Spark源码分析之Task
2017-11-10 21:04
375 查看
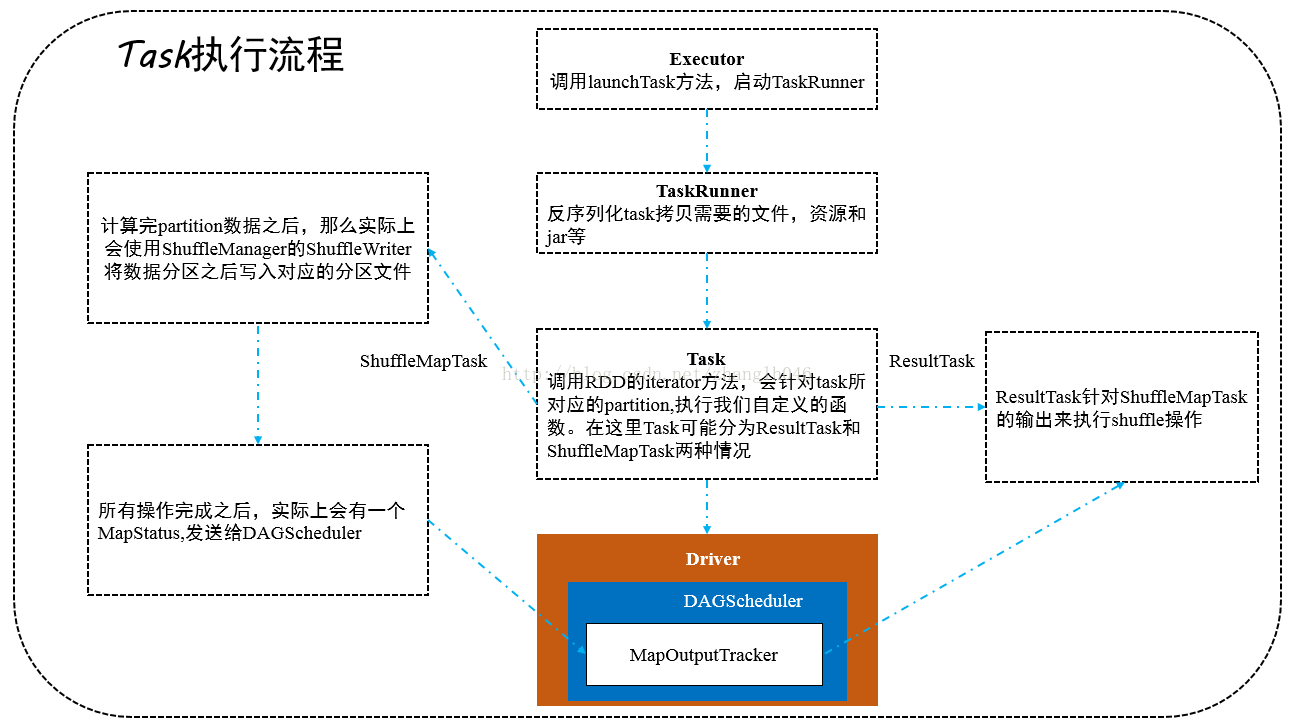
一 TaskRunner 运行task
override defrun(): Unit = {
val threadMXBean=
ManagementFactory.getThreadMXBean
// 构建task内存管理器
val taskMemoryManager=
new TaskMemoryManager(env.memoryManager,taskId)
val deserializeStartTime=
System.currentTimeMillis()
val deserializeStartCpuTime=
if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
Thread.currentThread.setContextClassLoader(replClassLoader)
val ser
= env.closureSerializer.newInstance()
logInfo(s"Running$taskName (TID$taskId)")
// 向Driver终端发送状态更新请求
execBackend.statusUpdate(taskId,TaskState.RUNNING,EMPTY_BYTE_BUFFER)
var taskStart: Long =0
var taskStartCpu: Long =0
startGCTime =
computeTotalGcTime()
try {
// 对序列化的task的数据反序列化
val (taskFiles,taskJars,
taskProps,taskBytes) =
Task.deserializeWithDependencies(serializedTask)
// Must be setbefore updateDependencies() is called, in case fetching dependencies
// requires access to propertiescontained within (e.g. for access control).
Executor.taskDeserializationProps.set(taskProps)
// 通过网络通信,将所需要的文件、资源,jar等拷贝过来
updateDependencies(taskFiles,taskJars)
// 将整个task进行反序列化
task =
ser.deserialize[Task[Any]](taskBytes,Thread.currentThread.getContextClassLoader)
task.localProperties=
taskProps
task.setTaskMemoryManager(taskMemoryManager)
// 在反序列化之前,task就被kill,抛出TaskKilledException
if (killed) {
throw new TaskKilledException
}
logDebug("Task "+
taskId + "'s epoch is "
+ task.epoch)
env.mapOutputTracker.updateEpoch(task.epoch)
// Run theactual task and measure its runtime.
