Google大规模cron基础服务设计
2017-11-19 17:28
746 查看
Google大规模cron基础服务设计
我们部署多个实例的Cron服务,然后通过Paxos算法来同步这些实例间的状态。
Paxos算法和它其他的替代算法(如Zab,Raft等)在分布式系统中是十分常见的。具体描述Paxos不在本文范围内,他的基本作用就是使多个不可靠节点间的状态保持一致,只要大部分Paxos组成员可用,那么整个分布式系统,就能作为一个整体处理状态的变化。
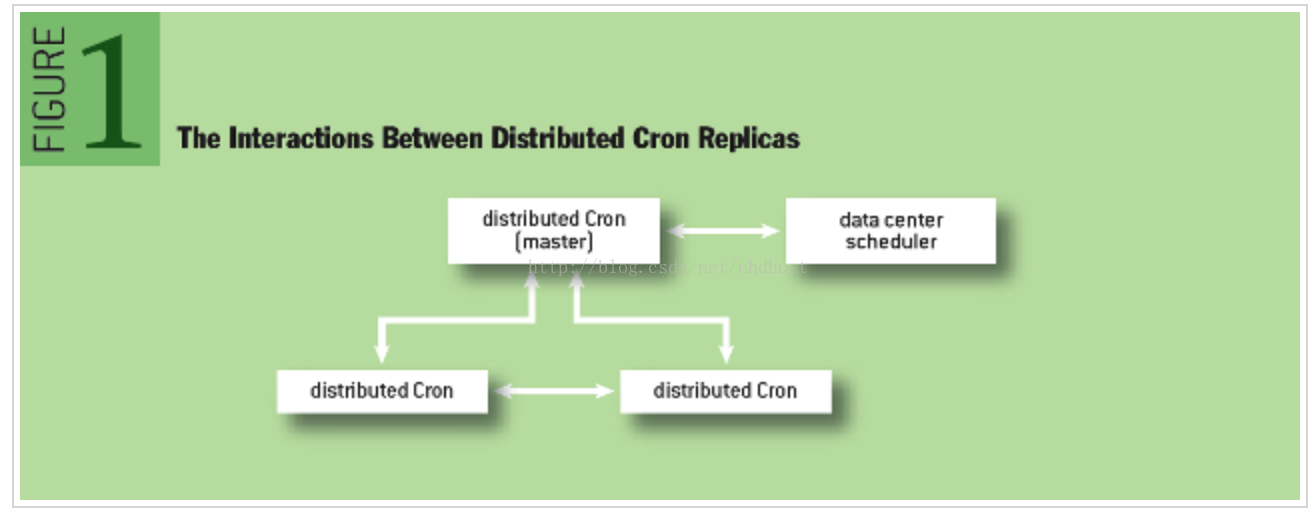
分布式Cron使用一个独立的master job,见图
Paxos,这里Fast Paxos的主节点也是Cron服务的主节点。
如果主节点挂掉,Paxos的健康检查机制会在秒级内快速发现,并选举出一个新的master。一旦选举出新的主节点,Cron服务也就随着选举出了一个新的主节点,这个新的主节点将会接手前一个主节点留下的所有的未完成的工作。在这里Cron的主节点和Paxos的主节点是一样的,但是Cron的主节点需要处理一下额外的工作而已。快速选举新的主节点的机制可以让我们大致可以容忍一分钟的故障时间。
我们使用Paxos算法保持的最重要的一个状态是,哪些Cron任务在运行。对于每一个运行的Cron任务,我们会将其加载运行的开始以及结束 同步给一定数量的节点。
如上面描述的那样,我们在Cron服务中使用Paxos并部署,其拥有两个不同的角色,
主节点用来加载Cron任务,它有个内部的调度系统,类似于单机的
当任务加载的时刻到来,主节点将会 “宣告” 他将会加载这个指定的任务,并且计算这个任务下次的加载时间,就像
展示了这一过程。
保持Paxos通讯同步非常重要,只有Paxos法定数收到了加载通知,这个指定的任务才能被加载执行。Cron服务需要知道每个任务是否已经启动,这样即使master挂掉,也能决定接下来的动作。如果不进行同步,意味着整个Cron任务运行在master节点,而slave无法感知到这一切。如果发生了故障,很有可能这个任务就被再次执行,因为没有节点知道这个任务已经被执行过了。
Cron任务的完成状态通过Paxos通知给其他节点,从而保持同步,这里要注意一点,这里的 “完成” 状态并不是表示任务是成功或者失败。我们跟踪cron任务在指定调用时间被执行的情况,我们同样需要处理一点情况是,如果Cron服务在加载任务进行执行的过程中失败后怎么办,这点我们在接下来会进行讨论。
master节点另一个重要的特性是,不管是出于什么原因master节点失去了其主控权,它都必须立马停止同数据中心调度系统的交互。主控权的保持对于访问数据中心应该是互斥了。如果不这样,新旧两个master节点可能会对数据中心的调度系统发起互相矛盾的操作请求。
slave节点实时监控从master节点传来的状态信息,以便在需要的时刻做出积极响应。所有master节点的状态变动信息,都通过Paxos传到各个slave节点。和master节点类似的是,slave节点同样维持一个列表,保存着所有的Cron任务。这个列表必须在所有的节点保持一致(当然还是通过Paxos)。
