《深度学习——Andrew Ng》第二课第一周编程作业
2017-11-04 11:01
696 查看
Initialization
作业通过三种不同的初始化参数的方式(zero、random、he),对神经网络进行参数初始化,通过对比,得出每种初始化方式的特征。最后结论为he初始化是最好的方式。程序
原始数据集:
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
from init_utils import sigmoid, relu, compute_loss, forward_propagation, backward_propagation
from init_utils import update_parameters, predict, load_dataset, plot_decision_boundary, predict_dec
#%matplotlib inline
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# load image dataset: blue/red dots in circles
train_X, train_Y, test_X, test_Y = load_dataset()
def model(X, Y, learning_rate=0.01, num_iterations=15000, print_cost=True, initialization="he"):
"""
Implements a three-layer neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SIGMOID.
Arguments:
X -- input data, of shape (2, number of examples)
Y -- true "label" vector (containing 0 for red dots; 1 for blue dots), of shape (1, number of examples)
learning_rate -- learning rate for gradient descent
num_iterations -- number of iterations to run gradient descent
print_cost -- if True, print the cost every 1000 iterations
initialization -- flag to choose which initialization to use ("zeros","random" or "he")
Returns:
parameters -- parameters learnt by the model
"""
grads = {}
costs = [] # to keep track of the loss
m = X.shape[1] # number of examples
layers_dims = [X.shape[0], 10, 5, 1]
# Initialize parameters dictionary.
if initialization == "zeros":
parameters = initialize_parameters_zeros(layers_dims)
elif initialization == "random":
parameters = initialize_parameters_random(layers_dims)
elif initialization == "he":
parameters = initialize_parameters_he(layers_dims)
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.
a3, cache = forward_propagation(X, parameters)
# Loss
cost = compute_loss(a3, Y)
# Backward propagation.
grads = backward_propagation(X, Y, cache)
# Update parameters.
parameters = update_parameters(parameters, grads, learning_rate)
# Print the loss every 1000 iterations
if print_cost and i % 1000 == 0:
print("Cost after iteration {}: {}".format(i, cost))
costs.append(cost)
# plot the loss
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
# GRADED FUNCTION: initialize_parameters_zeros
def initialize_parameters_zeros(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
parameters = {}
L = len(layers_dims) # number of layers in the network
for l in range(1, L):
### START CODE HERE ### (≈ 2 lines of code)
parameters['W' + str(l)] = np.zeros((layers_dims[l], layers_dims[l - 1]))
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
### END CODE HERE ###
return parameters
print("******************** zero initialization ****************")
parameters = model(train_X, train_Y, initialization = "zeros")
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
# GRADED FUNCTION: initialize_parameters_random
def initialize_parameters_random(layers_dims):
"""
Arguments:
layer_dims -- python
c3a0
array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
np.random.seed(3) # This seed makes sure your "random" numbers will be the as ours
parameters = {}
L = len(layers_dims) # integer representing the number of layers
for l in range(1, L):
### START CODE HERE ### (≈ 2 lines of code)
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * 10
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
### END CODE HERE ###
return parameters
print("******************** random initialization ****************")
parameters = model(train_X, train_Y, initialization = "random")
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
# GRADED FUNCTION: initialize_parameters_he
def initialize_parameters_he(layers_dims):
"""
Arguments:
layer_dims -- python array (list) containing the size of each layer.
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])
b1 -- bias vector of shape (layers_dims[1], 1)
...
WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])
bL -- bias vector of shape (layers_dims[L], 1)
"""
np.random.seed(3)
parameters = {}
L = len(layers_dims) - 1 # integer representing the number of layers
for l in range(1, L + 1):
### START CODE HERE ### (≈ 2 lines of code)
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * np.sqrt(
2. / layers_dims[l - 1])
parameters['b' + str(l)] = np.zeros((layers_dims[l], 1))
### END CODE HERE ###
return parameters
print("******************** He initialization ****************")
parameters = model(train_X, train_Y, initialization = "he")
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)运行结果
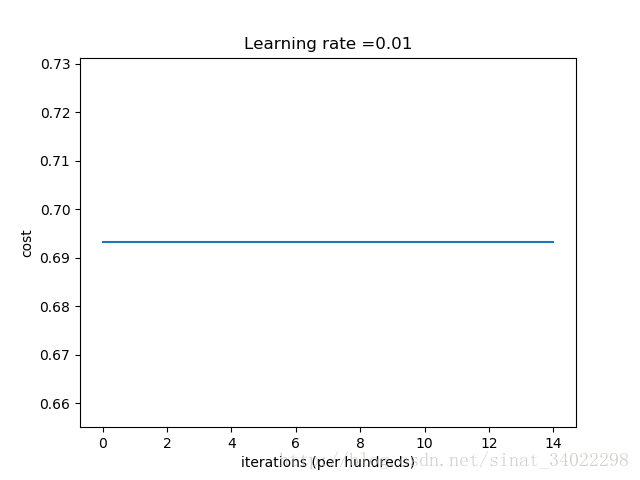
[b]**********[/b] zero initialization [b]******[/b]Cost after iteration 0: 0.6931471805599453
Cost after iteration 1000: 0.6931471805599453
Cost after iteration 2000: 0.6931471805599453
Cost after iteration 3000: 0.6931471805599453
Cost after iteration 4000: 0.6931471805599453
Cost after iteration 5000: 0.6931471805599453
Cost after iteration 6000: 0.6931471805599453
Cost after iteration 7000: 0.6931471805599453
Cost after iteration 8000: 0.6931471805599453
Cost after iteration 9000: 0.6931471805599453
Cost after iteration 10000: 0.6931471805599455
Cost after iteration 11000: 0.6931471805599453
Cost after iteration 12000: 0.6931471805599453
Cost after iteration 13000: 0.6931471805599453
Cost after iteration 14000: 0.6931471805599453
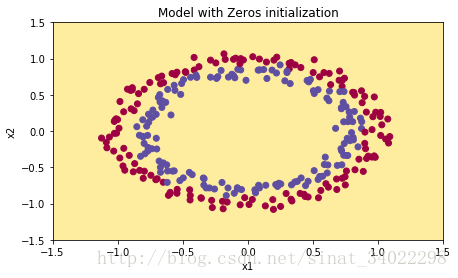
On the train set:
Accuracy: 0.5
On the test set:
Accuracy: 0.5
[b]**********[/b] random initialization [b]******[/b]
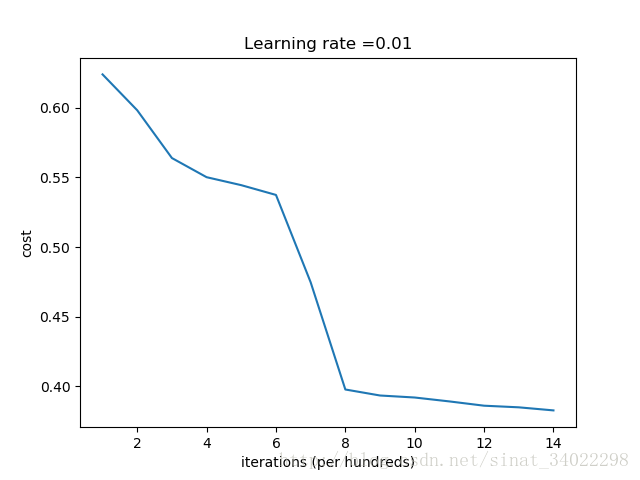
Cost after iteration 0: inf
Cost after iteration 1000: 0.6239560077799974
Cost after iteration 2000: 0.5981988756495555
Cost after iteration 3000: 0.5639165098349239
Cost after iteration 4000: 0.5501730606234159
Cost after iteration 5000: 0.5444478976702423
Cost after iteration 6000: 0.5374387172653514
Cost after iteration 7000: 0.47472803691077003
Cost after iteration 8000: 0.397783817035777
Cost after iteration 9000: 0.39347128330744535
Cost after iteration 10000: 0.39202801461972386
Cost after iteration 11000: 0.389225947340669
Cost after iteration 12000: 0.38615256867920933
Cost after iteration 13000: 0.3849845104125972
Cost after iteration 14000: 0.3827782795015039
On the train set:
Accuracy: 0.83
On the test set:
Accuracy: 0.86

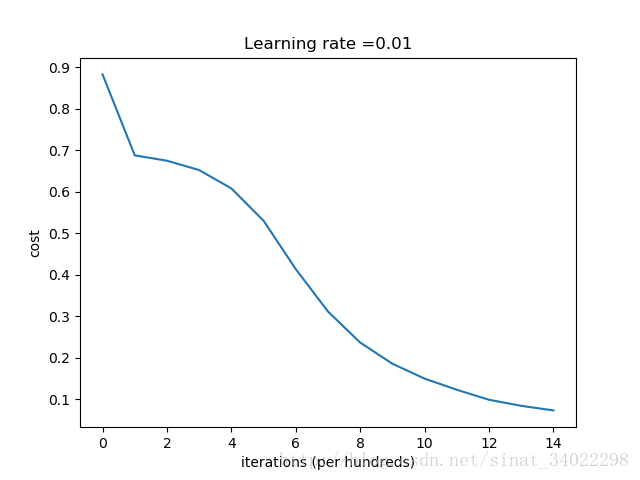
[b]**********[/b] He initialization [b]******[/b]
Cost after iteration 0: 0.8830537463419761
Cost after iteration 1000: 0.6879825919728063
Cost after iteration 2000: 0.6751286264523371
Cost after iteration 3000: 0.6526117768893807
Cost after iteration 4000: 0.6082958970572938
Cost after iteration 5000: 0.5304944491717495
Cost after iteration 6000: 0.4138645817071794
Cost after iteration 7000: 0.31178034648444414
Cost after iteration 8000: 0.23696215330322562
Cost after iteration 9000: 0.1859728720920683
Cost after iteration 10000: 0.1501555628037181
Cost after iteration 11000: 0.12325079292273544
Cost after iteration 12000: 0.09917746546525931
Cost after iteration 13000: 0.08457055954024274
Cost after iteration 14000: 0.07357895962677363
On the train set:
Accuracy: 0.993333333333
On the test set:
Accuracy: 0.96

Process finished with exit code 0
结论
You have seen three different types of initializations. For the same number of iterations and same hyperparameters the comparison is:| **Model** | **Train accuracy** | **Problem/Comment** |
| 3-layer NN with zeros initialization | 50% | fails to break symmetry |
| 3-layer NN with large random initialization | 83% | too large weights |
| 3-layer NN with He initialization | 99% | recommended method |
- Different initializations lead to different results
- Random initialization is used to break symmetry and make sure different hidden units can learn different things
- Don’t intialize to values that are too large
- He initialization works well for networks with ReLU activations.

相关文章推荐
- 《深度学习——Andrew Ng》第二课第二周编程作业
- 《深度学习——Andrew Ng》第一课第二周编程作业
- 【网易云课堂】Java语言程序设计进阶----第一周编程作业
- java第一周编程作业
- 吴恩达 Coursera Deep Learning 第五课 Sequence Models 第一周编程作业 1(部分选做)
- 第一周编程作业 温度转换
- 第一周编程作业1 温度转换
- 吴恩达 Coursera Deep Learning 第五课 Sequence Models 第一周编程作业 2
- 吴恩达 Coursera Deep Learning 第五课 Sequence Models 第一周编程作业 3
- 第一周编程作业--1求最大公约数和最小公倍数2排序并插入
- 第一周编程作业: Maximum Subsequence Sum
- 第一周编程作业:二分查找
- 《深度学习——Andrew Ng》第四课第四周编程作业_1
- 第一周编程作业:1. 最大子列和问题
- 网易云课堂java程序设计(第一周编程作业)
- 网易云课堂java程序设计(第一周编程作业)
- 《深度学习——Andrew Ng》第一课第三周编程作业
- Windows核心编程学习笔记 第二部分 完成编程任务 第5章 作业
- Coursera 吴恩达 Deep Learning 第二课 改善神经网络 Improving Deep Neural Networks 第二周 编程作业代码Optimization methods
- 《程序设计进阶—Java语言.翁恺》第一周编程作业-分数