27. Python对Mysql的操作(2)
2017-11-21 22:02
381 查看
1.游标
游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果
用户可以用SQL语句逐一从游标中获取记录,并赋给主变量,交由python进一步处理,一组主变量一次只能存放一条记录
仅使用主变量并不能完全满足SQL语句向应用程序输出数据的要求
游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。当决定对结果集进行处理时,必须声明一个指向该结果集的游标。
常用方法:
cursor(): 创建游标对象
close(): 关闭此游标对象
fetchone(): 得到结果集的下一行
fetchmany([size = cursor.arraysize]): 得到结果集的下几行
fetchall(): 得到结果集中剩下的所有行
excute(sql[, args]):执行一个数据库查询或命令
executemany (sql, args):执行多个数据库查询或命令
举例:
result1:
(1001L, u'li', u'M', datetime.date(2015, 4, 1))
result2:
((1002L, u'xian', u'M', datetime.date(2015, 4, 1)),)
result3:
((1003L, u'sheng', u'M', datetime.date(2015, 4, 1)),)
解释:
1,先通过 MySQLdb.connect(**db_config) 建立mysql连接对象
2,在通过 cus = cnx.cursor() 创建游标
3,fetchone():在最终搜索的数据中去一条数据
4,fetchmany(1) 在接下来的数据中在去1行的数据,这个数字可以自定义,定义多少就是在结果集中取多少条数据。
5,fetchall()是在所有的结果中搞出来所有的数据。
执行多条语句的sql时要注意,请阅读一下代码:
2.数据库连接池
python编程中可以使用MySQLdb进行数据库的连接及诸如 查询/插入/更新 等操作,但是每次连接mysql数据库请求时,都是独立的去请求访问,相当浪费资源,而且访问数量达到一定数量时,对mysql的性能会产生较大的影响。因此,实际使用中,通常会使用数据库的连接池技术,来访问数据库达到资源复用的目的。
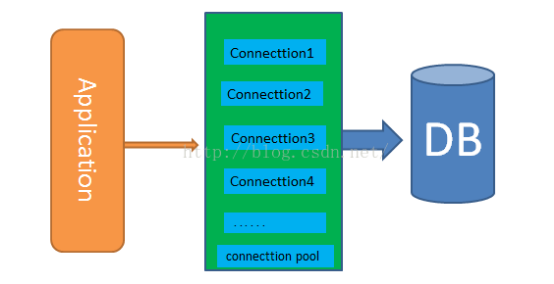
python的数据库连接池包 DBUtils:
DBUtils是一套Python数据库连接池包,并允许对非线程安全的数据库接口进行线程安全包装。
DBUtils来自Webware for Python。
DBUtils提供两种外部接口:
* PersistentDB :提供线程专用的数据库连接,并自动管理连接。
* PooledDB :提供线程间可共享的数据库连接,并自动管理连接。
下载地址: https://pypi.python.org/pypi/DBUtils/ 下载解压后,使用命令进行安装
# python setup.py install
或者使用
# pip install DBUtils
举例:
PooledDB的参数:
1. mincached,最少的空闲连接数,如果空闲连接数小于这个数,pool会创建一个新的连接
2. maxcached,最大的空闲连接数,如果空闲连接数大于这个数,pool会关闭空闲连接
3. maxconnections,最大的连接数,
4. blocking,当连接数达到最大的连接数时,在请求连接的时候,如果这个值是True,请求连接的程序会一直等待,直到当前连接数小于最大连接数,如果这个值是False,会报错,
5. maxshared 当连接数达到这个数,新请求的连接会分享已经分配出去的连接
总结:
在uwsgi中,每个http请求都会分发给一个进程,连接池中配置的连接数都是一个进程为单位的(即上面的最大连接数,都是在一个进程中的连接数),而如果业务中,一个http请求中需要的sql连接数不是很多的话(其实大多数都只需要创建一个连接),配置的连接数配置都不需要太大。
连接池对性能的提升表现在:
1.在程序创建连接的时候,可以从一个空闲的连接中获取,不需要重新初始化连接,提升获取连接的速度
2.关闭连接的时候,把连接放回连接池,而不是真正的关闭,所以可以减少频繁地打开和关闭连接
3.设计表结构
在操作数据库之前,先要设计数据库表结构,通过分析经典的学生、课程、成绩、老师几者之间的关系,先来分析各个主体之间都有什么属性,并确定表结构;
在实际开发过程中,根据业务需要和业务属性,设计不同的表结构;
以下是学生、课程、成绩、老师几者关系设计的表结构:
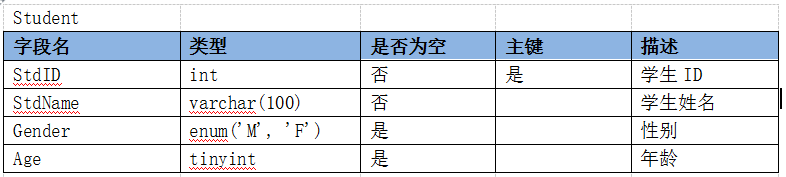

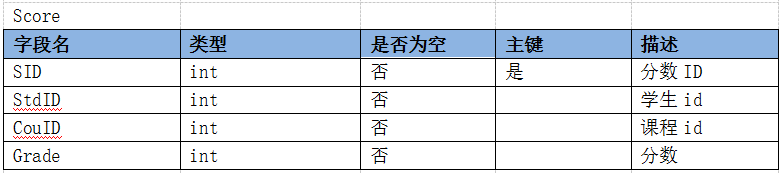

游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果
