个 16 bit 数据 ,格式是 AA|op BBBB ,解释为 op vAA, type@BBBB 。因此这 8 组 16 bit 数据里 ,前 2 个是一组 。对比数据得 AA=0x00, BBBB = 0x0000。
(4)返回《Bytecode for Dalvik VM》里查阅对 sget_object 的解释, AA 的值表示 Value Register ,即0 号寄存器; BBBB 表示 static field 的 index ,就是之前分析的field_ids 区里 Index = 0 指向的那个东西 ,当时的 fields_ids 的分析结果如下 :
对 field 常用的表述是
包含 field 的类型 -> field 名称 :field 类型 。
此次指向的就是 Ljava/lang/System; -> out:Ljava/io/printStream;
(5) 综上 ,前 2 个 16 bit 数据 0x 0062 0000 , 解释为
sget_object v0, Ljava/lang/System; -> out:Ljava/io/printStream;
其余的 6 个 16 bit 数据分析思路跟这个一样 ,依次整理如下 :
0x011a 0x0001: const-string v1, “Hello, Android!”
0x206e 0x0002 0x0010:
invoke-virtual {v0, v1}, Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
0x000e: return-void
(6) 最后再整理下 main method , 用容易理解的方式表示出来就是 。
ACC_PUBLIC ACC_STATIC LHello;->main([Ljava/lang/String;)V
{
sget_object v0, Ljava/lang/System; -> out:Ljava/io/printStream;
const-string v1,Hello, Android!
invoke-virtual {v0, v1}, Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
return-void
}
看起来很像 smali 格式语言 ,不妨使用 smali 反编译下 Hello.dex , 看看 smali 生成的代码跟方才推导出
来的有什么差异 。
.method public static main([Ljava/lang/String;)V
.registers 3
.prologue
.line 5
sget-object v0, Ljava/lang/System;->out:Ljava/io/PrintStream;
const-string v1, "Hello, Android!\n"
index 0
class_idx 0x04
type_idx 0x01
name_idx 0x0c
class string Ljava/lang/System;
type string Ljava/io/PrintStream;
name string out
invoke-virtual {v0, v1}, Ljava/io/PrintStream;->println(Ljava/lang/String;)V
.line 6
return-void
从内容上看 ,二者形式上有些差异 ,但表述的是同一个 method 。这说明刚才的分析走的路子是没有跑偏
的 。另外一个 method 是 <init> , 若是分析的话 ,思路和流程跟 main 一样 。走到这里,心里很踏实了。
四、解析代码
上面我们解析完了所有的数据结构区域,下面就来看看具体的解析代码,由于篇幅的原因,这里就不贴出全部的代码了,只贴出核心的代码:
1、解析头部信息:
[java] viewplain copy
public static void praseDexHeader(byte[] byteSrc){
HeaderType headerType = new HeaderType();
//解析魔数
byte[] magic = Utils.copyByte(byteSrc, 0, 8);
headerType.magic = magic;
//解析checksum
byte[] checksumByte = Utils.copyByte(byteSrc, 8, 4);
headerType.checksum = Utils.byte2int(checksumByte);
//解析siganature
byte[] siganature = Utils.copyByte(byteSrc, 12, 20);
headerType.siganature = siganature;
//解析file_size
byte[] fileSizeByte = Utils.copyByte(byteSrc, 32, 4);
headerType.file_size = Utils.byte2int(fileSizeByte);
//解析header_size
byte[] headerSizeByte = Utils.copyByte(byteSrc, 36, 4);
headerType.header_size = Utils.byte2int(headerSizeByte);
//解析endian_tag
byte[] endianTagByte = Utils.copyByte(byteSrc, 40, 4);
headerType.endian_tag = Utils.byte2int(endianTagByte);
//解析link_size
byte[] linkSizeByte = Utils.copyByte(byteSrc, 44, 4);
headerType.link_size = Utils.byte2int(linkSizeByte);
//解析link_off
byte[] linkOffByte = Utils.copyByte(byteSrc, 48, 4);
headerType.link_off = Utils.byte2int(linkOffByte);
//解析map_off
byte[] mapOffByte = Utils.copyByte(byteSrc, 52, 4);
headerType.map_off = Utils.byte2int(mapOffByte);
//解析string_ids_size
byte[] stringIdsSizeByte = Utils.copyByte(byteSrc, 56, 4);
headerType.string_ids_size = Utils.byte2int(stringIdsSizeByte);
