R语言:使用rvest包抓取新浪财经A股交易数据
2017-11-21 10:09
246 查看
R语言网络爬虫工具中比较常用的包有RCurl、XML、rvest等,本文以新浪财经频道A股交易数据的抓取为例简单总结一下rvest包的用法。
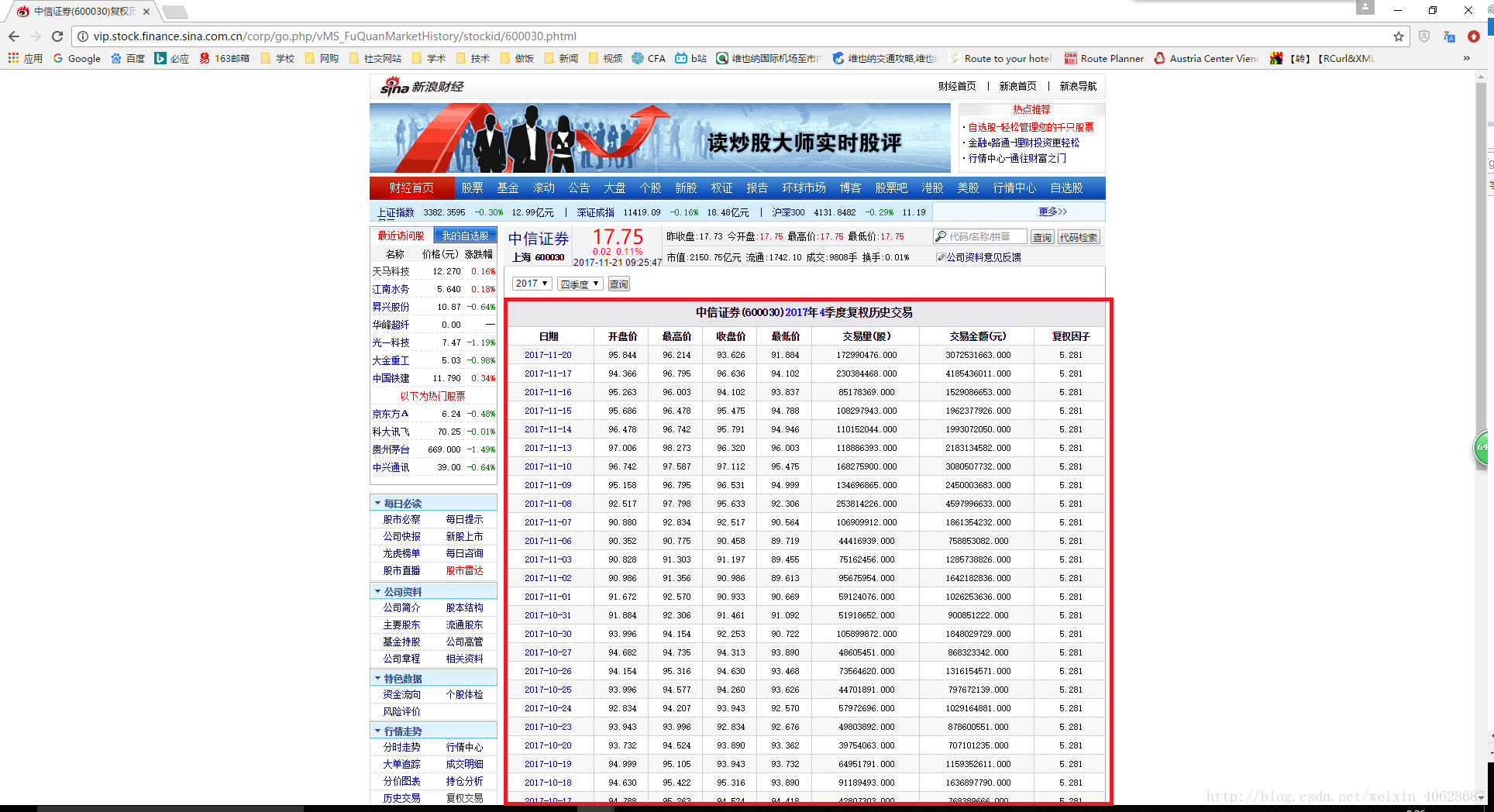
首先介绍一下我们要抓取的对象,我们以“中信证券(600030)”为例,抓取其日度交易数据。url地址为http://vip.stock.finance.sina.com.cn/corp/go.php/vMS_FuQuanMarketHistory/stockid/600030.phtml,如下图所示,我们需要的数据就是红框标出的表格:
接下来介绍一下我们使用的工具——rvest包,它主要包含read_html、html_form、html_nodes、html_session、html_table、html_text等函数,本文将着重介绍read_html、html_nodes、html_table和html_text的用法。 