译:HBaseWD:通过顺序RowKey避免HBase RegionServer热点问题
2017-11-19 18:11
369 查看
在HBase领域,RegionServer热点是一个共性问题。用一句话来描述HBase热点:以顺序RowKey记录数据时,可以通过startRowkey和endRowKey区间最高效地读取数据,但是这种顺序写入却会不可避免地产生RegionServer热点。接下来两部分我们将讨论并告诉你如何避免这个问题。
基于时间戳的格式:
递增/递减序列:
但是这种幼稚的RowKey会导致RegionServer写热点。
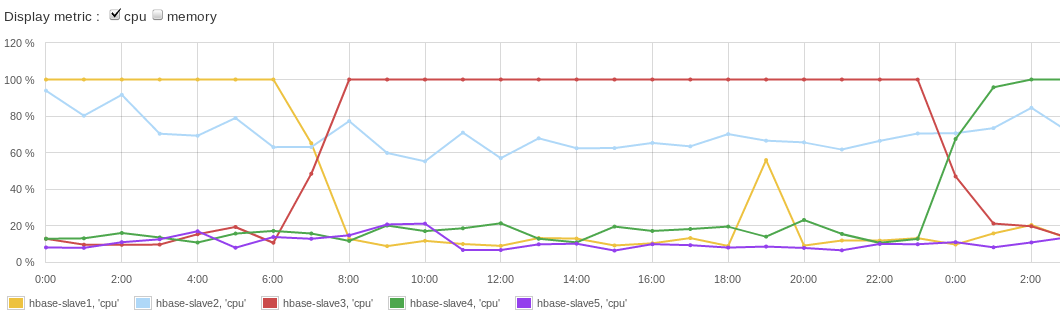
可以看出其中一台服务器满负荷运行以写入记录,但是其他服务器却处于空闲状态。HBase的RegionServer热点问题更多的信息可以参考HBase官方文档。
这种方式构造的RowKey,以我们可见的数据类型方式展示如下图2示:
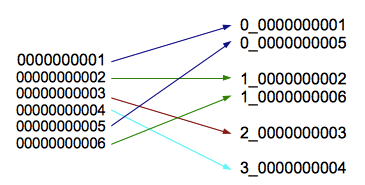
这里:
所以,新的记录将被分发到不同的‘桶’中,被HBase集群的不同RegionServer处理入库。新写入的记录的RowKey不再是顺序序列,但是在每一个‘桶’中,它们依然保持着原始的字典顺序。当然,如果你开始写数据到一个空的HBase表,在这个表被分割成多个region前你可能要等一段时间,等待的时长取决于流入数据大的大小和速度、压缩比以及region的大小。提示:通过HBase region预分割特效,可以避免这个等待。通过上面的方案写数据到不同的region,你的HBase节点负载看起来就好看多了:
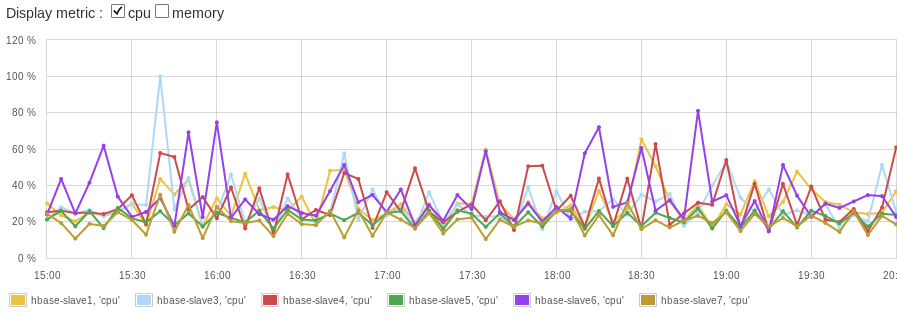
如果在你的应用中,除了按顺序Rowkey写入数据到HBase,还需要通过MapReduce持续的处理新数据的增量,那么本文建议的方案及其实现很可能会有所帮助。在这种情况下,数据持续频繁写入,增量处理只会位于少数region中,或者如果写负载不高时,(增量处理)只会在一个region中,亦或者如果最大region大小很大时,批量处理会很频繁。
你亦可以通过实现下面的接口以使用你自己的hash逻辑:
如何将HBaseWD集成到现有的生产环境中去
如果在运行的环境中改变RowKey分发逻辑
其它高级话题
问题描述
Hbase中的记录是按照字典顺序存储的。因此可以通过确定的RowKey快速找到某个记录,或者通过start RowKey和end RowKey作为区间以快速查询RowKey在这个区间的记录。所以你可能会认为,以顺序RowKey记录数据,然后可以快速通过上面的方法查询某个区间的记录的方式一个不出错的主意。例如我们可能会希望每个记录都与时间戳有关,以便我们可以通过时间区间查询一段时间的记录,这样的RowKey的例子如下:基于时间戳的格式:
Long.MAX_VALUE – new Date().getTime()
递增/递减序列:
”001”, ”002”, ”003”,… or ”499”, ”498”, ”497”, …
但是这种幼稚的RowKey会导致RegionServer写热点。
RegionServer Hotspotting
以顺序RowKey记录数据到HBase中时,所有的写操作会命中一个region。但是如果多个RegionServer服务同一个region时,这个问题就不存在了,不过实际并非如此,一个region通常只在一个RegionServer上。每个region都会预定义大小,当一个region达到最大大小时,就会被分割成两个小的region。然后两个较小的region中的一个负责记录所有的新写入的记录,这个region和它说在的RegionServer就成了新的写热点。显然,这种不均匀地写入是需要避免的,因为它将写操作的性能限制到单个RegionServer的写入能力,而没有将集群中所有RegionServer的性能释放出来。这种负载不均匀地写入操作可以从下图一看出:可以看出其中一台服务器满负荷运行以写入记录,但是其他服务器却处于空闲状态。HBase的RegionServer热点问题更多的信息可以参考HBase官方文档。
解决方案
如何解决这个问题呢?本文讨论的前提是我们不是一次性批量把所有数据写入HBase,而是以数据流的方式不断持续达到。批量数据导入HBase时如何避免热点的问题在HBase文档中有相关的最佳解决方案。但是,如果你和我们一样,数据持续流入并且需要处理和存储,那么解决热点的最简单的方案就是通过随机RowKey将数据流分发到不同的Region中。然而不幸的是,这样会牺牲通过start RowKey和end RowKey快速检索区间数据的能力。这个在HBase mail list和其它地方多次提及的解决方案就是为RowKey增加前缀。例如可以考虑通过下面的方式构造Rowkey:new_row_key = (++index % BUCKETS_NUMBER) + original_key
这种方式构造的RowKey,以我们可见的数据类型方式展示如下图2示:
这里:
index是我们用于特定记录的RowID的数字部分,例如1,2,3,4,
BUCKETS_NUMBER是我们希望新构建的RowKey想要分发到不同的‘桶’的数量。每一个‘桶’内,数据保持着他们原始ID记录的顺序。
original_key是写入数据的原始主键。
new_row_key是数据写入HBase中的实际RowKey(即
distributed key或者
prefixed key)。后文中,
distributed records用来表示通过