//解析string_ids_off
byte[] stringIdsOffByte = Utils.copyByte(byteSrc, 60, 4);
headerType.string_ids_off = Utils.byte2int(stringIdsOffByte);
//解析type_ids_size
byte[] typeIdsSizeByte = Utils.copyByte(byteSrc, 64, 4);
headerType.type_ids_size = Utils.byte2int(typeIdsSizeByte);
//解析type_ids_off
byte[] typeIdsOffByte = Utils.copyByte(byteSrc, 68, 4);
headerType.type_ids_off = Utils.byte2int(typeIdsOffByte);
//解析proto_ids_size
byte[] protoIdsSizeByte = Utils.copyByte(byteSrc, 72, 4);
headerType.proto_ids_size = Utils.byte2int(protoIdsSizeByte);
//解析proto_ids_off
byte[] protoIdsOffByte = Utils.copyByte(byteSrc, 76, 4);
headerType.proto_ids_off = Utils.byte2int(protoIdsOffByte);
//解析field_ids_size
byte[] fieldIdsSizeByte = Utils.copyByte(byteSrc, 80, 4);
headerType.field_ids_size = Utils.byte2int(fieldIdsSizeByte);
//解析field_ids_off
byte[] fieldIdsOffByte = Utils.copyByte(byteSrc, 84, 4);
headerType.field_ids_off = Utils.byte2int(fieldIdsOffByte);
//解析method_ids_size
byte[] methodIdsSizeByte = Utils.copyByte(byteSrc, 88, 4);
headerType.method_ids_size = Utils.byte2int(methodIdsSizeByte);
//解析method_ids_off
byte[] methodIdsOffByte = Utils.copyByte(byteSrc, 92, 4);
headerType.method_ids_off = Utils.byte2int(methodIdsOffByte);
//解析class_defs_size
byte[] classDefsSizeByte = Utils.copyByte(byteSrc, 96, 4);
headerType.class_defs_size = Utils.byte2int(classDefsSizeByte);
//解析class_defs_off
byte[] classDefsOffByte = Utils.copyByte(byteSrc, 100, 4);
headerType.class_defs_off = Utils.byte2int(classDefsOffByte);
//解析data_size
byte[] dataSizeByte = Utils.copyByte(byteSrc, 104, 4);
headerType.data_size = Utils.byte2int(dataSizeByte);
//解析data_off
byte[] dataOffByte = Utils.copyByte(byteSrc, 108, 4);
headerType.data_off = Utils.byte2int(dataOffByte);
System.out.println("header:"+headerType);
stringIdOffset = headerType.header_size;//header之后就是string ids
stringIdsSize = headerType.string_ids_size;
stringIdsOffset = headerType.string_ids_off;
typeIdsSize = headerType.type_ids_size;
typeIdsOffset = headerType.type_ids_off;
fieldIdsSize = headerType.field_ids_size;
fieldIdsOffset = headerType.field_ids_off;
protoIdsSize = headerType.proto_ids_size;
protoIdsOffset = headerType.proto_ids_off;
methodIdsSize = headerType.method_ids_size;
methodIdsOffset = headerType.method_ids_off;
classIdsSize = headerType.class_defs_size;
classIdsOffset = headerType.class_defs_off;
mapListOffset = headerType.map_off;
}
这里没啥说的,就是记录几个索引区的偏移值和大小信息。
解析结果:
2、解析string_ids索引区
[java] viewplain copy
/************************解析字符串********************************/
public static void parseStringIds(byte[] srcByte){
int idSize = StringIdsItem.getSize();
int countIds = stringIdsSize;
for(int i=0;i<countIds;i++){
stringIdsList.add(parseStringIdsItem(Utils.copyByte(srcByte, stringIdsOffset+i*idSize, idSize)));
}
System.out.println("string size:"+stringIdsList.size());
}
public static void parseStringList(byte[] srcByte){
//第一个字节还是字符串的长度
