Java基础(集合卷)--单列集合老大Collection
2017-11-21 22:19
225 查看
Collection知识点梳理:
1.集合只能存储引用类型,不能存放值类型。非要存放,可以用值类型对应的包装类型进行转换;
2.JDK1.5之后,出现了自动拆装箱,系统会自动将存入集合的值类型转换为包装类
3.集合框架最顶层的两个接口分别是Collection与Map;
4.一般继承自Collection或Map的集合类,会提供两个"标准"的构造函数:
没有参数的构造函数,创建一个空的集合类;
有一个类型与基类(Collection或Map)相同的构造函数,创建一个与给定参数具有相同元素的新集合类;
5.因为接口中不能包含构造函数,所以上面这两个构造函数的约定并不是强制性的,但是在目前的集合框架中,所有继承自Collection或Map的子类都遵循这一约定。
(1)我们学习的是面向对象语言,而面向对象语言对事物的描述是通过对象体现的,为了方便对多个对象进行操作,我们就必须把这多个对象进行存储;
(2)存储多个对象,不能是一个基本的变量,而应该是一个容器类型的变量
(3)数组和StringBuffer都是容器类型,但它们有如下缺点:
1)StringBuffer的结果是一个字符串;
2)数组的长度是不可变的;
2.为了解决这个问题,java提供了集合这个容器
(1)集合的存在就是为了方便对多个对象的操作,集合是存储对象最常用的一种方式;
(2)集合是依赖对象而生的,所以无法存放值类型
3.为什么无法集合无法存放值类型?
(1)集合中存放的都是对象的引用,实际内容都在堆上面或者方法区里面,但是基本数据类型是在栈上分配空间的。随时都有可能会被收回。
(2)通过自动拆装箱,或者包装类都可以把基本类型转为引用类型,值类型放入集合的问题就解决了。
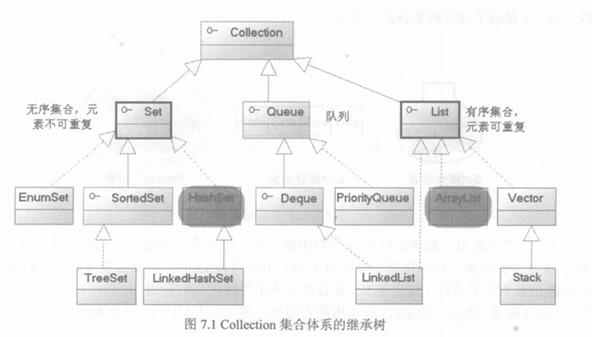
2.虽然它们各自的数据结构不同,方法不同,但它们都是用来存储元素的。将它们的共性抽离出来,分成了两个流派,单例集合和双列集合,单列集合的老大是:Collection
3.关系图:
数组的长度固定;
集合长度可变;
2.内容不同
数组存储的是同一种类型的元素;
而集合可以存储不同类型的元素;
3.元素的数据类型问题
数组可以存储基本数据类型,也可以存储引用数据类型;
集合只能存储引用类型;
ArrayList--
底层数据结构是数组,查询快,增删慢
线程不安全,效率高
Vector--
底层数据结构是数组,查询快,增删慢
线程安全,效率低
LinkedList--
底层数据结构是链表,查询慢,增删快
线程不安全,效率高
Set(无序,唯一)
HashSet--
底层数据结构是哈希表。
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
LinkedHashSet<E>
底层数据结构由链表和哈希表组成。
由链表保证元素有序。
由哈希表保证元素唯一。
TreeSet<E>
底层数据结构是红黑树。(是一种自平衡的二叉树)
如何保证元素唯一性呢?
根据比较的返回值是否是0来决定
如何保证元素的排序呢?
两种方式
自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
比较器排序(集合具备比较性)
让集合接收一个Comparator的实现类对象
B:存储的是键值对形式的元素,键唯一,值可重复。
HashMap
底层数据结构是哈希表。线程不安全,效率高
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
LinkedHashMap
底层数据结构由链表和哈希表组成。
由链表保证元素有序。
由哈希表保证元素唯一。
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
TreeMap--
底层数据结构是红黑树。(是一种自平衡的二叉树)
如何保证元素唯一性呢?
根据比较的返回值是否是0来决定
如何保证元素的排序呢?
