JAVA爬虫与HTTP协议整理
2017-11-12 00:00
435 查看
HTTP协议简述
HTTP(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,它基于TCP/IP协议之上,同样遵循三次握手机制,广泛用于web应用中。我们所常见的请求方式有Get和Post方法,但实际上HTTP请求方法还有很多,比如: PUT方法,DELETE方法,HEAD方法,CONNECT方法,TRACE方法。这里我就不细说了,自行百度。HTTP可以按照两大模块来分,即请求部分和响应部分:
请求部分:
HTTP请求由三部分部分组成,请求行,请求头和请求体,我们用Fiddler抓包来分析一下:
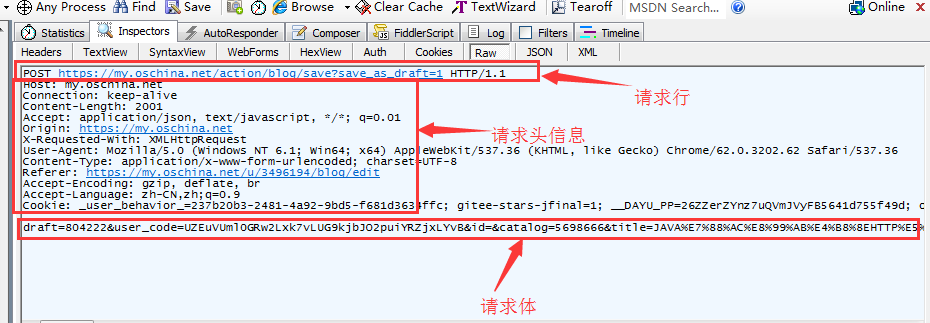
请求行可以分为三部分组成,格式:请求方式 资源路径 HTTP版本号。
请求头信息功能解析 :
Accept : 告诉服务端 客户端接受什么类型的响应
Accept-Charaset:告诉服务端客户端接收的字符编码
Accept-Language:客户端支持的语言类型
Authorization:设置HTTP身份验证的凭证
Connection:close/Keep-Alive [保持链接否,发完数据后,我不关闭链接]
Content-Type:设置请求体的MIME类型(适用POST和PUT请求)
Cookie:服务端存储在客户端的一些信息(比如登陆后的token)
Content-Length:请求消息正文的长度
Cache-Control:设置请求响应链上所有的缓存机制必须遵守的指令
Date:请求的时间戳
Host:浏览器要去访问的服务器主机
Max-Forwards:限制最大转发次数
Origin:标识跨域资源请求
Range:设置请求实体的字节数范围
Referer:告诉服务器我来自哪里,常用于防止下载,盗链
User-Agent:请求的浏览器类型
Warning:实体可能会发生的问题的通用警告
X-Requested-With:标识Ajax请求
请求体通常会根据请求头设置的MIME类型来指定不同格式,MIME类型可自行百度,GET没有请求体,它是以URL拼接方式传参。
响应部分:
HTTP响应跟请求比较类似,也是由三部分部分组成,响应状态行,响应头和响应体,同样我们用Fiddler抓包来分析一下:
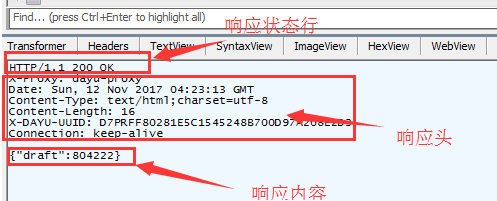
响应状态行分为两部分组成,格式:HTTP版本号 响应状态码。
常见的响应状态码类型:
1XX Informational:信息性状态码
2XX Success:成功状态码
3XX Redirection:重定向状态码
4XX Client Error:客户端错误状态码
5XX Server Error:服务器错误状态码
响应头信息功能解析 :
Access-Control-Allow-Origin:指定哪些站点可以参与跨站资源共享
Alt-Svc:标识资源可以通过不同的网络位置或者不同的网络协议获取
Accept-Ranges:服务器支持内容类型
Access-Control-Allow-Origin:(跨域资源共享)该字段是必须的。它的值要么是请求时Origin字段的值,要么是一个*,表示接受任意域名的请求
Access-Control-Allow-Credentials:(跨域资源共享)该字段可选。它的值是一个布尔值,表示是否允许发送Cookie
Access-Control-Expose-Headers:(跨域资源共享)该字段可选。CORS请求时,
Access-Control-Request-Method:列出浏览器的CORS请求会用到哪些HTTP方法
Access-Control-Request-Headers:指定浏览器CORS请求会额外发送的头信息字段
Cache-Control:客户端所有的缓存机制是否可以缓存这个对象,单位秒
Connection:close/Keep-Alive [保持链接否,发完数据后,我不关闭链接]