for(StringIdsItem item : stringIdsList){
String str = getString(srcByte, item.string_data_off);
System.out.println("str:"+str);
stringList.add(str);
}
}
解析结果:
3、解析type_ids索引区
[java] viewplain copy
/***************************解析类型******************************/
public static void parseTypeIds(byte[] srcByte){
int idSize = TypeIdsItem.getSize();
int countIds = typeIdsSize;
for(int i=0;i<countIds;i++){
typeIdsList.add(parseTypeIdsItem(Utils.copyByte(srcByte, typeIdsOffset+i*idSize, idSize)));
}
//这里的descriptor_idx就是解析之后的字符串中的索引值
for(TypeIdsItem item : typeIdsList){
System.out.println("typeStr:"+stringList.get(item.descriptor_idx));
}
}
解析结果:
4、解析proto_ids索引区
[html] viewplain copy
/***************************解析Proto***************************/
public static void parseProtoIds(byte[] srcByte){
int idSize = ProtoIdsItem.getSize();
int countIds = protoIdsSize;
for(int i=0;i<countIds;i++){
protoIdsList.add(parseProtoIdsItem(Utils.copyByte(srcByte, protoIdsOffset+i*idSize, idSize)));
}
for(ProtoIdsItem item : protoIdsList){
System.out.println("proto:"+stringList.get(item.shorty_idx)+","+stringList.get(item.return_type_idx));
//有的方法没有参数,这个值就是0
if(item.parameters_off != 0){
item = parseParameterTypeList(srcByte, item.parameters_off, item);
}
}
}
//解析方法的所有参数类型
private static ProtoIdsItem parseParameterTypeList(byte[] srcByte, int startOff, ProtoIdsItem item){
//解析size和size大小的List中的内容
byte[] sizeByte = Utils.copyByte(srcByte, startOff, 4);
int size = Utils.byte2int(sizeByte);
List<String> parametersList = new ArrayList<String>();
List<Short> typeList = new ArrayList<Short>(size);
for(int i=0;i<size;i++){
byte[] typeByte = Utils.copyByte(srcByte, startOff+4+2*i, 2);
typeList.add(Utils.byte2Short(typeByte));
}
System.out.println("param count:"+size);
for(int i=0;i<typeList.size();i++){
System.out.println("type:"+stringList.get(typeList.get(i)));
int index = typeIdsList.get(typeList.get(i)).descriptor_idx;
parametersList.add(stringList.get(index));
}
item.parameterCount = size;
item.parametersList = parametersList;
return item;
}
解析结果:
5、解析field_ids索引区
[java] viewplain copy
/***************************解析字段****************************/
public static void parseFieldIds(byte[] srcByte){
int idSize = FieldIdsItem.getSize();
int countIds = fieldIdsSize;
for(int i=0;i<countIds;i++){
fieldIdsList.add(parseFieldIdsItem(Utils.copyByte(srcByte, fieldIdsOffset+i*idSize, idSize)));
}
for(FieldIdsItem item : fieldIdsList){
int classIndex = typeIdsList.get(item.class_idx).descriptor_idx;
int typeIndex = typeIdsList.get(item.type_idx).descriptor_idx;
System.out.println("class:"+stringList.get(classIndex)+",name:"+stringList.get(item.name_idx)+",type:"+stringList.get(typeIndex));
}
}
解析结果:
6、解析method_ids索引区
[java] viewplain copy
/***************************解析方法*****************************/
public static void parseMethodIds(byte[] srcByte){
int idSize = MethodIdsItem.getSize();
int countIds = methodIdsSize;
for(int i=0;i<countIds;i++){
