如何同步TableStore数据到Elasticsearch
2017-11-21 14:38
204 查看
点击有惊喜
图书馆Q是一家大型图书馆,图书馆藏书众多,纸质图书600多万册,电子图书7000多万册,总数有八千多万册,这些图书之前都是人工检索维护的,现在需要做一个系统来存储管理这些图书信息。
需求如下:
图书总量目前八千多万册,考虑到未来二十年的增长,需要系统能支持一亿的存储量。
图书信息很重要,不能接受丢失发生。
图书的名字和作者名字需要支持模糊搜索。
每本书的属性最多有一百多个,且不固定,不同类型的图书的属性列差异较大。且未来可能会新增属性列。
根据上面这些需求特点,要完成这个管理系统,需要两类系统支持:
分布式NoSQL数据库:解决两亿存储量的问题,解决属性列较多且不固定的问题,解决可靠性要求高的问题。
搜索系统:解决固定列模糊搜索的需求。
如果使用阿里云产品,那么对应的产品就是:
Table Store:分布式NoSQL数据库。
Elasticsearch:搜索系统,支持模糊搜索。
在管理系统中使用上述两个系统的时候,目前需要双写,当新增一本书的时候,需要将详细书本信息写入Table Store,将书本ID和作者,书名写入Elasticsearch,并且对书名,作者建索引。查询的时候,如果是根据书本ID,则直接查询Table Store。如果是根据书名模糊查询,则先查Elasticsearch,获取到匹配的书本的ID后,再到Table Store中查询详细信息。
如果Table Store到Elasticsearch有自动同步通道,那么只需要将新书信息写入Table Store即可,不再需要写Elasticsearch。减少了一次写入操作,且不用再考虑数据一致性问题,系统架构大大简化。那么如何才能实现这个自动同步通道呢?
类似于上面的场景,有很多系统都有这样的需求:拥有PB级海量数据需要持久化存储,同时有一两个字段需要做模糊查询,比如姓名,手机号码等,目前很多解决方案需要双写分布式数据库和Elasticsearch,但这样不仅会带来开发、运维复杂度,而且还有数据不一致的问题。
针对上述问题,Table Store团队联合数据集成(CDP)和Elasticsearch团队上线了近实时的数据同步方案,用户只需要将数据写入Table Store,Table Store会负责将数据在10分钟内自动发送给Elasticsearch建索引。
Table Store:阿里云分布式NoSQL数据库,专注于海量数据的存储服务,目前单表可支持10PB级,10万亿行以上的数据量,且数据量增大后性能仍然保持稳定。Table Store Stream功能是一种增量实时通道服务,类似于MySQL的binlog,可以通过Stream接口实时读取到最新的变化数据(Put/Update/Delete)。
数据集成 :阿里云数据管理平台,支持数据同步等众多数据功能。
Elasticsearch :阿里云Elasticsearch是刚推出的一项新服务,提供基于开源Elasticsearch及商业版X-Pack插件,致力于数据分析、数据搜索等场景服务。在开源Elasticsearch基础上提供企业级权限管控、安全监控告警、自动报表生成等功能。
三种产品在新解决方案中的角色如下:
由于Table Store和Elasticsearch不是完全对等的产品,所以如果需要将数据导入Elasticsearch,那么在使用Table Store的时候有一些注意的地方:
Table Store主键列个数:
目前Table Store最大支持4个主键列,而Elasticsearch只支持一个,所以Table Store的表设计时只能使用一个主键列,如果之前有多个主键列,可以将多个主键列的值转换成String,然后拼接成一个主键列。
Table Store数据变化类型:
仅支持PUT(新增),UPDATE(更新)两种操作。
不支持DELETE操作。
Table Store多版本:
仅支持单版本,不支持多版本
Elasticsearch:
版本:支持阿里云和开源的5.*.*版本。
延时:
目前使用的是周期调度,每隔5分钟调度一次,再加上插件中有5分钟延迟,同步总延迟在5~10分钟。
Table Store:
登陆Table Store首页:https://www.aliyun.com/product/ots/
点击开通。
新建实例和表,表需要开通Stream,有效时间可以选择24小时。
Table Store支持按预留CU和按量付费两种收费模式,如果创建表时指定读写CU都为0则表示为按量付费,后期如果没有使用则不收费。且目前每月有10GB,1000万CU的免费额度。