distributed key写入的记录。
所以,新的记录将被分发到不同的‘桶’中,被HBase集群的不同RegionServer处理入库。新写入的记录的RowKey不再是顺序序列,但是在每一个‘桶’中,它们依然保持着原始的字典顺序。当然,如果你开始写数据到一个空的HBase表,在这个表被分割成多个region前你可能要等一段时间,等待的时长取决于流入数据大的大小和速度、压缩比以及region的大小。提示:通过HBase region预分割特效,可以避免这个等待。通过上面的方案写数据到不同的region,你的HBase节点负载看起来就好看多了:
Scan操作
数据在写入过程中被分发到不同的‘桶’中,因此我们可以通过基于start RowKey和end RowKey的scan操作从多个‘桶’中提取数据,并且保证数据的原始排序状态。这也意味着BUCKETS_NUMBER个scan操作可能会影响性能。但是幸运的是这些scan操作可以并行,所以性能不至于降低,甚至会有所提高。对比一下,从一个region中读取100K数据,和从10个region中并行的读取10K数据,哪个更快?
Get/Delete
对单条记录进行Get/Delete操作,操作复杂度为O(1)到
O(BUCKETS_NUMBER)。 例如。 当使用“静态”散列作为前缀时,给定原始RowKey,就可以精确地识别
prefised rowkey。 如果我们使用随机前缀,我们将不得不在每个可能的‘桶’中执行Get操作。Delete操作也是如此。
MapReduce Input
我们仍旧希望从数据本身出发,因此将distributed record提供给MapReduce作业可能会打乱数据到达mapper的顺序。至少在HBaseWD的实现中,这个问题是存在的。每个
map task处理特定的‘桶’中的数据,所以,数据处理的顺序将于它们在‘桶’中的原始顺序一致。然而由于两个原始RowKey相邻的记录可能被分发存储到不同的‘桶’中,它们将会被分配到不同的
map task。因此如果
mapper认为数据严格的按照其原始顺序流入,我们则很受伤,因为数据只在每个桶保证原始顺序,并非全局保证顺序。
Increased Number of Map Tasks
当我们以上述方案的数据提供给MapReduce作业时,‘桶’的数目可能会增加。在HBaseWD的实现中,与使用相同参数的常规MapReduce作业相比,你需要进行BUCKETS_NUMBER倍分割。这与前面讨论的Get操作的逻辑相似。所以(HBaseWD的实现中,)MapReduce作业需要有
BUCKETS_NUMBER倍的
map task。如果
BUCKETS_NUMBER不大,理论上性能不会降低,当然,MapReduce作业本身的初始化和清理工作需要更多的时间。而且在很多情况下,更多的
mapper可以提升性能。很多用户报告指出,基于标准的HBase Tbase输入的MapReduce作业的
map task数目过少(每个region对应一个
map task),所以(我们的实现)可以不需要额外编码就可以对MapReduce产生积极作用。
如果在你的应用中,除了按顺序Rowkey写入数据到HBase,还需要通过MapReduce持续的处理新数据的增量,那么本文建议的方案及其实现很可能会有所帮助。在这种情况下,数据持续频繁写入,增量处理只会位于少数region中,或者如果写负载不高时,(增量处理)只会在一个region中,亦或者如果最大region大小很大时,批量处理会很频繁。
方案实现: HBaseWD
我们实现了上述方案,并且将之作为一个叫做HBaseWD的项目开源。由于HBaseWD支持HBase本地客户端API,所以它实际上是独立的,而且很容易集成到现有的项目代码中。HBaseWD项目首次在Configuring Distribution
Simple Even Distribution
使用顺序RowKey分发记录,最多分发到Byte.MAX_VALUE个‘桶’中,(通过在原始Rowkey前添加一个字节的前缀):
byte bucketsCount = (byte) 32; // distributing into 32 buckets RowKeyDistributor keyDistributor = **new RowKeyDistributorByOneBytePrefix(bucketsCount);** Put put = new Put(**keyDistributor.getDistributedKey(originalKey)**); ... // add values hTable.put(put);
Hash-Based Distribution
另一个有用的RowKey分发器是RowKeyDistributorByHashPrefix。参考下面的示例。它通过原始RowKey创建
distributed key,如果稍后希望通过原始Rowkey更新记录时,可以直接计算出
distributed key,而无需调用HBase,也无需知道记录在哪个‘桶’中。或者,你可以在知道原始Rowkey的情况下通过Get操作获取记录,而无需到所有的‘桶’中寻找。
AbstractRowKeyDistributor keyDistributor = new RowKeyDistributorByHashPrefix( new RowKeyDistributorByHashPrefix.OneByteSimpleHash(15));
你亦可以通过实现下面的接口以使用你自己的hash逻辑:
public static interface Hasher extends Parametrizable {
byte[] getHashPrefix(byte[] originalKey);
byte[][] getAllPossiblePrefixes();
}自定义分发逻辑
HBaseWD的设计灵活,特别是在支持自定义distributed key方法时。 除了上面提到的用于实现用于
RowKeyDistributorByHashPrefix的定制哈希逻辑的功能之外,还可以通过扩展
AbstractRowKeyDistributor抽象类来定义自己的RowKey分发逻辑,该类的接口非常简单:
public abstract class AbstractRowKeyDistributor implements Parametrizable {
public abstract byte[] getDistributedKey(byte[] originalKey);
public abstract byte[] getOriginalKey(byte[] adjustedKey);
public abstract byte[][] getAllDistributedKeys(byte[] originalKey);
... // some utility methods
}Common Operations
Scan
对数据执行基于范围的scan操作:Scan scan = new Scan(startKey, stopKey);
ResultScanner rs = **DistributedScanner.create**(hTable, scan, **keyDistributor**);
for (Result current : rs) {
...
}Configuring MapReduce Job
通过scan操作在指定的数据块上自习MapReduce作业:Configuration conf = HBaseConfiguration.create();
Job job = new Job(conf, "testMapreduceJob");
Scan scan = new Scan(startKey, stopKey);
TableMapReduceUtil.initTableMapperJob("table", scan,
RowCounterMapper.class, ImmutableBytesWritable.class, Result.class, job);
// Substituting standard TableInputFormat which was set in
// TableMapReduceUtil.initTableMapperJob(...)
job.setInputFormatClass(WdTableInputFormat.class);
**keyDistributor.addInfo**(job.getConfiguration());What’s Next?
下一篇文章中,我们将介绍:如何将HBaseWD集成到现有的生产环境中去
如果在运行的环境中改变RowKey分发逻辑
其它高级话题

相关文章推荐
- hbase regionserver挂掉的问题
- hbase中hbase和regionserver端口冲突问题
- HBase解决Region Server Compact过程占用大量网络出口带宽的问题
- hbase无法启动Regionserver:ClassNotFoundException: org.apache.hadoop.util.PlatformName问题解决
- hbase regionserver IO问题
- HBase client访问ZooKeeper获取root-region-server DeadLock问题(zookeeper.ClientCnxn Unable to get data of znode /hbase/root-region-server)
- HBase解决Region Server Compact过程占用大量网络出口带宽的问题
- hbase无法启动Regionserver:Failed construction of Regionserver: class org.apache.hadoop.hbase.regions问题解决
- HBase解决Region Server Compact过程占用大量网络出口带宽的问题
- HBase解决Region Server Compact过程占用大量网络出口带宽的问题
- hbase为避免热点,预先创建分区region
- HBase 表的创建 属性 避免热点问题 region split
- 解决HBase在数据大量写入时导致RegionServer崩溃问题
- HBase(2.6)-HBase的RowKey设计原则 ,热点问题
- HBase问题之master链接到regionserver不能连接问题
- HBase解决Region Server Compact过程占用大量网络出口带宽的问题
- Hbase中的rowkey以及热点问题
- Hbase的NoServerForRegionException: Unable to find region for talk,,99999999999999 after 10 tries问题
- HBase解决Region Server Compact过程占用大量网络出口带宽的问题
- hbase集群部分节点HRegionServer启动后自动关闭的问题