methodIdsList.add(parseMethodIdsItem(Utils.copyByte(srcByte, methodIdsOffset+i*idSize, idSize)));
}
for(MethodIdsItem item : methodIdsList){
int classIndex = typeIdsList.get(item.class_idx).descriptor_idx;
int returnIndex = protoIdsList.get(item.proto_idx).return_type_idx;
String returnTypeStr = stringList.get(typeIdsList.get(returnIndex).descriptor_idx);
int shortIndex = protoIdsList.get(item.proto_idx).shorty_idx;
String shortStr = stringList.get(shortIndex);
List<String> paramList = protoIdsList.get(item.proto_idx).parametersList;
StringBuilder parameters = new StringBuilder();
parameters.append(returnTypeStr+"(");
for(String str : paramList){
parameters.append(str+",");
}
parameters.append(")"+shortStr);
System.out.println("class:"+stringList.get(classIndex)+",name:"+stringList.get(item.name_idx)+",proto:"+parameters);
}
}
7、解析class_def区域
[java] viewplain copy
/****************************解析类*****************************/
public static void parseClassIds(byte[] srcByte){
System.out.println("classIdsOffset:"+Utils.bytesToHexString(Utils.int2Byte(classIdsOffset)));
System.out.println("classIds:"+classIdsSize);
int idSize = ClassDefItem.getSize();
int countIds = classIdsSize;
for(int i=0;i<countIds;i++){
classIdsList.add(parseClassDefItem(Utils.copyByte(srcByte, classIdsOffset+i*idSize, idSize)));
}
for(ClassDefItem item : classIdsList){
System.out.println("item:"+item);
int classIdx = item.class_idx;
TypeIdsItem typeItem = typeIdsList.get(classIdx);
System.out.println("classIdx:"+stringList.get(typeItem.descriptor_idx));
int superClassIdx = item.superclass_idx;
TypeIdsItem superTypeItem = typeIdsList.get(superClassIdx);
System.out.println("superitem:"+stringList.get(superTypeItem.descriptor_idx));
int sourceIdx = item.source_file_idx;
String sourceFile = stringList.get(sourceIdx);
System.out.println("sourceFile:"+sourceFile);
classDataMap.put(sourceFile, item);
}
}
解析结果:
这里我们看到解析结果我们可能有点看不懂,其实这里我是没有在继续解读下去了,为什么,因为我们通过class_def的数据结构解析可以看到,我们需要借助《Bytecode for Dalvik VM》这个来进行查阅具体的指令,然后翻译成具体的指令代码,关于这个指令表可以参考这里:http://www.netmite.com/android/mydroid/dalvik/docs/dalvik-bytecode.html,所以具体解析并不复杂,所以这里就不在详细解析了,具体的解析思路,可以参考class_def的数据结构解析那一块的内容,上面又说道。
项目下载地址:https://github.com/fourbrother/parse_androiddex
注意:
我们到这里算是解析完了dex文件了,但是我现在要告诉大家,其实Android中有一个工具可以为我们做这个事,不知道大家还记得我们之前介绍解析AndroidManifest.xml和resource.arsc文件格式的时候,也是一样的,直接用aapt命令就可以查看了,这里也是一样的,只是这个工具是:dexdump
这个命令也是在AndroidSdk目录下的build-tools下面,这里我们可以将打印的结果重定向到demo.txt文件中
那么我们上面做的解析工作是不是就没有用了呢?当然不是,我们在后面会说道我们解析dex格式有很多用途的。
五、技术总结和概述
到这里我们就解析完了dex文件的所有东东,讲解的内容有点多,在这里就来总结一下:
第一、学习到的技术
1、我们学习到了如何不是用任何的IDE工具,就可以构造一个dex文件出来,主要借助于java和dx命令。同时,我们也学会了一个可以执行dex文件的命令:dalvikvm;不过这个命令需要root权限。2、我们了解到了Android中的DVM指令,如何翻译指令代码。
3、学习了一个数据类型:uleb128,如何将uleb128类型和int类型进行转化。
第二、未解决的问题
我们在整个解析的过程中会发现,我们这里只是用一个非常简单的dex来做案例解析,所以解析起来也很容易,但是我们实际的过程中,不会这么简单的,一个类可能实现多个接口,内部类,注解等信息的时候,解析起来肯定还要复杂,那么我们这篇文章主要的目的是介绍一下dex的文件格式,目的不是说去解决实际中项目的问题,所以后面在解析复杂的dex的时候,我们也只能遇到什么问题就去解决一下。
第三、我们解析dex的目的是啥?