Table Store中表需要开通Stream功能。
数据集成
登陆DataWorks绑定AK。
然后创建项目即可。
注意:子账号不能创建项目,只能被主账号授权。
Elasticsearch
登陆Elasticsearch首页:https://data.aliyun.com/product/elasticsearch。
点击立即购买,购买时的VPC必须和之前购买的ECS在同一个VPC环境内部。
根据数据量预估,购买相应的实例大小。
目前收费是按实例规格收费。
写
Table Store:PutRow/BatchWriteRow接口写入数据
Elasticsearch:无须写入
读
Elasticsearch:搜索到请求结果后,拿到每个doc的_id字段值。
Table Store:Elasticsearch中的_id字段就是Table Store中的主键值,获取到一系列_id值后,使用Table Store的BatchGetRow可以查询到完整数据。
整个同步流程应该包括下面两个步骤:
导出Table Store的全量数据到Elasticsearch,并且记录开始时间T1。
等全量导出结束后,再开始同步增量数据,增量数据开始同步的时间是T1。
对于全量导出,需要使用otsreader插件,配置中的Range使用INF_MIN到INF_MAX,也就是导出所有数据。
对于增量同步,需要配置起始时间和结束时间为一个变量,在调度周期配置的时候配置起始时间必须小于等于T1,否则可能会有数据丢失发生。
我们下面会以增量同步为例来介绍如何配置增量同步任务。
无须配置
无须配置
如果已经创建了Table Store的数据源,则可以跳过这一步。
如果不希望创建数据源,也可以在配置页面配置相应的endpoint,instanceName,AccessKeyID和AccessKeySecret。如果希望创建,则按照下面步骤操作。
登录阿里云大数据开发套件:数据源地址。
单击左侧 离线同步 > 数据源。
在数据源配置页面,选择右上角 新增数据源 ,会有一个弹出框。
按照说明填写:
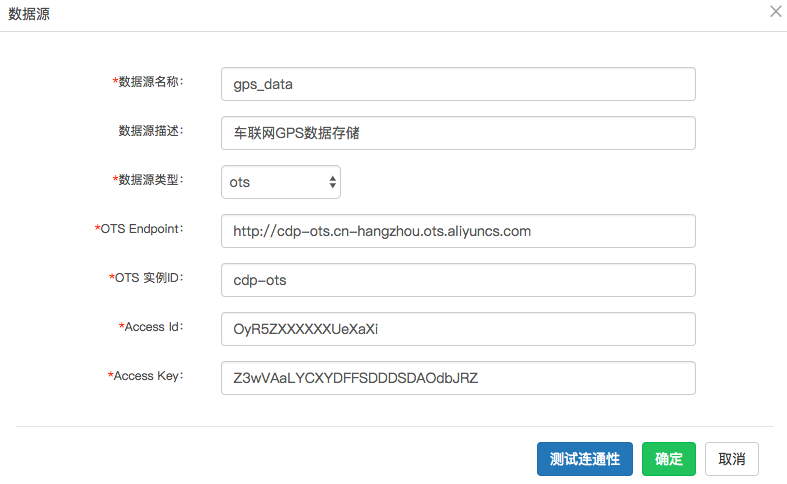
数据源名称:填写一个数据源标识符,比如车联网。
数据源描述:填入描述符,比如:车联网GPS数据存储。
数据源类型:选择 ots ,ots是Table Store曾用名。
OTS Endpoint:填入TableStore 实例页面的实例地址,如果Table Store的实例和目标产品(比如Elasticsearch)在同一个region,则可以填入私网地址,否则需要填入公网地址,不能填入VPC地址。
OTS 实例ID:填入Table Store的实例名称。
Access Id:填入阿里云网站的AccessKeyID。
Access Key:填入阿里云网站AccessKeyID对应的AccessKeySecret。
点击 测试连通性 ,如果成功则会在右上角提示:测试连接成功。 如果失败,点击endpoint是否配置正确,如果仍然无法解决,提工单联系数据集成。
填好后的页面类似下面这样:
单击确定,数据源创建成功,此时在数据源页面会出现一个新的数据源信息;

单击数据集成地址,进入数据集成的页面,会出现模式选择:

单击 脚本模式 ,弹出一个 导入模板 配置。
在导入模板配置里面:
来源类型:OTS Stream
目标类型:Elasticsearch
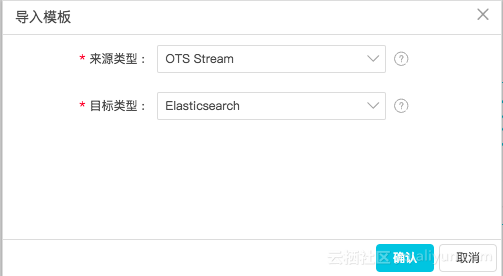
单击确认,则进入配置界面。
想了解更多请点击

图书馆
图书馆Q是一家大型图书馆,图书馆藏书众多,纸质图书600多万册,电子图书7000多万册,总数有八千多万册,这些图书之前都是人工检索维护的,现在需要做一个系统来存储管理这些图书信息。需求如下:
图书总量目前八千多万册,考虑到未来二十年的增长,需要系统能支持一亿的存储量。
图书信息很重要,不能接受丢失发生。
图书的名字和作者名字需要支持模糊搜索。
每本书的属性最多有一百多个,且不固定,不同类型的图书的属性列差异较大。且未来可能会新增属性列。
根据上面这些需求特点,要完成这个管理系统,需要两类系统支持:
分布式NoSQL数据库:解决两亿存储量的问题,解决属性列较多且不固定的问题,解决可靠性要求高的问题。
搜索系统:解决固定列模糊搜索的需求。
如果使用阿里云产品,那么对应的产品就是:
Table Store:分布式NoSQL数据库。
Elasticsearch:搜索系统,支持模糊搜索。