Content-Encoding:设置数据使用的编码类型
Content-Length:响应体的字节长度
Content-Location:设置返回数据的位置
Content-Type:响应体的MIME类型
Date:响应时间
ETag:特定版本资源的标识符,通常是消息摘要
Expires:设置响应体的过期时间
Last-Modified:设置请求对象最后一次的修改日期
Keep-Alive:与服务器端连接超时保护,单位秒,超时自动断开连接
Location:在重定向中或者创建新资源时使用
Server:服务器名
Set-Cookie:返回给浏览器的token信息,比如登陆成功后去请求用户信息,必须带上这个Cookie
Status:响应状态
Strict-Transport-Security:通知HTTP客户端缓存HTTPS策略多长时间以及是否应用到子域
Upgrade:请求客户端升级协议
Vary:通知下级代理如何匹配未来的请求头已让其决定缓存的响应是否可用而不是重新从源主机请求
Wait:等待时常,单位秒
WWW-Authenticate:标识访问请求实体的身份验证方案
X-Content-Type-Options:阻止IE在响应中嗅探定义的内容格式以外的其他MIME格式
X-Powered-By:指定支持web应用的技术
X-XSS-Protection:过滤跨站脚本
响应体通常会根据响应头设置的MIME类型来指定不同格式
至此,我们已经了解了HTTP协议,接下类我们用JAVA代码写段爬虫程序测试一下。
我构建的是maven工程,首先导入我们需要用到的工具jsoup maven依赖:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
</dependency>
我们以中国移动作为爬取目标,采用短信验证码形式登陆:
第一步:发送短信验证码,抓包分析
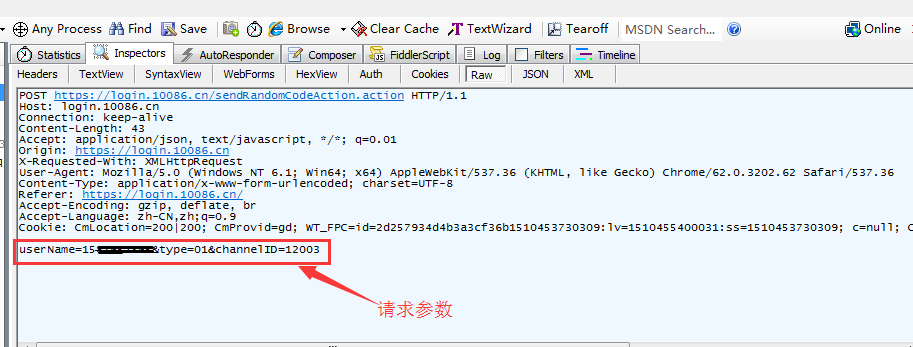
上图可以看到我们请求的数据格式是from表单提交的格式,下面我们来用代码实现这个操作吧
拿到短信之后我们就要去登陆了,我们先分析下登陆的请求参数
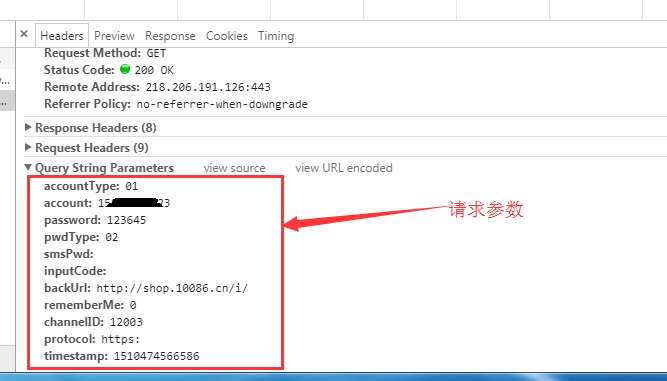
至此,我们已经拿到登陆后的cookie,然后我们去拿登陆后的用户信息易如反掌,看看我们登陆后页面数据的样子。
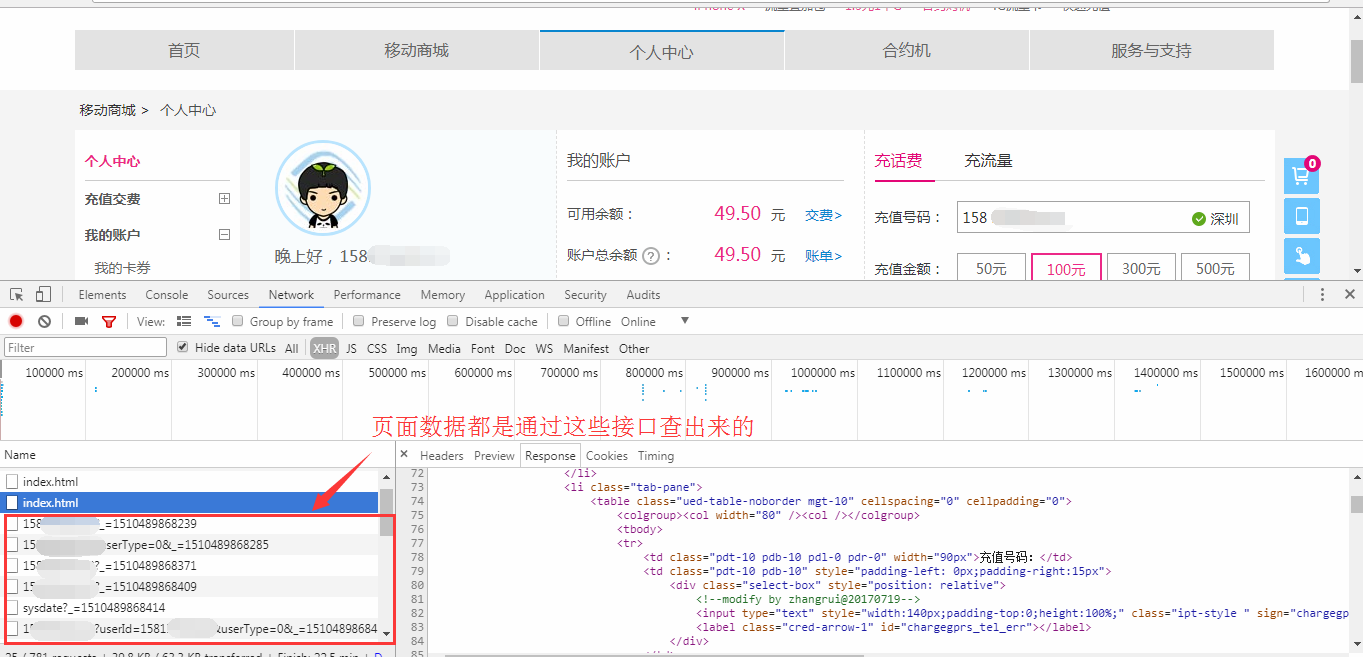
然后同样按照上面的请求方式,唯一不同的是带上我们获取到的cookie去访问这些接口,至此,你想要的数据都可以拿到了,开心吧~
HTTP(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,它基于TCP/IP协议之上,同样遵循三次握手机制,广泛用于web应用中。我们所常见的请求方式有Get和Post方法,但实际上HTTP请求方法还有很多,比如: PUT方法,DELETE方法,HEAD方法,CONNECT方法,TRACE方法。这里我就不细说了,自行百度。HTTP可以按照两大模块来分,即请求部分和响应部分:
请求部分:
HTTP请求由三部分部分组成,请求行,请求头和请求体,我们用Fiddler抓包来分析一下:
请求行可以分为三部分组成,格式:请求方式 资源路径 HTTP版本号。
请求头信息功能解析 :
Accept : 告诉服务端 客户端接受什么类型的响应
Accept-Charaset:告诉服务端客户端接收的字符编码
Accept-Language:客户端支持的语言类型
Authorization:设置HTTP身份验证的凭证
Connection:close/Keep-Alive [保持链接否,发完数据后,我不关闭链接]
Content-Type:设置请求体的MIME类型(适用POST和PUT请求)
Cookie:服务端存储在客户端的一些信息(比如登陆后的token)
Content-Length:请求消息正文的长度
Cache-Control:设置请求响应链上所有的缓存机制必须遵守的指令
Date:请求的时间戳