我们开始的时候,并没有介绍说解析dex干啥?那么现在可以说,解析完dex之后我们有很多事都可以做了。1、我们可以检测一个apk中是否包含了指定系统的api(当然这些api没有被混淆),同样也可以检测这个apk是否包含了广告,以前我们可以通过解析AndroidManifest.xml文件中的service,activity,receiver,meta等信息来判断,因为现在的广告sdk都需要添加这些东西,如果我们可以解析dex的话,那么我们可以得到他的所有字符串内容,就是string_ids池,这样就可以判断调用了哪些api。那么就可以判断这个apk的一些行为了,当然这里还有一个问题,假如dex加密了我们就蛋疼了。好吧,那就牵涉出第二件事了。
2、我们在之前说过如何对apk进行加固,其实就是加密apk/dex文件内容,那么这时候我们必须要了解dex的文件结构信息,因为我们先加密dex,然后在动态加载dex进行解密即可。
3、我们可以更好的逆向工作,其实说到这里,我们看看apktool源码也知道,他内部的反编译原理就是这些,只是他会将指令翻译成smail代码,这个网上是有相对应的jar包api的,所以我们知道了dex的数据结构,那么原理肯定就知道了,同样还有一个dex2jar工具原理也是类似的。
六、总结
到这里我们就介绍完了dex文件格式的解析工作,至此我们也解析完了Android中编译之后的所有文件格式,我之所以介绍这几篇文章,一来是更好的了解Android中生成apk的流程,其次是我们能更好的的解决反编译过程中遇到的问题,我们需要去解决。这篇文章解析起来还是很费劲的,累死了,也是2016年第一篇文章,谢谢大家的支持~~。记得点赞呀~~

相关文章推荐
- Android逆向之旅---解析编译之后的Dex文件格式
- Android逆向之旅---解析编译之后的Dex文件格式
- Android逆向之旅---解析编译之后的classes.dex文件格式
- Android逆向之旅---解析编译之后的Dex文件格式
- Android逆向之旅---解析编译之后的Dex文件格式
- Android逆向之旅---解析编译之后的Dex文件格式
- Android逆向之旅---解析编译之后的AndroidManifest文件格式
- Android解析编译之后的所有文件(so,dex,xml,arsc)格式
- Android逆向之旅---解析编译之后的AndroidManifest文件格式
- Android解析编译之后的所有文件(so,dex,xml,arsc)格式
- Android解析编译之后的所有文件(so,dex,xml,arsc)格式
- Android解析编译之后的所有文件(so,dex,xml,arsc)格式
- Android逆向之旅---解析编译之后的Resource.arsc文件格式
- Android逆向之旅---解析编译之后的Resource.arsc文件格式
- Android解析编译之后的所有文件(so,dex,xml,arsc)格式
- Android逆向之旅---解析编译之后的Resource.arsc文件格式
- Android逆向之旅—解析编译之后的AndroidManifest文件格式