TensorFlow 线性回归梯度下降模拟手写并可视化
2017-11-13 21:06
537 查看
python手写模拟梯度下降
以2元线性回归为例实现分类器:线性回归函数:
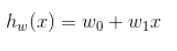
误差函数(损失函数):
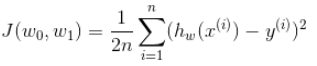
每次梯度下降参数的变化:
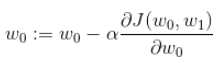
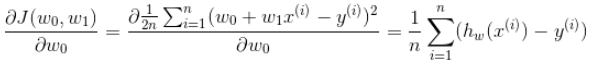
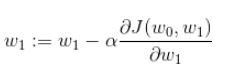

用python模拟梯度下降算法,并进行鸢尾花数据集的分类
激励函数:
最终得到的线性回归方程的图像大致是这样(不要管图中数据,只是示意一下大致的模样):
import matplotlib.pyplot as plt import numpy as np from mpl_toolkits.mplot3d import Axes3D fig = plt.figure() ax = Axes3D(fig) x = np.arange(1, 10, 0.02) y = np.arange(1, 10, 0.02) X, Y = np.meshgrid(x, y) Z = 1 + 2 * X - 3 * Y ax.plot_surface(X, Y, Z, color='red') ax.contourf(X, Y, Z, zdir='z', offset=0, alpha=0.4) plt.show()