当接到加载任务的通知后,slave节点会将此任务的下次加载时间放入本地任务列表中。这个重要的状态信息变化(这是同步完成的)保证了系统内部Cron作业的时间表是一致的。我们跟踪所有有效的加载任务,也就是说,我们跟踪任务何时启动,而不是结束。
如果一个master节点挂掉或者因为某些原因失联(比如,网络异常等),一个slave节点有可能被选举成为一个新的master节点。这个选举的过程必须在一分钟内运行,以避免Cron任务丢失的情况。一旦被选举为master节点,所有运行的加载任务(或 部分失败的),必须被重新验证其有效性。这个可能是一个复杂的过程,在Cron服务系统和数据中心的调度系统上都需要执行这样的验证操作,这个过程有必要详细说明。
如上所述,master节点和数据中心的调度系统之间会通过RPC来加载一个逻辑Cron任务,但是,这一系列的RPC调用过程是有可能失败的,所以,我们必须考虑到这种情况,并且处理好。
回想下,每个加载的Cron任务会有两个同步点:开始加载以及执行完成。这能够让我们区分开不同的加载任务。即使任务加载只需要调用一次RPC,但是我们怎么知道RPC调用实际真实成功呢?我们知道任务何时开始,但是如果master节点挂了我们就不会知道它何时结束。
为了解决这个问题,所有在外部系统进行的操作,要么其操作是幂等性的(也就是说,我们可以放心的执行他们多次),要么我们必须实时监控他们的状态,以便能清楚的知道何时完成。
这些条件明显增加了限制,实现起来也有一定的难度,但是在分布式环境中这些限制却是保证Cron服务准确运行的根本,能够良好的处理可能出现的“fail”。如果不能妥善处理这些,将会导致Cron任务的加载丢失,或者加载多次重复的Cron任务。
大多数基础服务在数据中心(比如Mesos)加载逻辑任务时都会为这些任务命名,这样方便了查看任务的状态,终止任务,或者执行其他的维护操作。解决幂等性的一个合理的解决方案是将执行时间放在名字中 ——这样不会在数据中心的调度系统里造成任务异变操作 —— 然后在将他们分发给Cron服务所有的节点。如果Cron服务的master节点挂掉,那么新的master节点只需要简单的通过预处理任务名字来查看其对应的状态,然后加载遗漏的任务即可。
注意下,我们在节点间保持内部状态一致的时候,实时监控调度加载任务的时间。同样,我们也需要消除同数据中心调度交互时可能发生的不一致情况,所以这里我们以调度的加载时间为准。比如,有一个短暂但是频繁执行的Cron任务,它已经被执行了,但是在准备把情况通告给其他节点时,master节点挂了,并且故障时间持续的特别长——长到这个cron任务都已经成功执行完了。然后新的master节点要查看这个任务的状态,发现它已经被执行完成了,然后尝试加载他。如果包含了这个时间,那么master节点就会知道,这个任务已经被执行过了,就不会重复执行第二次。
在实际实施的过程中,状态监督是一个更加复杂的工作,他的实现过程和细节依赖与其他一些底层的基础服务,然而,上面并没有包括相关系统的实现描述。根据你当前可用的基础设施,你可能需要在冒险重复执行任务 和 跳过执行任务 之间做出折中选择。