read_html(x,..., encoding = "") read_html函数用于读取整个网页或者本地数据。其主要参数为: x 可以是url地址、本地路径、含有html的字符串或者httr响应。 encoding 是文件使用的编码。install.packages('rvest')
library(rvest)url <- 'http://vip.stock.finance.sina.com.cn/corp/go.php/vMS_FuQuanMarketHistory/stockid/600030.phtml'
website <- read_html(url)
以上代码即将该网页的所有源代码储存在website中,website是一个html文件,接下来我们可以使用html_nodes、html_table、html_text等函数对其进行处理。
html_table(x,header = NA, trim = TRUE, fill = FALSE, dec = ".")
html_table可以将网页中表格形式的数据直接提取出来。其主要参数为:
x 一个节点或一个文件,可以是使用read_html抓下来的网页。
header 是否将第一行设为标题;如果取默认值NA,则在第一行包含<th>标签时将第一行设为标题;
trim 若为TRUE,自动将表格中数据开头和结尾处的空格去掉;
fill 若为TRUE,,将使用NA自动填充不满最大列数的行。
dec 设置代表小数点的符号。
我们使用html_table对抓取下来的网页website进行处理,得到一个包含网页上的所有表格的list

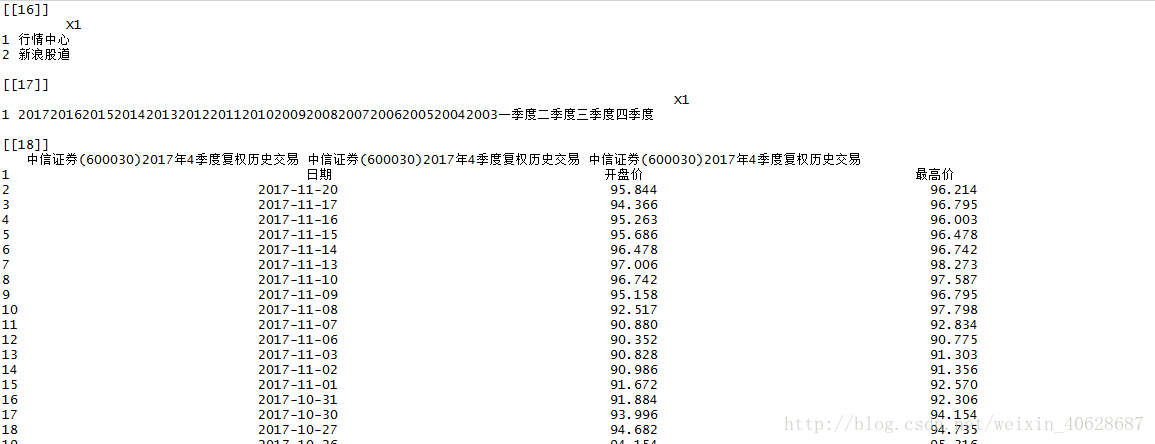
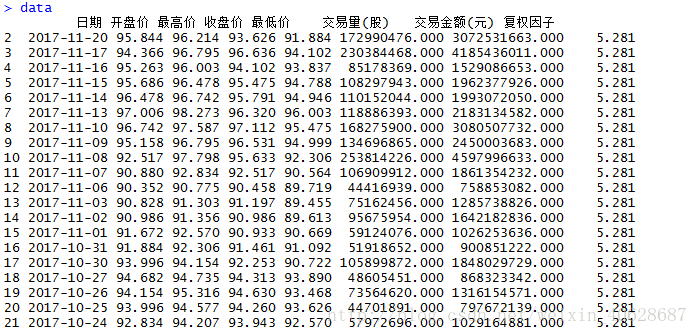
可以看到,list的最后一个元素即是我们要提取的股票复权交易数据,只是这里的第一行并没有自动提取为标题,需要后期我们自己调整。
这样我们就学会了使用rvest包抓取网页上的表格。
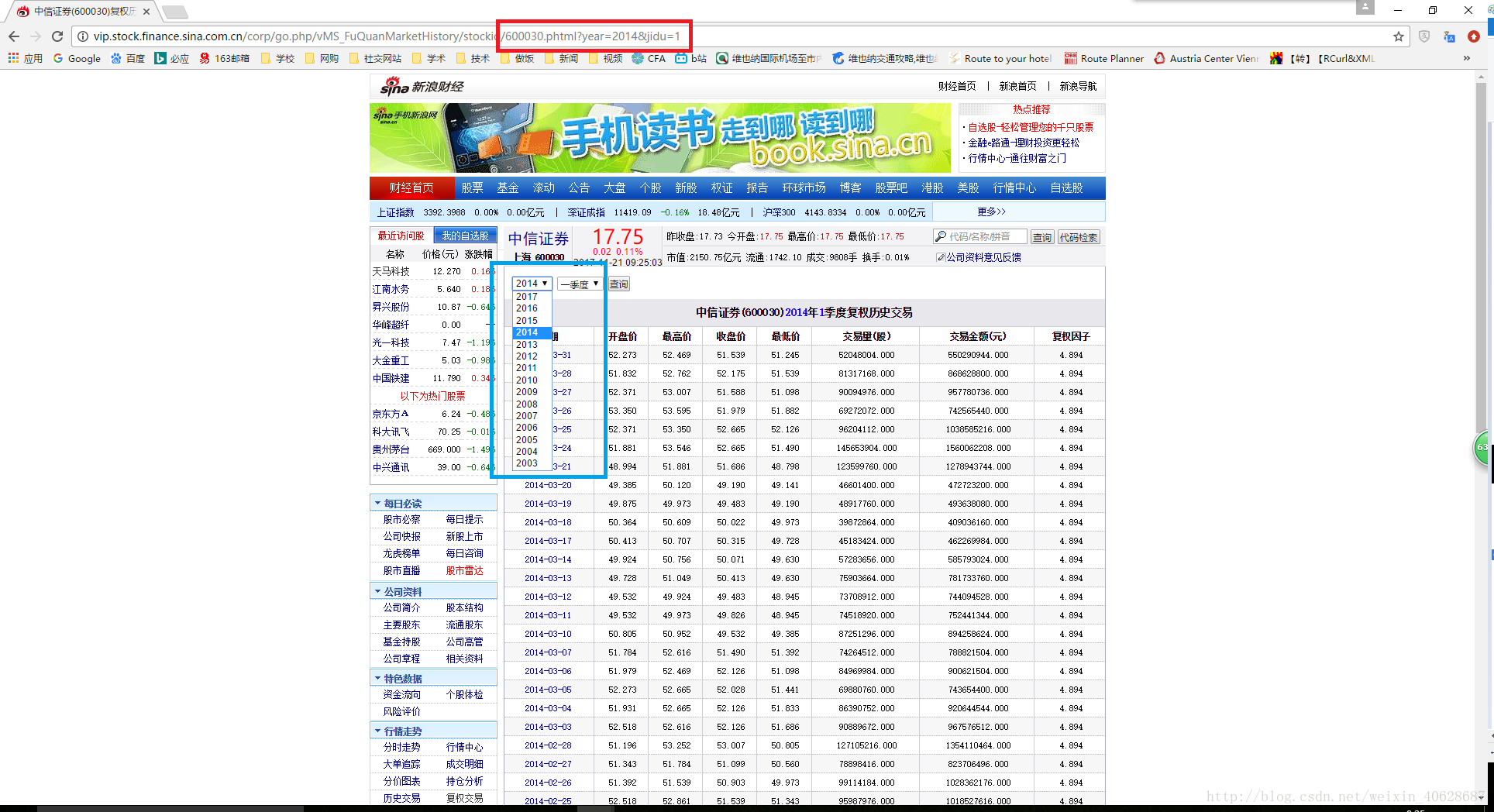
但是以上操作仅仅抓到了中信证券在2017年第四季度的交易数据,而通过点击下图红框中的时间选项我们得知,新浪财经公布了中信证券自2003年上市以来的所有交易数据,那么如何才能方便快捷的将所有年份的数据都抓取下来?