// 运行实际任务并且开始测量运行时间
taskStart =
System.currentTimeMillis()
taskStartCpu =
if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
var threwException=
true
// 获取执行task返回的结果,如果是ShuffleMapTask那么这儿就是MapStatus,封装了输出的位置
val value=
try {
val res
= task.run(
taskAttemptId=
taskId,
attemptNumber=
attemptNumber,
metricsSystem=
env.metricsSystem)
threwException=
false
res
} finally {
val releasedLocks=
env.blockManager.releaseAllLocksForTask(taskId)
val freedMemory=
taskMemoryManager.cleanUpAllAllocatedMemory()
if (freedMemory>
0 && !threwException) {
val errMsg=
s"Managed memory leak detected; size = $freedMemory bytes, TID =$taskId"
if (conf.getBoolean("spark.unsafe.exceptionOnMemoryLeak",false))
{
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
if (releasedLocks.nonEmpty&& !threwException) {
val errMsg=
s"${releasedLocks.size} block locks were not released by TID =$taskId:\n"+
releasedLocks.mkString("[",", ",
"]")
if (conf.getBoolean("spark.storage.exceptionOnPinLeak",false))
{
throw new SparkException(errMsg)
} else {
logWarning(errMsg)
}
}
}
// task结束时间
val taskFinish=
System.currentTimeMillis()
val taskFinishCpu=
if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
// If the taskhas been killed, let's fail it.
if (task.killed) {
throw new TaskKilledException
}
// 对结果进行序列化和封装,因为要发给driver
val resultSer=
env.serializer.newInstance()
val beforeSerialization=
System.currentTimeMillis()
val valueBytes=
resultSer.serialize(value)
val afterSerialization=
System.currentTimeMillis()
// metrics相关的操作
task.metrics.setExecutorDeserializeTime(
(taskStart -
deserializeStartTime) + task.executorDeserializeTime)
task.metrics.setExecutorDeserializeCpuTime(
(taskStartCpu -
deserializeStartCpuTime) + task.executorDeserializeCpuTime)
// We need tosubtract Task.run()'s deserialization time to avoid double-counting
task.metrics.setExecutorRunTime((taskFinish-
taskStart) - task.executorDeserializeTime)
task.metrics.setExecutorCpuTime(
(taskFinishCpu -
taskStartCpu) - task.executorDeserializeCpuTime)
task.metrics.setJvmGCTime(computeTotalGcTime() -startGCTime)
task.metrics.setResultSerializationTime(afterSerialization-beforeSerialization)
// 统计task累加器
val accumUpdates = task.collectAccumulatorUpdates()
// 构建直接的task结果
val directResult=
new DirectTaskResult(valueBytes,accumUpdates)
// 序列化直接结果
val serializedDirectResult=
ser.serialize(directResult)
// 获取直接结果的限制
val resultSize=
serializedDirectResult.limit
/*
* 根据 resultSize(序列化后的 task结果大小)大小的不同,共有三种情况
* 1 直接结果超过1GB(可配置)直接丢弃
* 2 直接结果如果超过阀值但是小于1GB,转化为IndirectTaskResult,不是直接向driver发送结果
* 而是通过BlockManager获取
* 3 如果直接结果没有超过阀值,则会直接发送回driver
*/
val serializedResult:ByteBuffer
= {
if (maxResultSize>
0 && resultSize>
maxResultSize) {
logWarning(s"Finished$taskName (TID$taskId).
Result is larger than maxResultSize "+
s"(${Utils.bytesToString(resultSize)} >${Utils.bytesToString(maxResultSize)}),
"+
s"droppingit.")