使用Paxos来同步只是处理状态中遇到的其中一个问题。Paxos本质上只是通过一个日志来持续记录状态改变,并且随着状态的改变而进行将日志同步。这会产生两个影响:第一,这个日志需要被压缩,防止其无限增长;第二,这个日志本身需要保存在一个地方。
为了避免其无限增长,我们仅仅取状态当前的快照,这样,我们能够快速的重建状态,而不用在根据之前所有状态日志来进行重演。比如,在日志中我们记录一条状态 “
“
如果日志丢失,我们也仅仅丢失当前状态的一个快照而已。快照其实是最临界的状态 —— 如果丢失了快照,我们基本上就得从头开始了,因为我们丢失了上一次快照与丢失快照 期间所有的内部状态。从另一方面说,丢失日志,也意味着,将Cron服务拉回到有记录的上一次快照所标示的地方。
我们有两个主要选择来保存数据: 存储在外部的一个可用的分布式存储服务中,或者,在内部一个系统来存储Cron服务的状态。当我们设计系统时,这两点都需要考虑。
我们将Paxos日志存储在Cron服务节点所在服务器本地的磁盘中。默认的三个节点意味着,我们有三份日志的副本。我们同样也将快照存储在服务器本身,然而,因为其本身是非常重要的,我们也将它在分布式存储服务中做了备份,这样,即使小概率的三个节点机器都故障了,也能够服务恢复。
我们并没有将日志本身存储在分布式存储中,因为我们觉得,丢失日志也仅仅代表最近的一些状态丢失,这个我们其实是可以接受的。而将其存储在分布式存储中会带来一定的性能损失,因为它本身在不断的小字节写入不适用与分布式存储的使用场景。同时三台服务器全故障的概率太小,但是一旦这种情况发生了,我们也能自动的从快照中恢复,也仅仅损失从上次快照到故障点的这部分而已。当然,就像设计Cron服务本身一样,如何权衡,也要根据自己的基础设施情况来决定。
将日志和快照存本地,以及快照在分布式存储备份,这样,即使一个新的节点启动,也能够通过网络从其他已经运行的节点处获取这些信息。这意味着,启动节点与服务器本身并没有任何关系,重新安排一个新的服务器(比如重启)来担当某个节点的角色 其本质上也是影响服务的可靠性的问题之一。
使用Paxos
我们部署多个实例的Cron服务,然后通过Paxos算法来同步这些实例间的状态。Paxos算法和它其他的替代算法(如Zab,Raft等)在分布式系统中是十分常见的。具体描述Paxos不在本文范围内,他的基本作用就是使多个不可靠节点间的状态保持一致,只要大部分Paxos组成员可用,那么整个分布式系统,就能作为一个整体处理状态的变化。
分布式Cron使用一个独立的master job,见图
Figure 1,只有它才能更改共享的状态,也只有它才能加载Cron任务。我们这里使用了Paxos的一个变体——Fast
Paxos,这里Fast Paxos的主节点也是Cron服务的主节点。
如果主节点挂掉,Paxos的健康检查机制会在秒级内快速发现,并选举出一个新的master。一旦选举出新的主节点,Cron服务也就随着选举出了一个新的主节点,这个新的主节点将会接手前一个主节点留下的所有的未完成的工作。在这里Cron的主节点和Paxos的主节点是一样的,但是Cron的主节点需要处理一下额外的工作而已。快速选举新的主节点的机制可以让我们大致可以容忍一分钟的故障时间。