我们首先观察到,当在下图蓝框内选取不同时段时,url地址也会出现相应的变化(下图红框所示),这样我们就可以通过设计循环遍历所有的年份和季度,将所有的交易数据都抓取下来,合并数据,最终得到中信证券自上市以来的所有交易数据。思路没有问题,难点在于,不同的股票上市时间不同,如何确定需要遍历的年份?我们点开下图 蓝框所示的时间选项,在出现的下拉菜单中出现了所有的年份(2003年-2017年),我们可不可以从网页上直接将这15个年份抓取下来?接下来,我们用html_nodes和html_text两个函数将其实现。
html_nodes(x, css, xpath)
html_nodes用于通过css或xPath定位将网页中特定的节点筛选出来。其主要参数为:
x 一个节点或一个文件,可以是使用read_html抓下来的网页。
css,xpath 所选节点的定位条件。
在这里我们使用xPath进行定位,将所有的年份抓取下来:
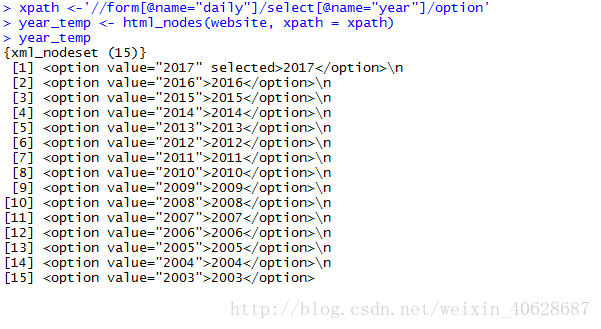
可以看到抓取下来的year_temp是网页源码,而我们只需要其中的数字,接下来可以使用html_text将这些数字(也就是标签文字)提取出来。
html_text(x, trim = FALSE)
html_text用于将节点或网页上的文字标签提取出来。其主要参数为:
x 一个节点或一个文件,可以是使用read_html抓下来的网页。
trim 如果为TRUE,则自动去掉标签中开头和结尾处的空格。
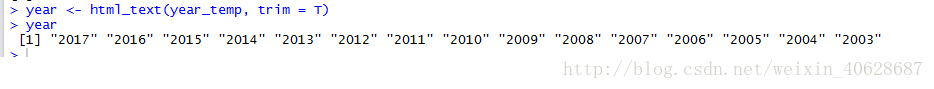
有了年份信息之后,构建一个循环就可以将中信证券的所有交易数据抓取下来:
大家一定好奇上文中的xpath,也就是“//form[@name="daily"]/select[@name="year"]/option”是什么意思,这个定位条件是怎么构造出来的。下面我们使用Chrome调出网页源码进行分析,解答这个疑惑。