在管理系统中使用上述两个系统的时候,目前需要双写,当新增一本书的时候,需要将详细书本信息写入Table Store,将书本ID和作者,书名写入Elasticsearch,并且对书名,作者建索引。查询的时候,如果是根据书本ID,则直接查询Table Store。如果是根据书名模糊查询,则先查Elasticsearch,获取到匹配的书本的ID后,再到Table Store中查询详细信息。
如果Table Store到Elasticsearch有自动同步通道,那么只需要将新书信息写入Table Store即可,不再需要写Elasticsearch。减少了一次写入操作,且不用再考虑数据一致性问题,系统架构大大简化。那么如何才能实现这个自动同步通道呢?
目标
类似于上面的场景,有很多系统都有这样的需求:拥有PB级海量数据需要持久化存储,同时有一两个字段需要做模糊查询,比如姓名,手机号码等,目前很多解决方案需要双写分布式数据库和Elasticsearch,但这样不仅会带来开发、运维复杂度,而且还有数据不一致的问题。针对上述问题,Table Store团队联合数据集成(CDP)和Elasticsearch团队上线了近实时的数据同步方案,用户只需要将数据写入Table Store,Table Store会负责将数据在10分钟内自动发送给Elasticsearch建索引。
相关产品
Table Store:阿里云分布式NoSQL数据库,专注于海量数据的存储服务,目前单表可支持10PB级,10万亿行以上的数据量,且数据量增大后性能仍然保持稳定。Table Store Stream功能是一种增量实时通道服务,类似于MySQL的binlog,可以通过Stream接口实时读取到最新的变化数据(Put/Update/Delete)。数据集成 :阿里云数据管理平台,支持数据同步等众多数据功能。
Elasticsearch :阿里云Elasticsearch是刚推出的一项新服务,提供基于开源Elasticsearch及商业版X-Pack插件,致力于数据分析、数据搜索等场景服务。在开源Elasticsearch基础上提供企业级权限管控、安全监控告警、自动报表生成等功能。
三种产品在新解决方案中的角色如下:
| 产品 | Table Store | 数据集成 | Elasticsearch |
|---|---|---|---|
| 角色 | 数据存储 | 数据同步通道 | 查询增强 |
限制
由于Table Store和Elasticsearch不是完全对等的产品,所以如果需要将数据导入Elasticsearch,那么在使用Table Store的时候有一些注意的地方:Table Store主键列个数:
目前Table Store最大支持4个主键列,而Elasticsearch只支持一个,所以Table Store的表设计时只能使用一个主键列,如果之前有多个主键列,可以将多个主键列的值转换成String,然后拼接成一个主键列。
Table Store数据变化类型:
仅支持PUT(新增),UPDATE(更新)两种操作。
不支持DELETE操作。
Table Store多版本:
仅支持单版本,不支持多版本
Elasticsearch:
版本:支持阿里云和开源的5.*.*版本。
延时:
目前使用的是周期调度,每隔5分钟调度一次,再加上插件中有5分钟延迟,同步总延迟在5~10分钟。
开通服务
Table Store:登陆Table Store首页:https://www.aliyun.com/product/ots/
点击开通。
新建实例和表,表需要开通Stream,有效时间可以选择24小时。
Table Store支持按预留CU和按量付费两种收费模式,如果创建表时指定读写CU都为0则表示为按量付费,后期如果没有使用则不收费。且目前每月有10GB,1000万CU的免费额度。
Table Store中表需要开通Stream功能。
数据集成
登陆DataWorks绑定AK。
然后创建项目即可。
注意:子账号不能创建项目,只能被主账号授权。
Elasticsearch
登陆Elasticsearch首页:https://data.aliyun.com/product/elasticsearch。
点击立即购买,购买时的VPC必须和之前购买的ECS在同一个VPC环境内部。
根据数据量预估,购买相应的实例大小。
目前收费是按实例规格收费。
使用方式
写Table Store:PutRow/BatchWriteRow接口写入数据
Elasticsearch:无须写入
读
Elasticsearch:搜索到请求结果后,拿到每个doc的_id字段值。