我们使用Paxos算法保持的最重要的一个状态是,哪些Cron任务在运行。对于每一个运行的Cron任务,我们会将其加载运行的开始以及结束 同步给一定数量的节点。
Master和Slave角色
如上面描述的那样,我们在Cron服务中使用Paxos并部署,其拥有两个不同的角色,master以及
slave。让我们来就每个角色来做具体的描述。
The Master
主节点用来加载Cron任务,它有个内部的调度系统,类似于单机的crond,维护一个任务加载列表,在指定的时间加载任务。
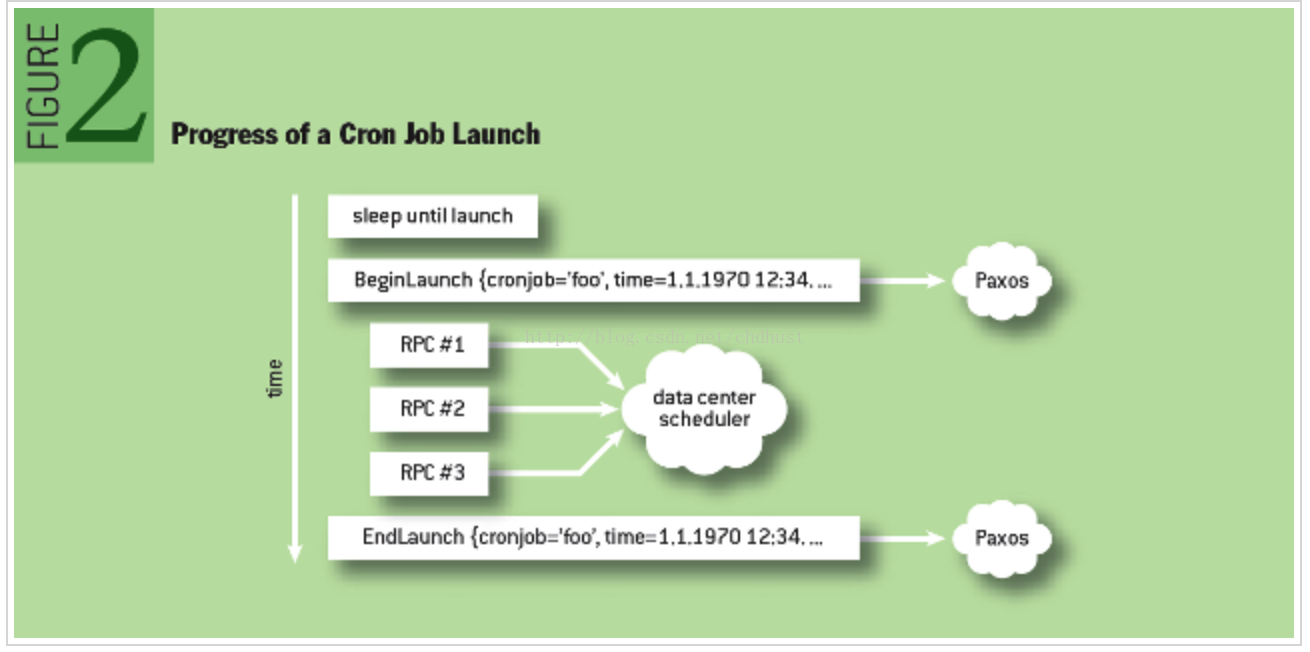
当任务加载的时刻到来,主节点将会 “宣告” 他将会加载这个指定的任务,并且计算这个任务下次的加载时间,就像
crond的做法一样。当然,就像
crond那样,一个任务加载后,下一次的加载时间可能人为的改变,这个变化也要同步给slave节点。简单的标示Cron任务还不够,我们还应该将这个任务与开始执行时间相关联绑定,以避免Cron任务在加载时发生歧义(特别是那些高频的任务,如一分钟一次的那些)。这个“通告”通过Paxos来进行。图2
展示了这一过程。
保持Paxos通讯同步非常重要,只有Paxos法定数收到了加载通知,这个指定的任务才能被加载执行。Cron服务需要知道每个任务是否已经启动,这样即使master挂掉,也能决定接下来的动作。如果不进行同步,意味着整个Cron任务运行在master节点,而slave无法感知到这一切。如果发生了故障,很有可能这个任务就被再次执行,因为没有节点知道这个任务已经被执行过了。
Cron任务的完成状态通过Paxos通知给其他节点,从而保持同步,这里要注意一点,这里的 “完成” 状态并不是表示任务是成功或者失败。我们跟踪cron任务在指定调用时间被执行的情况,我们同样需要处理一点情况是,如果Cron服务在加载任务进行执行的过程中失败后怎么办,这点我们在接下来会进行讨论。
master节点另一个重要的特性是,不管是出于什么原因master节点失去了其主控权,它都必须立马停止同数据中心调度系统的交互。主控权的保持对于访问数据中心应该是互斥了。如果不这样,新旧两个master节点可能会对数据中心的调度系统发起互相矛盾的操作请求。
the slave
slave节点实时监控从master节点传来的状态信息,以便在需要的时刻做出积极响应。所有master节点的状态变动信息,都通过Paxos传到各个slave节点。和master节点类似的是,slave节点同样维持一个列表,保存着所有的Cron任务。这个列表必须在所有的节点保持一致(当然还是通过Paxos)。当接到加载任务的通知后,slave节点会将此任务的下次加载时间放入本地任务列表中。这个重要的状态信息变化(这是同步完成的)保证了系统内部Cron作业的时间表是一致的。我们跟踪所有有效的加载任务,也就是说,我们跟踪任务何时启动,而不是结束。