首先在我们要抓取的网页下,点击F12键,即可出现源代码窗口,这时点击下图黑框所示的按钮,然后将鼠标移至原始网页中我们想要定位的位置(下图红框所示)单击,此时在源码窗口即自动显示出点击目标的源码(下图蓝框所示)。
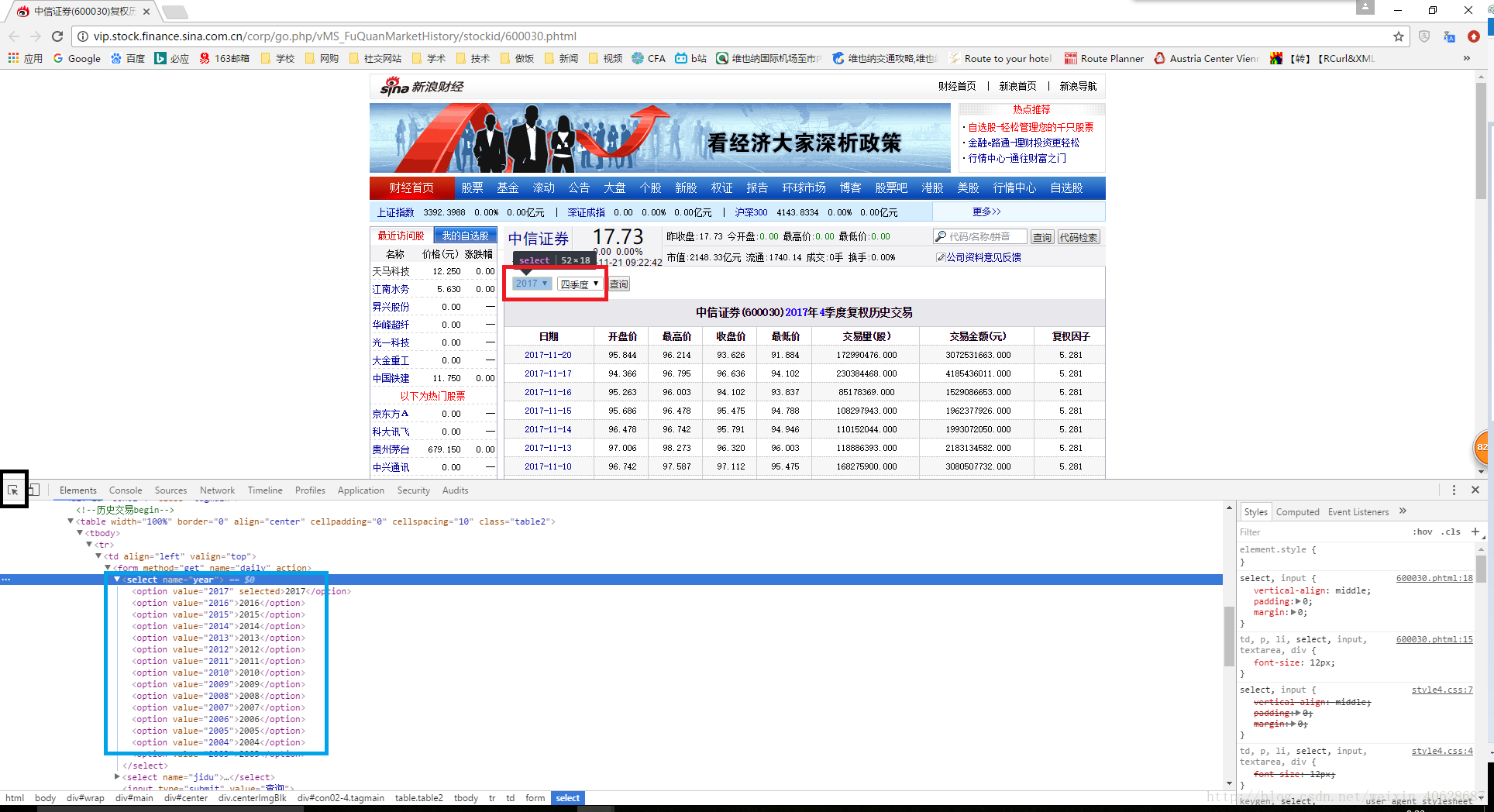
我们可以看到,我们需要的年份数据位于form节点的select子节点的option子节点上,因此我们可以构建xpath如下:
xpath <-“//form[@name="daily"]/select[@name="year"]/option”
其中开头的//表示网页中所有节点,之后的form[@name="daily"]表示“name”标签为“daily”的form节点,/select[@name="year"]表示form节点下“name”标签为“year”的select子节点,/option表示select节点下option子节点。
首先介绍一下我们要抓取的对象,我们以“中信证券(600030)”为例,抓取其日度交易数据。url地址为http://vip.stock.finance.sina.com.cn/corp/go.php/vMS_FuQuanMarketHistory/stockid/600030.phtml,如下图所示,我们需要的数据就是红框标出的表格:
接下来介绍一下我们使用的工具——rvest包,它主要包含read_html、html_form、html_nodes、html_session、html_table、html_text等函数,本文将着重介绍read_html、html_nodes、html_table和html_text的用法。 read_html(x,..., encoding = "") read_html函数用于读取整个网页或者本地数据。其主要参数为: x 可以是url地址、本地路径、含有html的字符串或者httr响应。 encoding 是文件使用的编码。install.packages('rvest')
