误差与最大似然估计的个人理解
2017-11-03 23:30
471 查看
[b]1. 误差:[/b]

[假设]:误差 ε 是独立同分布的,并且服从均值为0方差为θ^2的高斯分布
误差指的是实际值与预测值之间的差值
以银行贷款为例:
独立:张三和李四一起来贷款,他俩没任何关系
同分布:张三和李四都来的是我们假定的这家银行来贷款
高斯分布:银行可能会多贷款,也可能少贷款,但是绝大多数情况下,这个贷款的差额的浮动不会太大(这里所说的的多贷款,少贷款是银行实际贷款和预测贷款之间的差别)
下面展示高斯分布(正态分布)的图像:
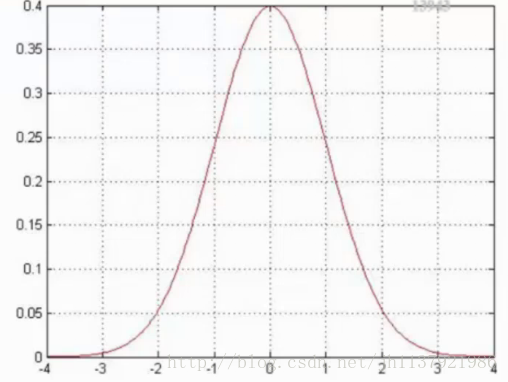
高斯分布的积分为1,所以可以把闭区间的面积看作概率,中间区域的面积最大,说明值落在中间的概率大,由图可知,有大概率的点是落在x=0附近的,高斯分布的纵坐标无实际意义,纵坐标的值与方差θ的平方有关,θ越大,表示样本的震荡幅度越大(不会密集的分布在0附近),那么图像就越矮,纵坐标越小。
[b]2.似然函数L(θ):[/b]
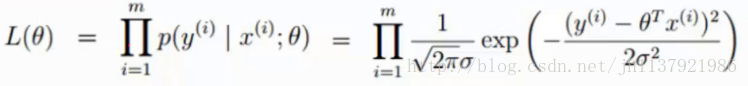
目的:计算出什么样的参数θ和我们的数据(x,y)组合之后,能满足我们的真实值
形象理解:比如说我们掷硬币,掷了十次,结果是九次正面朝上,一次反面朝上,那么认为下一次正面朝上的概率θ就是90%;
似然函数就是用结果(或样本)(9正,1负的数据)来推算参数(weight权重、概率),也就是说通过参数θ得到的预测的算法,能够尽可能地拟合样本数据(已知结果),从而最大化的使得预测结果更偏向于真实数据。
似然函数说白了就是结果导向,由已知结果来推算出预测参数θ,因为结果已经发生了,那么概率p(y|x;θ)肯定是取最大的!
这里的似然函数是怎么来的:
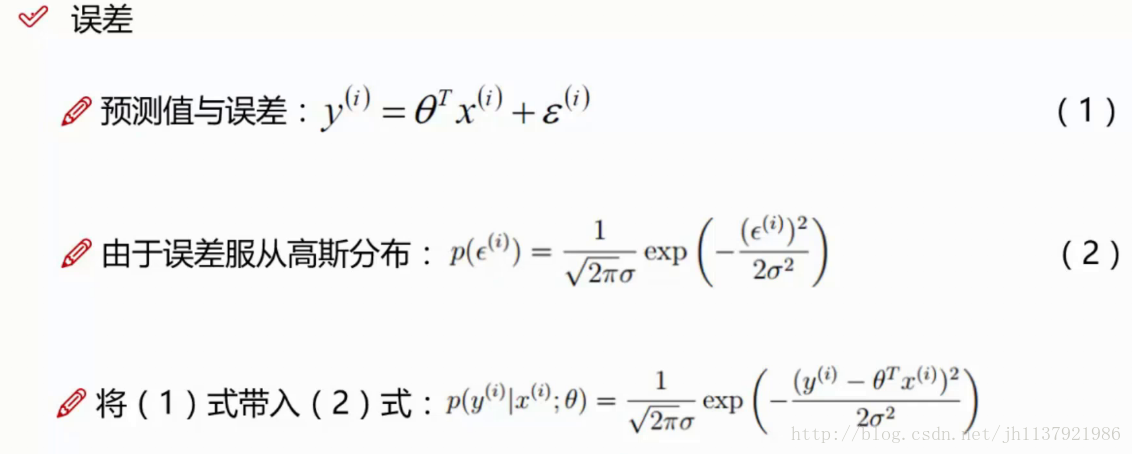
(1)式是已知的,(2)式我们假设的,那么将(1)代入(2),就可以得到一个新的关于参数θ的函数,这就是一个似然函数。
注:前面的括号里面的参数,经查阅资料,分号前面的表示已知量、确定值,分号后面的是自变量,所以似然函数就是一个关于θ的函数,所以可以简写成L(θ)
极大似然值或最大似然估计 ——分析如下:
最大似然估计,英文名是 maximum likelihood estimation, MLE,最大的可能性估计,这里的可能性 我理解为预测参数与样本中的x结合,使得样本结果y发生的概率
*从公式的角度理解:
我们追求的目标是预测值与实际值越接近越好,那么换句话说就是希望误差ε越小越好,甚至接近于零。
前面解释了似然函数是用数据来推算参数,通俗的说,我们用结果来计算参数值,而我们想要的结果是预测值=实际值,即ε->0,ε的取值处于0的附近;那么也就是说p(ε)的值要越大越好(前面解释过了,概率越大,ε的分布越是集中在0附近)
我们也知道,p(ε)的值和p(y|x;θ)的值是相等的,那么(p(y|x;θ)的概率也是越大越好。
那么为什么极大似然函数是一个累乘的概率积呢,因为一个单独的似然函数,概率最大时解出的θ是最满足那一个样本的参数θ,而我们的目标是要训练出一个拟合全部样本数据的θ,那么我们就不得不用累乘,来求一个联合概率密度,这个值最大时,表示 θ 使得样本集中预测值与真实值的偏差是最小的!
对数似然的计算
提供一个思路:似然函数是一个连乘的计算,这样的话,求解肯定是很不方便的,所以我们给它加上一个log函数,加上log之后,变化形式是,累乘变累加,log从累乘符的外边进入到累加符的里面,对每一项求对数,然后对数里面,log(A*B) = logA+logB,可以再次进行变形了。
相关文章推荐
- 最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解
- 转 通俗理解 最小二乘 和 最大似然估计
- 最大似然估计的通俗理解(2013.9.29)
- 通俗理解最大似然估计,最大后验概率估计,贝叶斯估计
- 如何理解最大似然估计?
- 模式分类对于最大似然参数估计与贝叶斯参数估计的一些理解
- 最大似然估计(Maximum likelihood estimation)(通过例子理解)
- 我们该如何理解最大似然估计???
- 最大似然估计MLE和最大后验估计MAP理解
- 详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解
- 理解最大似然估计
- 最大似然估计 (MLE)与 最大后验概率(MAP)在机器学习中的应用
- 最大似然估计与贝叶斯估计
- 线性拟合——从最大似然估计到平方误差到huber loss
- 语音识别一些概率知识--似然估计/最大似然估计/高斯混合模型
- 最大似然估计
- 最大似然参数估计
- 最大似然估计
- 最大似然估计学习总结
- 最大似然参数估计