如果一个master节点挂掉或者因为某些原因失联(比如,网络异常等),一个slave节点有可能被选举成为一个新的master节点。这个选举的过程必须在一分钟内运行,以避免Cron任务丢失的情况。一旦被选举为master节点,所有运行的加载任务(或 部分失败的),必须被重新验证其有效性。这个可能是一个复杂的过程,在Cron服务系统和数据中心的调度系统上都需要执行这样的验证操作,这个过程有必要详细说明。
故障恢复
如上所述,master节点和数据中心的调度系统之间会通过RPC来加载一个逻辑Cron任务,但是,这一系列的RPC调用过程是有可能失败的,所以,我们必须考虑到这种情况,并且处理好。回想下,每个加载的Cron任务会有两个同步点:开始加载以及执行完成。这能够让我们区分开不同的加载任务。即使任务加载只需要调用一次RPC,但是我们怎么知道RPC调用实际真实成功呢?我们知道任务何时开始,但是如果master节点挂了我们就不会知道它何时结束。
为了解决这个问题,所有在外部系统进行的操作,要么其操作是幂等性的(也就是说,我们可以放心的执行他们多次),要么我们必须实时监控他们的状态,以便能清楚的知道何时完成。
这些条件明显增加了限制,实现起来也有一定的难度,但是在分布式环境中这些限制却是保证Cron服务准确运行的根本,能够良好的处理可能出现的“fail”。如果不能妥善处理这些,将会导致Cron任务的加载丢失,或者加载多次重复的Cron任务。
大多数基础服务在数据中心(比如Mesos)加载逻辑任务时都会为这些任务命名,这样方便了查看任务的状态,终止任务,或者执行其他的维护操作。解决幂等性的一个合理的解决方案是将执行时间放在名字中 ——这样不会在数据中心的调度系统里造成任务异变操作 —— 然后在将他们分发给Cron服务所有的节点。如果Cron服务的master节点挂掉,那么新的master节点只需要简单的通过预处理任务名字来查看其对应的状态,然后加载遗漏的任务即可。
注意下,我们在节点间保持内部状态一致的时候,实时监控调度加载任务的时间。同样,我们也需要消除同数据中心调度交互时可能发生的不一致情况,所以这里我们以调度的加载时间为准。比如,有一个短暂但是频繁执行的Cron任务,它已经被执行了,但是在准备把情况通告给其他节点时,master节点挂了,并且故障时间持续的特别长——长到这个cron任务都已经成功执行完了。然后新的master节点要查看这个任务的状态,发现它已经被执行完成了,然后尝试加载他。如果包含了这个时间,那么master节点就会知道,这个任务已经被执行过了,就不会重复执行第二次。
在实际实施的过程中,状态监督是一个更加复杂的工作,他的实现过程和细节依赖与其他一些底层的基础服务,然而,上面并没有包括相关系统的实现描述。根据你当前可用的基础设施,你可能需要在冒险重复执行任务 和 跳过执行任务 之间做出折中选择。
状态保存
使用Paxos来同步只是处理状态中遇到的其中一个问题。Paxos本质上只是通过一个日志来持续记录状态改变,并且随着状态的改变而进行将日志同步。这会产生两个影响:第一,这个日志需要被压缩,防止其无限增长;第二,这个日志本身需要保存在一个地方。为了避免其无限增长,我们仅仅取状态当前的快照,这样,我们能够快速的重建状态,而不用在根据之前所有状态日志来进行重演。比如,在日志中我们记录一条状态 “