用户可以用SQL语句逐一从游标中获取记录,并赋给主变量,交由python进一步处理,一组主变量一次只能存放一条记录
仅使用主变量并不能完全满足SQL语句向应用程序输出数据的要求
游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。当决定对结果集进行处理时,必须声明一个指向该结果集的游标。
常用方法:
cursor(): 创建游标对象
close(): 关闭此游标对象
fetchone(): 得到结果集的下一行
fetchmany([size = cursor.arraysize]): 得到结果集的下几行
fetchall(): 得到结果集中剩下的所有行
excute(sql[, args]):执行一个数据库查询或命令
executemany (sql, args):执行多个数据库查询或命令
举例:
import MySQLdb
def connect_mysql():
db_config = {
'host': '192.168.48.128',
'port': 3306,
'user': 'xiang',
'passwd': '123456',
'db': 'python',
'charset': 'utf8'
}
cnx = MySQLdb.connect(**db_config)
return cnx
if __name__ == '__main__':
cnx = connect_mysql()
cus = cnx.cursor()
sql = '''select * from employees;'''
try:
cus.execute(sql)
result1 = cus.fetchone()
print('result1:')
print(result1)
result2 = cus.fetchmany(1)
print('result2:')
print(result2)
result3 = cus.fetchall()
print('result3:')
print(result3)
cus.close()
cnx.commit()
except Exception as e:
cnx.rollback()
print('error')
raise e
finally:
cnx.close()结果:result1:
(1001L, u'li', u'M', datetime.date(2015, 4, 1))
result2:
((1002L, u'xian', u'M', datetime.date(2015, 4, 1)),)
result3:
((1003L, u'sheng', u'M', datetime.date(2015, 4, 1)),)
解释:
1,先通过 MySQLdb.connect(**db_config) 建立mysql连接对象
2,在通过 cus = cnx.cursor() 创建游标
3,fetchone():在最终搜索的数据中去一条数据
4,fetchmany(1) 在接下来的数据中在去1行的数据,这个数字可以自定义,定义多少就是在结果集中取多少条数据。
5,fetchall()是在所有的结果中搞出来所有的数据。
执行多条语句的sql时要注意,请阅读一下代码:
from demon2 import connect_mysql
import MySQLdb
def connect_mysql():
db_config = {
"host": "192.168.48.128",
"port": 3306,
"user": "xiang",
"passwd": "123456",
"db": "python",
"charset": "utf8"
}
try:
cnx = MySQLdb.connect(**db_config)
except Exception as e:
raise e
return cnx
if __name__ == "__main__":
sql = "select * from tmp;"
sql1 = "insert into tmp(id) value (%s);"
param = []
for i in xrange(100, 130):
param.append([str(i)])
print(param)
cnx = connect_mysql()
cus = cnx.cursor()
print(dir(cus))
try:
cus.execute(sql)
cus.executemany(sql1, param)
# help(cus.executemany)
result1 = cus.fetchone()
print("result1")
print(result1)
result2 = cus.fetchmany(3)
print("result2")
print(result2)
result3 = cus.fetchall()
print("result3")
print(result3)
cus.close()
cnx.commit()
except Exception as e:
cnx.rollback()
raise e
finally:
cnx.close()2.数据库连接池
python编程中可以使用MySQLdb进行数据库的连接及诸如 查询/插入/更新 等操作,但是每次连接mysql数据库请求时,都是独立的去请求访问,相当浪费资源,而且访问数量达到一定数量时,对mysql的性能会产生较大的影响。因此,实际使用中,通常会使用数据库的连接池技术,来访问数据库达到资源复用的目的。
python的数据库连接池包 DBUtils:
DBUtils是一套Python数据库连接池包,并允许对非线程安全的数据库接口进行线程安全包装。
DBUtils来自Webware for Python。
DBUtils提供两种外部接口:
* PersistentDB :提供线程专用的数据库连接,并自动管理连接。
* PooledDB :提供线程间可共享的数据库连接,并自动管理连接。
下载地址: https://pypi.python.org/pypi/DBUtils/ 下载解压后,使用命令进行安装
# python setup.py install
或者使用
# pip install DBUtils
举例:
import MySQLdb
from DBUtils.PooledDB import PooledDB
db_config = {
"host": "192.168.48.128",
"port": 3306,
"user": "xiang",
"passwd": "123456",
"db": "python",
"charset": "utf8"
}
pool = PooledDB(MySQLdb, 5, **db_config) # 5默认为连接池里的最少连接数
conn = pool.connection() # 以后每次需要数据库连接就是用 connection() 函数获取连接就好了
cur = conn.cursor()
SQL = "select * from tmp;"
r = cur.execute(SQL)
r = cur.fetchall()
print(r)
cur.close()
conn.close()PooledDB的参数:
1. mincached,最少的空闲连接数,如果空闲连接数小于这个数,pool会创建一个新的连接
2. maxcached,最大的空闲连接数,如果空闲连接数大于这个数,pool会关闭空闲连接
3. maxconnections,最大的连接数,
4. blocking,当连接数达到最大的连接数时,在请求连接的时候,如果这个值是True,请求连接的程序会一直等待,直到当前连接数小于最大连接数,如果这个值是False,会报错,
5. maxshared 当连接数达到这个数,新请求的连接会分享已经分配出去的连接
总结:
在uwsgi中,每个http请求都会分发给一个进程,连接池中配置的连接数都是一个进程为单位的(即上面的最大连接数,都是在一个进程中的连接数),而如果业务中,一个http请求中需要的sql连接数不是很多的话(其实大多数都只需要创建一个连接),配置的连接数配置都不需要太大。
连接池对性能的提升表现在:
1.在程序创建连接的时候,可以从一个空闲的连接中获取,不需要重新初始化连接,提升获取连接的速度
2.关闭连接的时候,把连接放回连接池,而不是真正的关闭,所以可以减少频繁地打开和关闭连接
3.设计表结构
在操作数据库之前,先要设计数据库表结构,通过分析经典的学生、课程、成绩、老师几者之间的关系,先来分析各个主体之间都有什么属性,并确定表结构;
在实际开发过程中,根据业务需要和业务属性,设计不同的表结构;
以下是学生、课程、成绩、老师几者关系设计的表结构:

相关文章推荐
- Python(SQLAlchemy-ORM)模块之mysql操作
- Python3.x的mysqlclient的安装、Python操作mysql,python连接MySQL数据库,python创建数据库表,带有事务的操作,CRUD
- python操作mysql
- python操作mysql
- python操作三大主流数据库(2)python操作mysql②python对mysql进行简单的增删改查
- python 操作mysql
- Python操作MySQL的一个报错:IndexError: out of range
- Python 操作mysql
- 使用Python操作SQL数据库(mysql)
- Python操作MySQL之pymysql
- python操作mysql
- 『python工作』mysql 数据库的一些操作数据库的函数
- Python操作Mysql
- 用Python操作mysql
- Python操作MySQL乱码问题解决
- Python对mysql的操作四
- Python使用MySQLdb操作MySQL
- python对mysql.connector的简单封装,读改增删基本操作
- Python MYSQL - tiny ETL tool - 文件操作和数据库操作
- python自动化--模块操作之re、MySQL、Excel