Reading Note: Progressive Growing of GANs for Improved Quality, Stability, and Variation
2017-11-12 13:37
351 查看
TITLE: Progressive Growing of GANs for Improved Quality, Stability, and Variation
AUTHOR: Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen
ASSOCIATION: NVIDIA
FROM: ICLR2018
all scales simultaneously.
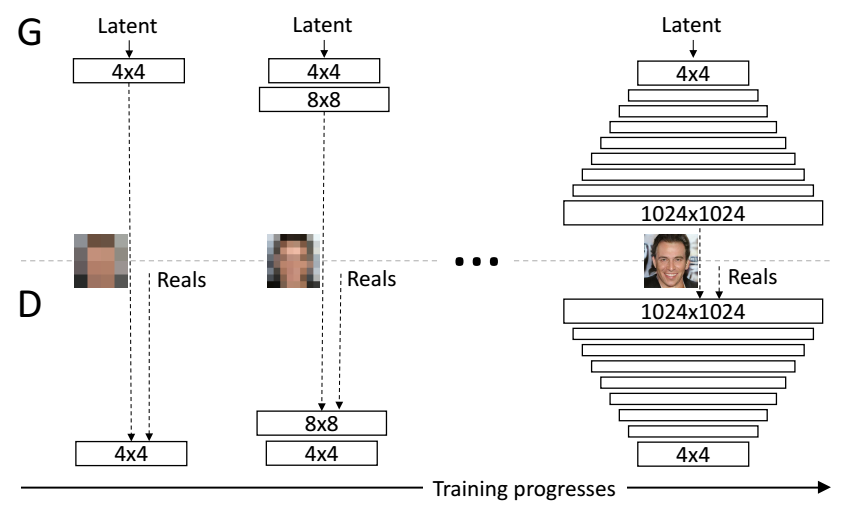
The training starts with both the generator G and discriminator D having a low spatial resolution of 4×4 pixels. As the training advances, successive layers are incrementally added to G and D, thus increasing the spatial resolution of the generated images. All existing layers remain trainable throughout the process. Here N×N refers to convolutional layers operating on N×N spatial resolution. This allows stable synthesis in high resolutions and also speeds up training considerably.
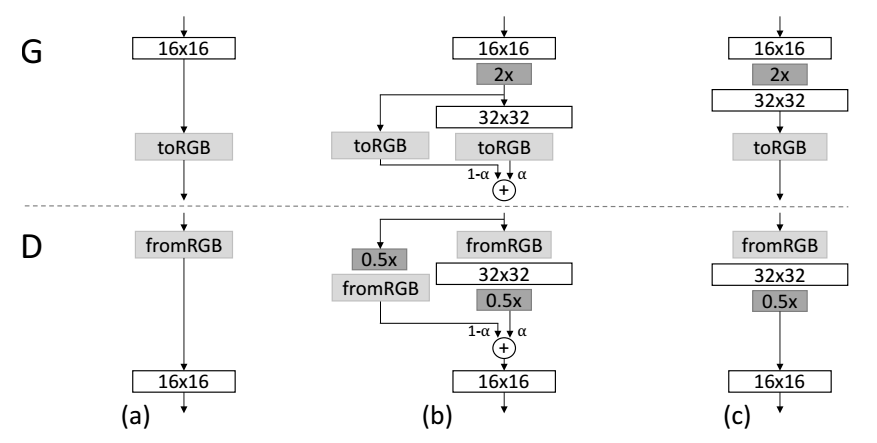
fade in is adopted when the new layers are added to double resolution of the generator G and discriminator D smoothly. This example illustrates the transition from 16×16 images (a) to 32×32 images (c). During the transition (b) the layers that operate on the higher resolution works like a residual block, whose weight α increases linearly from 0 to 1. Here 2x and 0.5x refer to doubling and halving the image resolution using nearest neighbor filtering and average pooling, respectively. The toRGB represents a layer that projects feature vectors to RGB colors and fromRGB does the reverse; both use 1×1 convolutions. When training the discriminator, the real images are downscaled to match the current resolution of the network. During a resolution transition, interpolation is carried out between two resolutions of the real images, similarly to how the generator output combines two resolutions.
Average these estimates over all features and spatial locations to arrive at a single value.
Consturct one additional (constant) feature map by replicating the value and concatenate it to all spatial locations and over the minibatch
PIXELWISE FEATURE VECTOR NORMALIZATION IN GENERATOR. To disallow the scenario where the magnitudes in the generator and discriminator spiral out of control as a result of competition, the feature vector is normalized in each pixel to unit length in the generator after each convolutional layer, using a variant of “local response normalization”, configured as
bx,y=ax,y/1N∑j=0N−1(ajx,y)2+ϵ−−−−−−−−−−−−−−⎷
where ϵ=10−8, N is the number of feature maps, and ax,y is original feature vector, bx,y is the normalized feature vector in pixel (x,y).