计数器加1”,然后经过了1000次迭代后,我们就记录了1000条状态日志,但是我们也可以简单的记录一条记录
“
将计数器设置为1000”来做替代。
如果日志丢失,我们也仅仅丢失当前状态的一个快照而已。快照其实是最临界的状态 —— 如果丢失了快照,我们基本上就得从头开始了,因为我们丢失了上一次快照与丢失快照 期间所有的内部状态。从另一方面说,丢失日志,也意味着,将Cron服务拉回到有记录的上一次快照所标示的地方。
我们有两个主要选择来保存数据: 存储在外部的一个可用的分布式存储服务中,或者,在内部一个系统来存储Cron服务的状态。当我们设计系统时,这两点都需要考虑。
我们将Paxos日志存储在Cron服务节点所在服务器本地的磁盘中。默认的三个节点意味着,我们有三份日志的副本。我们同样也将快照存储在服务器本身,然而,因为其本身是非常重要的,我们也将它在分布式存储服务中做了备份,这样,即使小概率的三个节点机器都故障了,也能够服务恢复。
我们并没有将日志本身存储在分布式存储中,因为我们觉得,丢失日志也仅仅代表最近的一些状态丢失,这个我们其实是可以接受的。而将其存储在分布式存储中会带来一定的性能损失,因为它本身在不断的小字节写入不适用与分布式存储的使用场景。同时三台服务器全故障的概率太小,但是一旦这种情况发生了,我们也能自动的从快照中恢复,也仅仅损失从上次快照到故障点的这部分而已。当然,就像设计Cron服务本身一样,如何权衡,也要根据自己的基础设施情况来决定。
将日志和快照存本地,以及快照在分布式存储备份,这样,即使一个新的节点启动,也能够通过网络从其他已经运行的节点处获取这些信息。这意味着,启动节点与服务器本身并没有任何关系,重新安排一个新的服务器(比如重启)来担当某个节点的角色 其本质上也是影响服务的可靠性的问题之一。

相关文章推荐
- Google Cloud Platfrom中运行基础的Apache Web服务
- WCF基础之设计和实现服务协定
- 如何设计稳定性横跨全球的 Cron 服务
- 大规模服务设计部署经验谈(全)
- 如何设计稳定性横跨全球的 Cron 服务
- 在线航班预定服务: Google Flights的交互设计
- 大规模服务设计部署经验谈
- 如何设计稳定性横跨全球的 Cron 服务
- [转]大规模服务设计部署经验谈(中)
- 【c#基础7】应用框架的设计与实现学习手札之类工厂服务——反射
- [转]大规模服务设计部署经验谈(中)
- [转]大规模服务设计部署经验谈(上)
- Windows Live! 平台团队:大规模服务设计部署经验
- [转]大规模服务设计部署经验谈(上)
- 如何设计稳定性横跨全球的 Cron 服务
- 【分布式设计与开发4】高一致服务——ZooKeeper基础
- 大规模服务设计部署经验谈
- Google Dapper-大规模分布式系统的基础跟踪设施
- Google之大规模分布式系统的监控基础架构Dapper
- 服务计算基础知识 UDDI SOAP WSDL特性 SOA 设计原则