Host:浏览器要去访问的服务器主机
Max-Forwards:限制最大转发次数
Origin:标识跨域资源请求
Range:设置请求实体的字节数范围
Referer:告诉服务器我来自哪里,常用于防止下载,盗链
User-Agent:请求的浏览器类型
Warning:实体可能会发生的问题的通用警告
X-Requested-With:标识Ajax请求
请求体通常会根据请求头设置的MIME类型来指定不同格式,MIME类型可自行百度,GET没有请求体,它是以URL拼接方式传参。
响应部分:
HTTP响应跟请求比较类似,也是由三部分部分组成,响应状态行,响应头和响应体,同样我们用Fiddler抓包来分析一下:
响应状态行分为两部分组成,格式:HTTP版本号 响应状态码。
常见的响应状态码类型:
1XX Informational:信息性状态码
2XX Success:成功状态码
3XX Redirection:重定向状态码
4XX Client Error:客户端错误状态码
5XX Server Error:服务器错误状态码
响应头信息功能解析 :
Access-Control-Allow-Origin:指定哪些站点可以参与跨站资源共享
Alt-Svc:标识资源可以通过不同的网络位置或者不同的网络协议获取
Accept-Ranges:服务器支持内容类型
Access-Control-Allow-Origin:(跨域资源共享)该字段是必须的。它的值要么是请求时Origin字段的值,要么是一个*,表示接受任意域名的请求
Access-Control-Allow-Credentials:(跨域资源共享)该字段可选。它的值是一个布尔值,表示是否允许发送Cookie
Access-Control-Expose-Headers:(跨域资源共享)该字段可选。CORS请求时,
XMLHttpRequest对象的
getResponseHeader()方法只能拿到6个基本字段:
Cache-Control、
Content-Language、
Content-Type、
Expires、
Last-Modified、
Pragma。如果想拿到其他字段,就必须在
Access-Control-Expose-Headers里面指定。上面的例子指定,
getResponseHeader('FooBar')可以返回FooBar字段的值。
Access-Control-Request-Method:列出浏览器的CORS请求会用到哪些HTTP方法
Access-Control-Request-Headers:指定浏览器CORS请求会额外发送的头信息字段
Cache-Control:客户端所有的缓存机制是否可以缓存这个对象,单位秒
Connection:close/Keep-Alive [保持链接否,发完数据后,我不关闭链接]
Content-Encoding:设置数据使用的编码类型
Content-Length:响应体的字节长度
Content-Location:设置返回数据的位置
Content-Type:响应体的MIME类型
Date:响应时间
ETag:特定版本资源的标识符,通常是消息摘要
Expires:设置响应体的过期时间
Last-Modified:设置请求对象最后一次的修改日期
Keep-Alive:与服务器端连接超时保护,单位秒,超时自动断开连接
Location:在重定向中或者创建新资源时使用
Server:服务器名
Set-Cookie:返回给浏览器的token信息,比如登陆成功后去请求用户信息,必须带上这个Cookie
Status:响应状态
Strict-Transport-Security:通知HTTP客户端缓存HTTPS策略多长时间以及是否应用到子域
Upgrade:请求客户端升级协议
Vary:通知下级代理如何匹配未来的请求头已让其决定缓存的响应是否可用而不是重新从源主机请求
Wait:等待时常,单位秒
WWW-Authenticate:标识访问请求实体的身份验证方案
X-Content-Type-Options:阻止IE在响应中嗅探定义的内容格式以外的其他MIME格式