library(rvest)url <- 'http://vip.stock.finance.sina.com.cn/corp/go.php/vMS_FuQuanMarketHistory/stockid/600030.phtml'
website <- read_html(url)
以上代码即将该网页的所有源代码储存在website中,website是一个html文件,接下来我们可以使用html_nodes、html_table、html_text等函数对其进行处理。
html_table(x,header = NA, trim = TRUE, fill = FALSE, dec = ".")
html_table可以将网页中表格形式的数据直接提取出来。其主要参数为:
x 一个节点或一个文件,可以是使用read_html抓下来的网页。
header 是否将第一行设为标题;如果取默认值NA,则在第一行包含<th>标签时将第一行设为标题;
trim 若为TRUE,自动将表格中数据开头和结尾处的空格去掉;
fill 若为TRUE,,将使用NA自动填充不满最大列数的行。
dec 设置代表小数点的符号。
我们使用html_table对抓取下来的网页website进行处理,得到一个包含网页上的所有表格的list
table <- html_table(website, fill = TRUE) table
可以看到,list的最后一个元素即是我们要提取的股票复权交易数据,只是这里的第一行并没有自动提取为标题,需要后期我们自己调整。
data_temp <- table[[18]] data <- data_temp[2:nrow(data_temp), ] colnames(data) <- data_temp[1, ] data
这样我们就学会了使用rvest包抓取网页上的表格。
但是以上操作仅仅抓到了中信证券在2017年第四季度的交易数据,而通过点击下图红框中的时间选项我们得知,新浪财经公布了中信证券自2003年上市以来的所有交易数据,那么如何才能方便快捷的将所有年份的数据都抓取下来?