两种方式
自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
比较器排序(集合具备比较性)
让集合接收一个Comparator的实现类对象
2:到底使用哪种集合呢?-->看需求
是否是键值对象形式:
是:Map
键是否需要排序:
是:TreeMap
否:HashMap
不知道,就使用HashMap。
否:Collection
元素是否唯一:
是:Set
元素是否需要排序:
是:TreeSet<E>
否:HashSet
不知道,就使用HashSet
否:List
要安全吗:
是:Vector
否:
增删多:LinkedList
查询多:ArrayList
不知道,就使用ArrayList
不知道,就使用ArrayList
3:集合的常见方法及遍历方式
Collection:
add()
remove()
contains()
iterator()
size()
遍历:
增强for
迭代器
|--List
get()
遍历:
普通for
|--Set
Map:
put()
remove()
containskey(),containsValue()
keySet()
get()
value()
entrySet()
size()
遍历:
根据键找值
根据键值对对象分别找键和值
Collection
c =
new ArrayList();
c.add("hello");
c.add("world");
c.add("java");
System.out.println(c);//"hello
world java"
2.为什么c输出的不是地址值呢?
A:Collection c = new ArrayList();
这是多态,所以输出c的toString()方法,其实是输出ArrayList的toString()
B:看ArrayList的toString()
而我们在ArrayList里面却没有发现toString()。
以后遇到这种情况,也不要担心,你认为有,它却没有,就应该去它父亲里面看看。
C:toString()的方法源码
public String toString() {
Iterator<E>
it = iterator();
//集合本身调用迭代器方法,得到集合迭代器
if
(! it.hasNext())
return
"[]";
StringBuilder sb
= new StringBuilder();
sb.append('[');
for
(;;) {//for这样写便是死循环
E e
= it.next();
//e=hello,world,java
sb.append(e
== this ?
"(this Collection)" : e);//三元表达式,e与调用本方法的集合对象本身作比较,e是否与集合本身对象相等.
if
(! it.hasNext())
//[hello, world, java]
return sb.append(']').toString();
sb.append(',').append('
');
}
}
1.集合只能存储引用类型,不能存放值类型。非要存放,可以用值类型对应的包装类型进行转换;
2.JDK1.5之后,出现了自动拆装箱,系统会自动将存入集合的值类型转换为包装类
3.集合框架最顶层的两个接口分别是Collection与Map;
4.一般继承自Collection或Map的集合类,会提供两个"标准"的构造函数:
没有参数的构造函数,创建一个空的集合类;
有一个类型与基类(Collection或Map)相同的构造函数,创建一个与给定参数具有相同元素的新集合类;
5.因为接口中不能包含构造函数,所以上面这两个构造函数的约定并不是强制性的,但是在目前的集合框架中,所有继承自Collection或Map的子类都遵循这一约定。
一.前言
1.集合的由来:(1)我们学习的是面向对象语言,而面向对象语言对事物的描述是通过对象体现的,为了方便对多个对象进行操作,我们就必须把这多个对象进行存储;
(2)存储多个对象,不能是一个基本的变量,而应该是一个容器类型的变量
(3)数组和StringBuffer都是容器类型,但它们有如下缺点:
1)StringBuffer的结果是一个字符串;
2)数组的长度是不可变的;
2.为了解决这个问题,java提供了集合这个容器
(1)集合的存在就是为了方便对多个对象的操作,集合是存储对象最常用的一种方式;
(2)集合是依赖对象而生的,所以无法存放值类型
3.为什么无法集合无法存放值类型?
(1)集合中存放的都是对象的引用,实际内容都在堆上面或者方法区里面,但是基本数据类型是在栈上分配空间的。随时都有可能会被收回。
(2)通过自动拆装箱,或者包装类都可以把基本类型转为引用类型,值类型放入集合的问题就解决了。
二.集合体系
1.java中的集合分成很多种类,有存储单个元素的,有存储键值对元素的,还有不能存重复元素的。2.虽然它们各自的数据结构不同,方法不同,但它们都是用来存储元素的。将它们的共性抽离出来,分成了两个流派,单例集合和双列集合,单列集合的老大是:Collection
3.关系图:
三.集合与数组的区别
1.长度区别数组的长度固定;
集合长度可变;
2.内容不同
数组存储的是同一种类型的元素;
而集合可以存储不同类型的元素;
3.元素的数据类型问题
数组可以存储基本数据类型,也可以存储引用数据类型;
集合只能存储引用类型;
四.集合总结
1.注意,这里List和Set的有序无序表示的是数据存储到集合的顺序,而不是对集合内元素的排序单列集合老大Collection
List(有序,可重复)ArrayList--
底层数据结构是数组,查询快,增删慢
线程不安全,效率高
Vector--
底层数据结构是数组,查询快,增删慢
线程安全,效率低
LinkedList--
底层数据结构是链表,查询慢,增删快
线程不安全,效率高
Set(无序,唯一)
HashSet--
底层数据结构是哈希表。
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
LinkedHashSet<E>
底层数据结构由链表和哈希表组成。
由链表保证元素有序。
由哈希表保证元素唯一。
TreeSet<E>
底层数据结构是红黑树。(是一种自平衡的二叉树)
如何保证元素唯一性呢?