AUTHOR: Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen
ASSOCIATION: NVIDIA
FROM: ICLR2018
CONTRIBUTION
A training methodology is proposed for GANs which starts with low-resolution images, and then progressively increases the resolution by adding layers to the networks. This incremental nature allows the training to first discover large-scale structure of the image distribution and then shift attention to increasingly finer scale detail, instead of having to learnall scales simultaneously.
METHOD
PROGRESSIVE GROWING OF GANS
The following figure illustrates the training procedure of this work.The training starts with both the generator G and discriminator D having a low spatial resolution of 4×4 pixels. As the training advances, successive layers are incrementally added to G and D, thus increasing the spatial resolution of the generated images. All existing layers remain trainable throughout the process. Here N×N refers to convolutional layers operating on N×N spatial resolution. This allows stable synthesis in high resolutions and also speeds up training considerably.
fade in is adopted when the new layers are added to double resolution of the generator G and discriminator D smoothly. This example illustrates the transition from 16×16 images (a) to 32×32 images (c). During the transition (b) the layers that operate on the higher resolution works like a residual block, whose weight α increases linearly from 0 to 1. Here 2x and 0.5x refer to doubling and halving the image resolution using nearest neighbor filtering and average pooling, respectively. The toRGB represents a layer that projects feature vectors to RGB colors and fromRGB does the reverse; both use 1×1 convolutions. When training the discriminator, the real images are downscaled to match the current resolution of the network. During a resolution transition, interpolation is carried out between two resolutions of the real images, similarly to how the generator output combines two resolutions.
INCREASING VARIATION USING MINIBATCH STANDARD DEVIATION
Compute the standard deviation for each feature in each spatial location over the minibatch.Average these estimates over all features and spatial locations to arrive at a single value.
Consturct one additional (constant) feature map by replicating the value and concatenate it to all spatial locations and over the minibatch
NORMALIZATION IN GENERATOR AND DISCRIMINATOR
EQUALIZED LEARNING RATE. A trivial N(0;1) initialization is used and then explicitly the weights are scaled at runtime. To be precise, w^i=wi/c, where wi are the weights and c is the per-layer normalization constant from He’s initializer.The benefit of doing this dynamically instead of during initialization is somewhat subtle, and relates to the scale-invariance in commonly used adaptive stochastic gradient descent methods.PIXELWISE FEATURE VECTOR NORMALIZATION IN GENERATOR. To disallow the scenario where the magnitudes in the generator and discriminator spiral out of control as a result of competition, the feature vector is normalized in each pixel to unit length in the generator after each convolutional layer, using a variant of “local response normalization”, configured as
bx,y=ax,y/1N∑j=0N−1(ajx,y)2+ϵ−−−−−−−−−−−−−−⎷
where ϵ=10−8, N is the number of feature maps, and ax,y is original feature vector, bx,y is the normalized feature vector in pixel (x,y).

相关文章推荐
- PROGRESSIVE GROWING OF GANs for IMPROVED QUALITY, STABILITY AND VARIATION
- READING NOTE: Pushing the Limits of Deep CNNs for Pedestrian Detection
- READING NOTE: Face Detection with End-to-End Integration of a ConvNet and a 3D Model
- CO--Note 74486 - INFO: Overview of consulting notes for CO-PA
- Reading Note : Parameter estimation for text analysis 暨LDA学习小结
- Most of these Diesel-engined wristwatches wall socket available for purchase are designed when using the similar premium quality products
- READING NOTE: Aggregated Residual Transformations for Deep Neural Networks
- CO--Note 74486 - INFO: Overview of consulting notes for CO-PA
- “A Part-aware Surface Metric for Shape Analysis” Reading Note
- READING NOTE: Beyond Skip Connections: Top-Down Modulation for Object Detection
- READING NOTE: Learning Spatial Regularization with Image-level Supervisions for Multi-label ...
- READING NOTE: PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- [paper note] A Survey of Motion Planning and Control Techniques for Self-driving Urban Vehicles
- Reading Note: ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- READING NOTE: Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Trackin
- The note of Developing Innovative Ideas for New Companies Course
- Wiley - VERIFICATION AND VALIDATION FOR QUALITY OF UML 2.0 MODELS
- Improved Techniques for Training GANs
- [Paper note] Joint Learning of Single-image and Cross-image Representations for Person Re-id.
- 【1】Quality of Service Support for Real-time Storage Systems