X-Powered-By:指定支持web应用的技术
X-XSS-Protection:过滤跨站脚本
响应体通常会根据响应头设置的MIME类型来指定不同格式
至此,我们已经了解了HTTP协议,接下类我们用JAVA代码写段爬虫程序测试一下。
我构建的是maven工程,首先导入我们需要用到的工具jsoup maven依赖:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
</dependency>
我们以中国移动作为爬取目标,采用短信验证码形式登陆:
第一步:发送短信验证码,抓包分析
上图可以看到我们请求的数据格式是from表单提交的格式,下面我们来用代码实现这个操作吧
//发送短信,获取短信验证码
public static String getNote(String mobile){
String note = null;
String url = "https://login.10086.cn/sendRandomCodeAction.action";
//获取请求连接
Connection con = Jsoup.connect(url);
//添加请求头信息
con.header("Content-Type", "application/x-www-form-urlencoded");
//添加请求体
con.data("userName",mobile);
con.data("type","01");
con.data("channelID","12003");
try {
Document doc = con.post();
System.out.println(doc);
if("0".equals(doc.select("body").text())){
System.out.println("发送成功,请输入短信验证码:");
Scanner sc=new Scanner(System.in);
note = sc.nextLine();
sc.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return note;
}拿到短信之后我们就要去登陆了,我们先分析下登陆的请求参数
//模拟登陆
public static String loginGetCookie(String note,String mobile){
String cookie =null;
try {
String url = "https://login.10086.cn/login.htm";
//这里是登陆是get请求,所以我们的请求参数可以拼接在url后面
StringBuffer sb =new StringBuffer(url);
sb.append("?accountType=01&"); //与短信验证码一致
sb.append("account=").append(mobile).append("&"); //登陆账号(手机号)
sb.append("password=").append(note).append("&"); //短信验证码
sb.append("pwdType=02&"); //密码类型
sb.append("smsPwd=&"); //应该是字符验证码
//sb.append("inputCode=http://shop.10086.cn/i/&");
sb.append("inputCode=").append(java.net.URLEncoder.encode("http://shop.10086.cn/i/&","UTF-8"));
sb.append("rememberMe=0&"); //不知道什么鬼,带上就行
sb.append("channelID=12003&"); //登陆渠道,与短信验证码一致
//sb.append("protocol=https:&"); //应该是标记https请求的
sb.append("protocol=").append(java.net.URLEncoder.encode("https:&","UTF-8"));