根据比较的返回值是否是0来决定
如何保证元素的排序呢?
两种方式
自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
比较器排序(集合具备比较性)
让集合接收一个Comparator的实现类对象
Queue:暂时不予考虑
DK1.5新增,与上面两个集合类主要是的区分在于Queue主要用于存储数据,而不是处理数据。双列集合老大Map
A:Map集合的数据结构仅仅针对键有效,与值无关。B:存储的是键值对形式的元素,键唯一,值可重复。
HashMap
底层数据结构是哈希表。线程不安全,效率高
哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
LinkedHashMap
底层数据结构由链表和哈希表组成。
由链表保证元素有序。
由哈希表保证元素唯一。
HashTable
底层数据结构是哈希表。线程安全,效率低哈希表依赖两个方法:hashCode()和equals()
执行顺序:
首先判断hashCode()值是否相同
是:继续执行equals(),看其返回值
是true:说明元素重复,不添加
是false:就直接添加到集合
否:就直接添加到集合
最终:
自动生成hashCode()和equals()即可
TreeMap--
底层数据结构是红黑树。(是一种自平衡的二叉树)
如何保证元素唯一性呢?
根据比较的返回值是否是0来决定
如何保证元素的排序呢?
两种方式
自然排序(元素具备比较性)
让元素所属的类实现Comparable接口
比较器排序(集合具备比较性)
让集合接收一个Comparator的实现类对象
2:到底使用哪种集合呢?-->看需求
是否是键值对象形式:
是:Map
键是否需要排序:
是:TreeMap
否:HashMap
不知道,就使用HashMap。
否:Collection
元素是否唯一:
是:Set
元素是否需要排序:
是:TreeSet<E>
否:HashSet
不知道,就使用HashSet
否:List
要安全吗:
是:Vector
否:
增删多:LinkedList
查询多:ArrayList
不知道,就使用ArrayList
不知道,就使用ArrayList
3:集合的常见方法及遍历方式
Collection:
add()
remove()
contains()
iterator()
size()
遍历:
增强for
迭代器
|--List
get()
遍历:
普通for
|--Set
Map:
put()
remove()
containskey(),containsValue()
keySet()
get()
value()
entrySet()
size()
遍历:
根据键找值
根据键值对对象分别找键和值
拓展:集合的toString()方法源码解析
1.示例代码:分析该段代码为什么没有输出地址值Collection
c =
new ArrayList();
c.add("hello");
c.add("world");
c.add("java");
System.out.println(c);//"hello
world java"
2.为什么c输出的不是地址值呢?
A:Collection c = new ArrayList();
这是多态,所以输出c的toString()方法,其实是输出ArrayList的toString()
B:看ArrayList的toString()
而我们在ArrayList里面却没有发现toString()。
以后遇到这种情况,也不要担心,你认为有,它却没有,就应该去它父亲里面看看。
C:toString()的方法源码
public String toString() {
Iterator<E>
it = iterator();
//集合本身调用迭代器方法,得到集合迭代器
if
(! it.hasNext())
return
"[]";
StringBuilder sb
= new StringBuilder();
sb.append('[');
for
(;;) {//for这样写便是死循环
E e
= it.next();
//e=hello,world,java
sb.append(e
== this ?
"(this Collection)" : e);//三元表达式,e与调用本方法的集合对象本身作比较,e是否与集合本身对象相等.
if
(! it.hasNext())
//[hello, world, java]
return sb.append(']').toString();
sb.append(',').append('
');
}
}

相关文章推荐
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- Java基础(集合卷)--单列集合老大Collection
- 黑马程序员—java基础_集合Collection
- 黑马程序员-Java基础,Java集合Collection和Iterator接口
- java基础(五)--- 集合collection
- Java基础-集合Collection&List接口
- Java基础知识强化之集合框架笔记11:Collection集合之迭代器的原理及源码解析
- java基础.集合.collection和arrys.初识