我们首先观察到,当在下图蓝框内选取不同时段时,url地址也会出现相应的变化(下图红框所示),这样我们就可以通过设计循环遍历所有的年份和季度,将所有的交易数据都抓取下来,合并数据,最终得到中信证券自上市以来的所有交易数据。思路没有问题,难点在于,不同的股票上市时间不同,如何确定需要遍历的年份?我们点开下图 蓝框所示的时间选项,在出现的下拉菜单中出现了所有的年份(2003年-2017年),我们可不可以从网页上直接将这15个年份抓取下来?接下来,我们用html_nodes和html_text两个函数将其实现。
html_nodes(x, css, xpath)
html_nodes用于通过css或xPath定位将网页中特定的节点筛选出来。其主要参数为:
x 一个节点或一个文件,可以是使用read_html抓下来的网页。
css,xpath 所选节点的定位条件。
在这里我们使用xPath进行定位,将所有的年份抓取下来:
xpath <-'//form[@name="daily"]/select[@name="year"]/option'
year_temp <- html_nodes(website, xpath = xpath)
year_temp
可以看到抓取下来的year_temp是网页源码,而我们只需要其中的数字,接下来可以使用html_text将这些数字(也就是标签文字)提取出来。
html_text(x, trim = FALSE)
html_text用于将节点或网页上的文字标签提取出来。其主要参数为:
x 一个节点或一个文件,可以是使用read_html抓下来的网页。
trim 如果为TRUE,则自动去掉标签中开头和结尾处的空格。
year <- html_text(year_temp, trim = T) year
有了年份信息之后,构建一个循环就可以将中信证券的所有交易数据抓取下来:
data <- as.data.frame(matrix(NA, 1, 8))
colnames(data) <- c('日期', '开盘价', '最高价', '收盘价', '最低价', '交易量(股)'
4000
, ' 交易金额(元)', '复权因子')
for (i in year) {
for (j in 4:1) {
url_temp <- paste('http://vip.stock.finance.sina.com.cn/corp/go.php/vMS_FuQuanMarketHistory/stockid/600030.phtml?year=', i, '&jidu=', j, sep = '')
website <- read_html(url_temp)
table <- html_table(website, fill = TRUE)
data_temp <- table[[18]]
data_temp <- data_temp[2:nrow(data_temp), ]
colnames(data_temp) <- colnames(data)
data <- rbind(data, data_temp)
}
}
# 去掉第一行的缺失值data <- data[-1, ]
data
大家一定好奇上文中的xpath,也就是“//form[@name="daily"]/select[@name="year"]/option”是什么意思,这个定位条件是怎么构造出来的。下面我们使用Chrome调出网页源码进行分析,解答这个疑惑。
首先在我们要抓取的网页下,点击F12键,即可出现源代码窗口,这时点击下图黑框所示的按钮,然后将鼠标移至原始网页中我们想要定位的位置(下图红框所示)单击,此时在源码窗口即自动显示出点击目标的源码(下图蓝框所示)。
我们可以看到,我们需要的年份数据位于form节点的select子节点的option子节点上,因此我们可以构建xpath如下:
xpath <-“//form[@name="daily"]/select[@name="year"]/option”
其中开头的//表示网页中所有节点,之后的form[@name="daily"]表示“name”标签为“daily”的form节点,/select[@name="year"]表示form节点下“name”标签为“year”的select子节点,/option表示select节点下option子节点。

相关文章推荐
- 如何使用沃顿研究数据中心(WRDS,CRSP)查询美股历史交易数据(R语言的调用方法以及代码示例)
- 使用R语言和XML包抓取网页数据-Scraping data from web pages in R with XML package
- R语言:使用rvest包进行数据简单抓取
- 使用HtmlAgilityPack批量抓取网页数据
- 从新浪财经上下载交易明细数据并统计每天的买卖笔数(shell 命令行)
- 使用HtmlAgilityPack XPath 表达式抓取博客园数据的实现代码
- 构建快速数据交易系统的思考(1)使用DataDirect
- 使用HtmlAgilityPack批量抓取网页数据
- Android使用LocalSocket抓取数据
- Android使用LocalSocket抓取数据
- 使用phantomjs抓取ITC和android market的安装统计数据 | 蓝色的华
- 分享:Python使用cookielib和urllib2模拟登陆新浪微博并抓取数据
- 使用正则表达式抓取博客园列表数据
- 使用工具时正常,但在抓取过程中很久都没有更新数据的问题分析
- 使用HtmlAgilityPack XPath 表达式抓取博客园数据
- 使用HtmlAgilityPack批量抓取网页数据
- 使用HtmlAgilityPack批量抓取网页数据
- 使用System.Text.RegularExpression中的API实现网页数据的抓取
- 如何处理在使用正则表达式抓取数据是栈溢出问题
- 使用System.Text.RegularExpression中的API实现网页数据的抓取