Table Store:Elasticsearch中的_id字段就是Table Store中的主键值,获取到一系列_id值后,使用Table Store的BatchGetRow可以查询到完整数据。
同步流程
整个同步流程应该包括下面两个步骤:导出Table Store的全量数据到Elasticsearch,并且记录开始时间T1。
等全量导出结束后,再开始同步增量数据,增量数据开始同步的时间是T1。
对于全量导出,需要使用otsreader插件,配置中的Range使用INF_MIN到INF_MAX,也就是导出所有数据。
对于增量同步,需要配置起始时间和结束时间为一个变量,在调度周期配置的时候配置起始时间必须小于等于T1,否则可能会有数据丢失发生。
我们下面会以增量同步为例来介绍如何配置增量同步任务。
Table Store配置
无须配置
Elasticsearch配置
无须配置
数据集成配置
1. 创建数据源(可选)
如果已经创建了Table Store的数据源,则可以跳过这一步。如果不希望创建数据源,也可以在配置页面配置相应的endpoint,instanceName,AccessKeyID和AccessKeySecret。如果希望创建,则按照下面步骤操作。
登录阿里云大数据开发套件:数据源地址。
单击左侧 离线同步 > 数据源。
在数据源配置页面,选择右上角 新增数据源 ,会有一个弹出框。
按照说明填写:
数据源名称:填写一个数据源标识符,比如车联网。
数据源描述:填入描述符,比如:车联网GPS数据存储。
数据源类型:选择 ots ,ots是Table Store曾用名。
OTS Endpoint:填入TableStore 实例页面的实例地址,如果Table Store的实例和目标产品(比如Elasticsearch)在同一个region,则可以填入私网地址,否则需要填入公网地址,不能填入VPC地址。
OTS 实例ID:填入Table Store的实例名称。
Access Id:填入阿里云网站的AccessKeyID。
Access Key:填入阿里云网站AccessKeyID对应的AccessKeySecret。
点击 测试连通性 ,如果成功则会在右上角提示:测试连接成功。 如果失败,点击endpoint是否配置正确,如果仍然无法解决,提工单联系数据集成。
填好后的页面类似下面这样:
单击确定,数据源创建成功,此时在数据源页面会出现一个新的数据源信息;
2. 创建导出任务
单击数据集成地址,进入数据集成的页面,会出现模式选择: 单击 脚本模式 ,弹出一个 导入模板 配置。
在导入模板配置里面:
来源类型:OTS Stream
目标类型:Elasticsearch
单击确认,则进入配置界面。
想了解更多请点击

相关文章推荐
- 如何把数据快速批量添加到Elasticsearch中
- Mongo同步数据到Elasticsearch
- 与服务器同步数据时如何节约流量
- 通过HBase Observer同步数据到ElasticSearch
- 面向高稳定,高性能之-Hbase数据实时同步到ElasticSearch(之一)
- OGG "Loading data from file to Replicat"table静态数据同步配置过程
- 如何删除表中所有数据。delete from tablename与Truncate Table tablename 区别
- 页面使用$.dataTable()的时候,如何获取Table一行的数据
- Elasticsearch与MongoDB 数据同步及分布式集群搭建 (二)
- js如何获取table中动态生成的数据
- elasticsearch2.3.2服务搭建、管理及实时同步mysql数据
- 如何将日志服务的数据秒级同步到表格存储
- 如何在elasticsearch中查看Logstash打到elasticsearch的数据
- bootstrap-table.js如何根据单元格数据不同显示不同的字体的颜色
- R语言如何将读写大数据(RData) Large matrix table
- 如何实现集群多个节点之间的数据同步
- logstash-out-mongodb实现elasticsearch到Mongodb的数据同步
- 对:通过HBase Observer同步数据到ElasticSearch的使用情况
- 自制搜索(elasticsearch安装,mongo-connector同步数据,python操作)
- Elasticsearch中的索引数据Index同步到Mongodb中的集合collection中