SQL优化基础 使用索引(一个小例子)
2017-11-12 20:26
477 查看
按照本文操作和体会,会对sql优化有个基本最简单的了解,其他深入还需要更多资料和实践的学习:
1. 建表:
复制代码代码如下:
create table site_user
(
id int IDENTITY(1,1) PRIMARY KEY,
[name] varchar(20),
code varchar(20),
date datetime
)
2. 插入8万条数据
复制代码代码如下:
declare @m int
set @m=1
while @m<80000
begin
INSERT INTO [demo].[dbo].[site_user]
(
[name]
,[code],date)
VALUES
('name'+CAST(@m AS VARCHAR(20))
,'code'+CAST(@m AS VARCHAR(20)),GETUTCDATE())
select @m=@m+1
END
--小技巧:推荐使用类似sqlassist的工具来提高敲写sql语句的速度
3. 设置打开一些参数的设置
复制代码代码如下:
SET STATISTICS IO on -- 查看磁盘IO
set statistics time on -- 查看sql语句分析编译和执行时间
SELECT * FROM site_user -- 查看效果
4. 查看表索引情况:
sp_helpindex site_user

5. 执行sql语句
复制代码代码如下:
SELECT * FROM site_user su WHERE su.name='name1'表 'site_user'。
扫描计数 1,逻辑读取 446 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次
ctrl+L 快捷键查看执行计划:
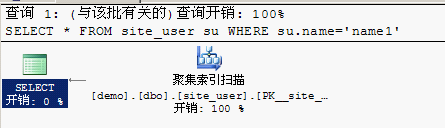
6. 优化第一步:聚集索引扫描开销占了100%,可以考虑优化为索引查找,在查询条件name上建立非聚集索引
复制代码代码如下:
create index name_index on site_user(name)
sp_helpindex site_user -- 多出来我们新建立的索引

此时再运行上面的查询语句:
复制代码代码如下:
SELECT * FROM site_user su WHERE su.name='name1'
表 'site_user'。扫描计数 1,逻辑读取 4 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
磁盘逻辑读取次数明显下降,然后查看执行计划:
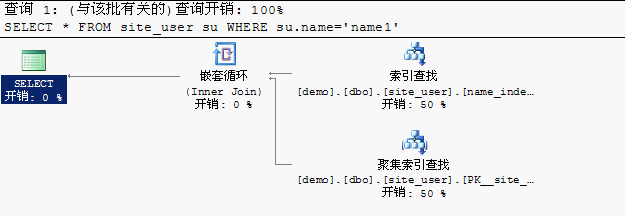
新建的索引已经起到了作用,但是还是去扫描了主键的聚集索引,如果能在一个索引上完成查询性能会更高,因为这个查询
所以考虑进一步优化:
7. 优化第二步: 建立组合索引
复制代码代码如下:
create index name_index4 on site_user(name,code,[date])
表 'site_user'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
-- 磁盘逻辑读取次数又下降了
然后查看执行计划:

这样直接走索引查找就快很多了,使用了index4
8. 优化第三步:我们还可以考虑使用覆盖索引,将使用到的条件都写在索引括号内,其他查询出来的字段放入include中,
复制代码代码如下:
create index name_index5 on site_user(name)include(id,code,[date])表 'site_user'。
扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
-- 磁盘逻辑读取次数没有明显变化然后查看执行计划:

同样走索引查找使用了index5
此时: index4和index5如何选择?
利用dbcc进行数据分析:
复制代码代码如下:
DBCC SHOW_STATISTICS('site_user','name_index4')
DBCC SHOW_STATISTICS('site_user','name_index5')
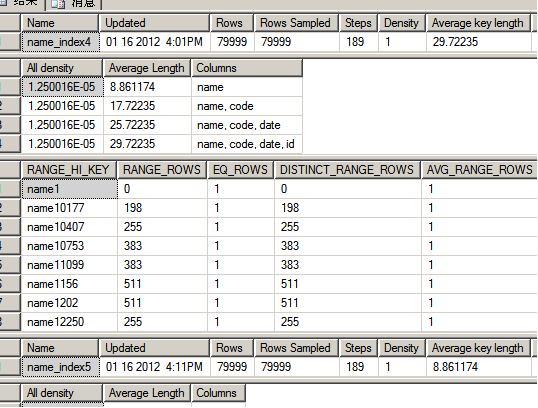
可以看到,同样的数据量,average key length:覆盖索引index5,占用的空间相对少些,所以我们应该优先选择覆盖索引来进行优化
1. 建表:
复制代码代码如下:
create table site_user
(
id int IDENTITY(1,1) PRIMARY KEY,
[name] varchar(20),
code varchar(20),
date datetime
)
2. 插入8万条数据
复制代码代码如下:
declare @m int
set @m=1
while @m<80000
begin
INSERT INTO [demo].[dbo].[site_user]
(
[name]
,[code],date)
VALUES
('name'+CAST(@m AS VARCHAR(20))
,'code'+CAST(@m AS VARCHAR(20)),GETUTCDATE())
select @m=@m+1
END
--小技巧:推荐使用类似sqlassist的工具来提高敲写sql语句的速度
3. 设置打开一些参数的设置
复制代码代码如下:
SET STATISTICS IO on -- 查看磁盘IO
set statistics time on -- 查看sql语句分析编译和执行时间
SELECT * FROM site_user -- 查看效果
4. 查看表索引情况:
sp_helpindex site_user
5. 执行sql语句
复制代码代码如下:
SELECT * FROM site_user su WHERE su.name='name1'表 'site_user'。
扫描计数 1,逻辑读取 446 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次
ctrl+L 快捷键查看执行计划:
6. 优化第一步:聚集索引扫描开销占了100%,可以考虑优化为索引查找,在查询条件name上建立非聚集索引
复制代码代码如下:
create index name_index on site_user(name)
sp_helpindex site_user -- 多出来我们新建立的索引
此时再运行上面的查询语句:
复制代码代码如下:
SELECT * FROM site_user su WHERE su.name='name1'
表 'site_user'。扫描计数 1,逻辑读取 4 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
磁盘逻辑读取次数明显下降,然后查看执行计划:
新建的索引已经起到了作用,但是还是去扫描了主键的聚集索引,如果能在一个索引上完成查询性能会更高,因为这个查询
所以考虑进一步优化:
7. 优化第二步: 建立组合索引
复制代码代码如下:
create index name_index4 on site_user(name,code,[date])
表 'site_user'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
-- 磁盘逻辑读取次数又下降了
然后查看执行计划:
这样直接走索引查找就快很多了,使用了index4
8. 优化第三步:我们还可以考虑使用覆盖索引,将使用到的条件都写在索引括号内,其他查询出来的字段放入include中,
复制代码代码如下:
create index name_index5 on site_user(name)include(id,code,[date])表 'site_user'。
扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
-- 磁盘逻辑读取次数没有明显变化然后查看执行计划:
同样走索引查找使用了index5
此时: index4和index5如何选择?
利用dbcc进行数据分析:
复制代码代码如下:
DBCC SHOW_STATISTICS('site_user','name_index4')
DBCC SHOW_STATISTICS('site_user','name_index5')
可以看到,同样的数据量,average key length:覆盖索引index5,占用的空间相对少些,所以我们应该优先选择覆盖索引来进行优化

相关文章推荐
- SQL优化基础:使用索引(一个小例子)
- SQL优化基础 使用索引(一个小例子)
- SQL优化基础 使用索引(一个小例子)
- SQL优化基础 使用索引(一个小例子)
- SQL优化基础:使用索引(一个小例子)
- SQL优化基础 使用索引(一个小例子)
- SQL优化基础:使用索引
- 怎样使用复合索引优化一个分析函数SQL
- Oracle SQL优化之使用索引提示一例
- SQL临时表建立和使用的一个例子
- SQL查询优化--使用索引
- Sql Server 索引使用情况及优化的相关 Sql
- Sql Server:索引使用情况及优化的相关 Sql
- Sql Server 索引使用情况及优化的相关Sql语句分享
- Sql优化系列之(2)__索引没有被使用
- 看看一个使用索引后查询速度提升的例子
- oracle sql优化案例1(使用组合索引)
- Sql Server 索引使用情况及优化的相关 Sql
- Hibernate Sql优化方案及索引使用
- 一个查选优化的例子,转--SQL Server中存储过程比直接运行SQL语句慢的原因