//时间戳 这个是精确到毫秒的
sb.append("timestamp=").append(System.currentTimeMillis());
System.out.println("请求路径"+sb.toString());
//获取请求连接
Connection con = Jsoup.connect(sb.toString());
//添加请求头信息
con.header("Accept", "application/json, text/javascript, */*; q=0.01");
con.header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36");
con.header("Referer", "https://login.10086.cn/?channelID=12019&backUrl=http://jf.10086.cn/targetUrl=");
con.ignoreContentType(true);
//获取文档对象
//Document document = con.get();
//System.out.println(document);
//获取登陆后的cookie
Response response = con.method(Method.GET).execute();
Map<String, String> cookies = response.cookies();
System.out.println(cookies);
//拼接cookie,返回用作获取登陆后数据的钥匙
StringBuffer cs = new StringBuffer();
for (String key : cookies.keySet()) {
cs.append(key).append("=").append(cookies.get(key)).append("; ");
}
cookie = cs.substring(0, cs.length()-2);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookie;
}至此,我们已经拿到登陆后的cookie,然后我们去拿登陆后的用户信息易如反掌,看看我们登陆后页面数据的样子。
然后同样按照上面的请求方式,唯一不同的是带上我们获取到的cookie去访问这些接口,至此,你想要的数据都可以拿到了,开心吧~

相关文章推荐
- Java基础 HTTP协议
- Java中基于HTTP协议网络编程
- Java 和 Http 协议
- Java Http协议服务器demo
- java HTP协议之HttpConnUtil
- java http协议 多线程断点续传
- JavaWeb---总结(五)Http协议
- Java爬虫(八)-- httpClient进阶:HTTPS和证书认证(原理总结篇)
- Java爬虫进阶-Jsoup+httpclient获取动态生成的数据
- JAVA爬虫初识之httpclient与jsoup
- java学习之HTTP协议介绍
- 一个下载SVN源码+http协议的java实现
- Android学习笔记:Http协议及Java Web编程
- 几种java通信(rmi,http,hessian,webservice)协议性能比较
- Java简单爬虫系列(2)---HttpClient的使用
- HttpClient详解,Java发送Http的post、get方式请求 --待整理
- http协议知识整理(转)
- 修改端口Tomcat配置https协议、以及http协议自动REDIRECT到HTTPS-java教程
- java中servletContextListener、httpSessionListener和servletRequestListener使用整理
- 几种java通信(rmi,http,hessian,webservice)协议性能比较