ser.serialize(newIndirectTaskResult[Any](TaskResultBlockId(taskId),resultSize))
} else if (resultSize>
maxDirectResultSize) {
val blockId=
TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished$taskName (TID$taskId).$resultSize
bytes result sent via BlockManager)")
ser.serialize(newIndirectTaskResult[Any](blockId,resultSize))
} else {
logInfo(s"Finished$taskName (TID$taskId).$resultSize
bytes result sent to driver")
serializedDirectResult
}
}
// 调用executor所在的scheduler backend的statusUpdate方法
execBackend.statusUpdate(taskId,TaskState.FINISHED,serializedResult)
} catch {
//……省略
}
finally {
runningTasks.remove(taskId)
}
}
}
二 Task 所有类型task的父类
不同的task类型,运行task的过程可能不一样,比如ResultTask和ShuffleMapTask
final def run(taskAttemptId: Long, attemptNumber: Int,
metricsSystem: MetricsSystem): T = {
SparkEnv.get.blockManager.registerTask(taskAttemptId)
// 创建一个TaskContext,记录task执行的一些全局性的数据,比如task重试几次,属于哪个stage,哪一个partition
context = new TaskContextImpl(stageId, partitionId,
taskAttemptId, attemptNumber, taskMemoryManager,
localProperties, metricsSystem, metrics)
TaskContext.setTaskContext(context)
taskThread = Thread.currentThread()
if (_killed) {
kill(interruptThread = false)
}
new CallerContext("TASK", appId, appAttemptId, jobId, Option(stageId), Option(stageAttemptId),
Option(taskAttemptId), Option(attemptNumber)).setCurrentContext()
try {
// 调用runTask方法,因为根据不同task类型,执行task过程不一样,比如ShuffleMapTask和ResultTask
runTask(context)
} catch {
case e: Throwable =>
// Catch all errors; run task failure callbacks, and rethrow the exception.
try {
context.markTaskFailed(e)
} catch {
case t: Throwable =>
e.addSuppressed(t)
}
throw e
} finally {
// 调用task完成的回调
context.markTaskCompleted()
try {
Utils.tryLogNonFatalError {
// Release memory used by this thread for unrolling blocks
SparkEnv.get.blockManager.memoryStore.releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP)
SparkEnv.get.blockManager.memoryStore.releaseUnrollMemoryForThisTask(MemoryMode.OFF_HEAP)
// Notify any tasks waiting for execution memory to be freed to wake up and try to
// acquire memory again. This makes impossible the scenario where a task sleeps forever
// because there are no other tasks left to notify it. Since this is safe to do but may
// not be strictly necessary, we should revisit whether we can remove this in the future.
val memoryManager = SparkEnv.get.memoryManager
memoryManager.synchronized { memoryManager.notifyAll() }
}
} finally {
TaskContext.unset()
}
}
}三 ShuffleMapTask的runTask
ShuffleMapTask会将RDD元素分成多个bucket,基于一个在ShuffleDependency中指定的paritioner,默认是HashPartitioner
override def runTask(context: TaskContext): MapStatus = {
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
// 使用广播变量反序列化RDD数据
// 每一个task可能运行在不同的executor进程,都是并行运行的,每一个stage中的task要处理的RDD数据都是一样的
// task是怎么拿到自己的数据的呢? => 通过广播变量拿到数据
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
// 获取ShuffleManager已经根据ShuffleManager获取ShuffleWriter
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
// 调用rdd的ietartor方法,并且传入了需要处理的该RDD的哪一个partition
// 所以核心的逻辑在rdd#iterator中,这样就实现了针对rdd的某一个partition执行我们自己定义的算子或者函数
// 执行完我们定义算子或者函数,相当于针对rdd的partition执行了处理,就返回一些数据,返回的数据都是通过
// ShuffleWriter结果HashPartitioner进行分区之后写入自己对应的bucket中
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
// 返回MapStatus,它封装了ShuffleMapTask计算后的数据存储在哪里
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}四 ResultTask的runTask
五 RDD的iterator方法
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
// 进行rdd partition的计算
computeOrReadCheckpoint(split, context)
}
}六 RDD的computeOrReadCheckpoint
private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] =
{
// 计算rdd分区或者从checkpoint读取,如果rdd被checkpoint了
if (isCheckpointedAndMaterialized) {
firstParent[T].iterator(split, context)
} else {// 各个RDD根据我们自己指定的算子或函数运行分区数据 compute(split, context) } }

相关文章推荐
- spark1.2.0源码分析之ShuffleMapTask
- Spark1.6.3 Driver端 task运行完成源码分析
- Apache Spark源码走读之3 -- Task运行期之函数调用关系分析
- Apache Spark源码走读之3 -- Task运行期之函数调用关系分析
- Spark中job、stage、task的划分+源码执行过程分析
- Spark源码分析之八:Task运行(二)
- Spark2.2源码之Task任务提交源码分析
- spark work task 源码分析
- spark core源码分析10 Task的运行
- spark源码学习(八)--- executor启动task分析
- Spark源码分析之六:Task调度(二)
- Spark源码分析之五:Task调度(一)
- spark源码阅读3-Task运行期之函数调用关系分析
- Spark源码分析之七:Task运行(一)
- Spark 源码分析 -- Task
- Spark1.6.3 Driver端 task调度源码分析
- Apache Spark源码走读之3 -- Task运行期之函数调用关系分析
- Apache Spark源码走读之3 -- Task运行期之函数调用关系分析
- Spark源码分析之TaskSchedule和SparkDeployScheduleBackended的初始化
- Spark源码分析之八:Task运行(二)