根据回归方程,分别划分为值为>0和<=0的两部分
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
class AdalineGD:
def __init__(self, eta=0.01, n_iter=50):
self.eta = eta
self.n_iter = n_iter
def fit(self, X, y):
self.w_ = np.zeros(X.shape[1]+1)
self.J_ = []
for _ in range(self.n_iter):
yx = np.dot(X, self.w_[1:]) + self.w_[0]
self.w_[0] -= self.eta * (yx - y).sum()
self.w_[1:] -= self.eta * np.dot(X.T, (yx - y))
self.J_.append(((y-yx)**2).sum()*0.5)
return self
def predict(self, X):
return np.where(np.dot(X, self.w_[1:]) + self.w_[0] >= 0.0, 1, -1)
def plot_decision_regions(X, y, classifier, ax):
# setup marker generator and color map
markers = ('x', 'o')
colors = ('red', 'blue')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision region
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.02), np.arange(x2_min, x2_max, 0.02))
z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
z = z.reshape(xx1.shape)
plt.contourf(xx1, xx2, z, cmap=cmap, apha=0.3)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
# plot class samples
for idx, cl in enumerate(np.unique(y)):
ax[1].scatter(x=X[y == cl, 0], y=X[y == cl, 1], cmap=cmap(idx), marker=markers[idx], label=cl, alpha=1)
ax[1].set_title('Adaline-梯度下降法', fontproperties='SimHei')
ax[1].set_xlabel('经标准化处理的萼片宽度', fontproperties='SimHei')
ax[1].set_ylabel('经标准化处理的花瓣宽度', fontproperties='SimHei')
df = pd.read_csv(r'http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data')
y = df.iloc[:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
X = df.iloc[:100, [0, 2]].values
X_std = X.copy()
X_std[:, 0] = (X[:, 0] - X[:, 0].mean()) / X[:, 0].std()
X_std[:, 1] = (X[:, 1] - X[:, 1].mean()) / X[:, 1].std()
fig1, ax1 = plt.subplots(1, 2, figsize=(8, 4))
demo = AdalineGD(n_iter=20, eta=0.01).fit(X_std, y)
plot_decision_regions(X_std, y, demo, ax1)
ax1[0].plot(range(1, len(demo.J_)+1), np.log10(demo.J_), marker='o')
ax1[0].set_title('学习速率0.01', fontproperties='SimHei')
ax1[0].set_xlabel('迭代次数', fontproperties='SimHei')
ax1[0].set_ylabel('log(误差J)', fontproperties='SimHei')
plt.show()
使用TensorFlow框架
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def add_layer(input, in_size, out_size, activation_function=None):
Weight = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]))
y = tf.matmul(input, Weight) + biases
if activation_function is None:
return y
else:
return activation_function(y)
X_data = np.linspace(-1, 1, 100, dtype=np.float32)[:, np.newaxis]
noise = np.random.normal(0, 0.05, (X_data.shape[0], 1))
# 使得产生的数据在x^2+0.5曲线上下
y_data = np.square(X_data) + 0.5 + noise
X = tf.placeholder(tf.float32, [None, 1])
y = tf.placeholder(tf.float32, [None, 1])
# 通过add_layer指定了该层框架,之后在迭代过程中不再调用函数
# 输入层为1个神经元,隐藏层为10个神经元,输出层为1个神经元
hidden_layer = add_layer(X, 1, 10, activation_function=tf.nn.relu)
output_layer = add_layer(hidden_layer, 10, 1, activation_function=None)
loss = tf.reduce_mean(tf.square(y - output_layer))
trainer = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
fig, ax = plt.subplots(1, 1)
ax.scatter(X_data, y_data)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for _ in range(301):
sess.run(trainer, feed_dict={X: X_data, y: y_data})
if _ % 50 == 0:
print(sess.run(loss, feed_dict={X: X_data, y: y_data}))
curve = ax.plot(X_data, sess.run(output_layer, feed_dict={X: X_data, y: y_data}))
plt.pause(0.5) # 停留0.5s
if _ != 300:
ax.lines.remove(curve[0]) # 抹除ax上的线,必须以列表下标的形式
plt.show()
线性回归,梯度下降算法可视化:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
lr = 0.1
real_params = [1.2, 2.5] # 真正的参数
tf_X = tf.placeholder(tf.float32, [None, 1])
tf_y = tf.placeholder(tf.float32, [None, 1])
weight = tf.Variable(initial_value=[[5]], dtype=tf.float32)
bia = tf.Variable(initial_value=[[4]], dtype=tf.float32)
y = tf.matmul(tf_X, weight) + bia
loss = tf.losses.mean_squared_error(tf_y, y)
train_op = tf.train.GradientDescentOptimizer(lr).minimize(loss)
X_data = np.linspace(-1, 1, 200)[:, np.newaxis]
noise = np.random.normal(0, 0.1, X_data.shape)
y_data = X_data * real_params[0] + real_params[1] + noise
sess = tf.Session()
sess.run(tf.global_variables_initializer())
weights = []
biases = []
losses = []
for step in range(400):
w, b, cost, _ = sess.run([weight, bia, loss, train_op],
feed_dict={tf_X: X_data, tf_y: y_data})
weights.append(w)
biases.append(b)
losses.append(cost)
result = sess.run(y, feed_dict={tf_X: X_data, tf_y: y_data})
plt.figure(1)
plt.scatter(X_data, y_data, color='r', alpha=0.5)
plt.plot(X_data, result, lw=3)
fig = plt.figure(2)
ax_3d = Axes3D(fig)
w_3d, b_3d = np.meshgrid(np.linspace(-2, 7, 30), np.linspace(-2, 7, 30))
loss_3d = np.array(
[np.mean(np.square((X_data * w_ + b_) - y_data))
for w_, b_ in zip(w_3d.ravel(), b_3d.ravel())]).reshape(w_3d.shape)
ax_3d.plot_surface(w_3d, b_3d, loss_3d, cmap=plt.get_cmap('rainbow'))
weights = np.array(weights).ravel()
biases = np.array(biases).ravel()
# 描绘初始点
ax_3d.scatter(weights[0], biases[0], losses[0], s=30, color='r')
ax_3d.set_xlabel('w')
ax_3d.set_ylabel('b')
ax_3d.plot(weights, biases, losses, lw=3, c='r')
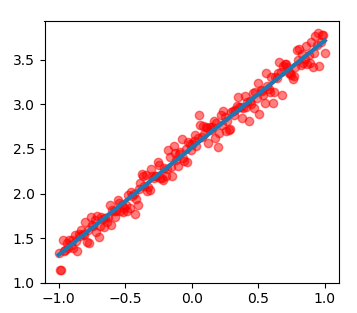
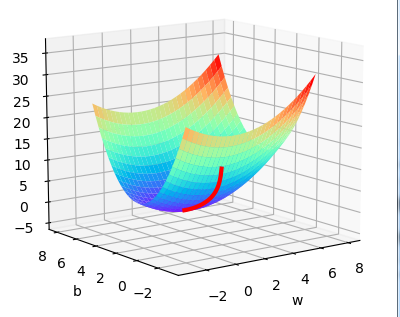
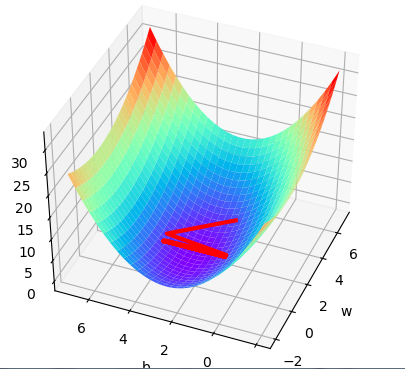
plt.show()拟合线性函数:y=1.2 x + 2.5
设初始的参数w=5,b=4,lr=0.1的拟合图像和梯度下降图像:
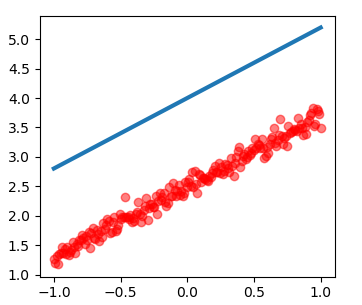
更改学习速率lr=1.0的图像:

相关文章推荐
- 运用TensorFlow进行简单实现线性回归、梯度下降示例
- 线性回归为毛使用梯度下降而不是导数等于0
- 机器学习入门:线性回归及梯度下降
- Ng深度学习笔记 1-线性回归、监督学习、成本函数、梯度下降
- 机器学习入门:线性回归及梯度下降(附matlab代码)
- 线性回归之梯度下降法
- 线性回归与梯度下降法
- 线性回归与梯度下降
- 机器学习入门:线性回归及梯度下降
- 机器学习入门:线性回归及梯度下降
- 机器学习入门:线性回归及梯度下降
- 梯度下降原理及在线性回归、逻辑回归中的应用
- 机器学习入门:线性回归及梯度下降
- 机器学习入门:线性回归及梯度下降
- Machine Learning(Stanford)| 斯坦福大学机器学习笔记--第一周(5.线性回归的梯度下降)
- 机器学习入门:线性回归及梯度下降
- [置顶] windows10 tensorflow(二)原理实战之回归分析,深度学习框架(梯度下降法求解回归参数)
- 【学习笔记】斯坦福大学公开课(机器学习) 之一:线性回归、梯度下降
- 梯度下降原理及在线性回归、逻辑回归中的应用
- 线性回归与梯度下降法[一]——原理与实现