分布式爬虫框架XXL-CRAWLER
2017-11-03 01:18
232 查看
《分布式爬虫框架XXL-CRAWLER》

一、简介
1.1 概述
XXL-CRAWLER 是一个分布式爬虫框架。一行代码开发一个分布式爬虫,拥有"多线程、异步、IP动态代理、分布式、JS渲染"等特性;1.2 特性
1、简洁:API直观简洁,可快速上手;2、轻量级:底层实现仅强依赖jsoup,简洁高效;
3、模块化:模块化的结构设计,可轻松扩展
4、面向对象:支持通过注解,方便的映射页面数据到PageVO对象,底层自动完成PageVO对象的数据抽取和封装返回;单个页面支持抽取一个或多个PageVO
5、多线程:线程池方式运行,提高采集效率;
6、分布式支持:通过扩展 "RunData" 模块,并结合Redis或DB共享运行数据可实现分布式。默认提供LocalRunData单机版爬虫。
7、JS渲染:通过扩展 "PageLoader" 模块,支持采集JS动态渲染数据。原生提供Jsoup(快速、推荐)和HtmlUnit(较慢、JS渲染)两种实现,支持自由扩展其他实现。
8、失败重试:请求失败后重试,并支持设置重试次数;
9、代理IP:对抗反采集策略规则WAF;
10、动态代理:支持运行时动态调整代理池,以及自定义代理池路由策略;
11、异步:支持同步、异步两种方式运行;
12、扩散全站:支持以现有URL为起点扩散爬取整站;
13、去重:防止重复爬取;
14、URL白名单:支持设置页面白名单正则,过滤URL;
15、自定义请求信息,如:请求参数、Cookie、Header、UserAgent轮询、Referrer等;
16、动态参数:支持运行时动态调整请求参数;
17、超时控制:支持设置爬虫请求的超时时间;
18、主动停顿:爬虫线程处理完页面之后进行主动停顿,避免过于频繁被拦截;
1.3 下载
文档地址
中文文档源码仓库地址
| 源码仓库地址 | Release Download |
|---|---|
| https://github.com/xuxueli/xxl-crawler | Download |
| https://gitee.com/xuxueli0323/xxl-crawler | Download |
技术交流
社区交流1.4 环境
JDK:1.7+二、快速入门
爬虫示例参考
(爬虫示例代码位于 /test 目录下)1、爬取页面数据并封装VO对象
2、爬取页面,下载Html文件
3、爬取页面,下载图片文件
4、爬取页面,代理IP方式
5、爬取公开的免费代理,生成动态代理池
6、JS渲染方式采集数据
7、分布式爬虫示例
第一步:引入Maven依赖
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-crawler</artifactId>
<version>${最新稳定版}</version>
</dependency>第二步:定义 "PageVo/页面数据对象"(可选)
在此推荐两款工具,可以直观迅速的获取页面元素的Jquery cssQuery表达式。1、Chrome DevTools:首先定位元素位置,然后从Element选中选中元素,点击右键选择“Copy + Copy selector”即可;
2、Jquery Selector Helper(Chrome插件):首先定位元素位置,然后从Element右侧打开Selector界面,然后定位元素即可;
// PageSelect 注解:从页面中抽取出一个或多个VO对象;
@PageSelect(cssQuery = "body")
public static class PageVo {
@PageFieldSelect(cssQuery = ".blog-heading .title")
private String title;
@PageFieldSelect(cssQuery = "#read")
private int read;
@PageFieldSelect(cssQuery = ".comment-content")
private List<String> comment;
// set get
}第三步:创建爬虫
XxlCrawler crawler = new XxlCrawler.Builder()
.setUrls("https://my.oschina.net/xuxueli/blog")
.setWhiteUrlRegexs("https://my\\.oschina\\.net/xuxueli/blog/\\d+")
.setThreadCount(3)
.setPageParser(new PageParser<PageVo>() {
@Override
public void parse(Document html, Element pageVoElement, PageVo pageVo) {
// 解析封装 PageVo 对象
String pageUrl = html.baseUri();
System.out.println(pageUrl + ":" + pageVo.toString());
}
})
.build();第四步:启动爬虫
crawler.start(true);
三、总体设计
架构图
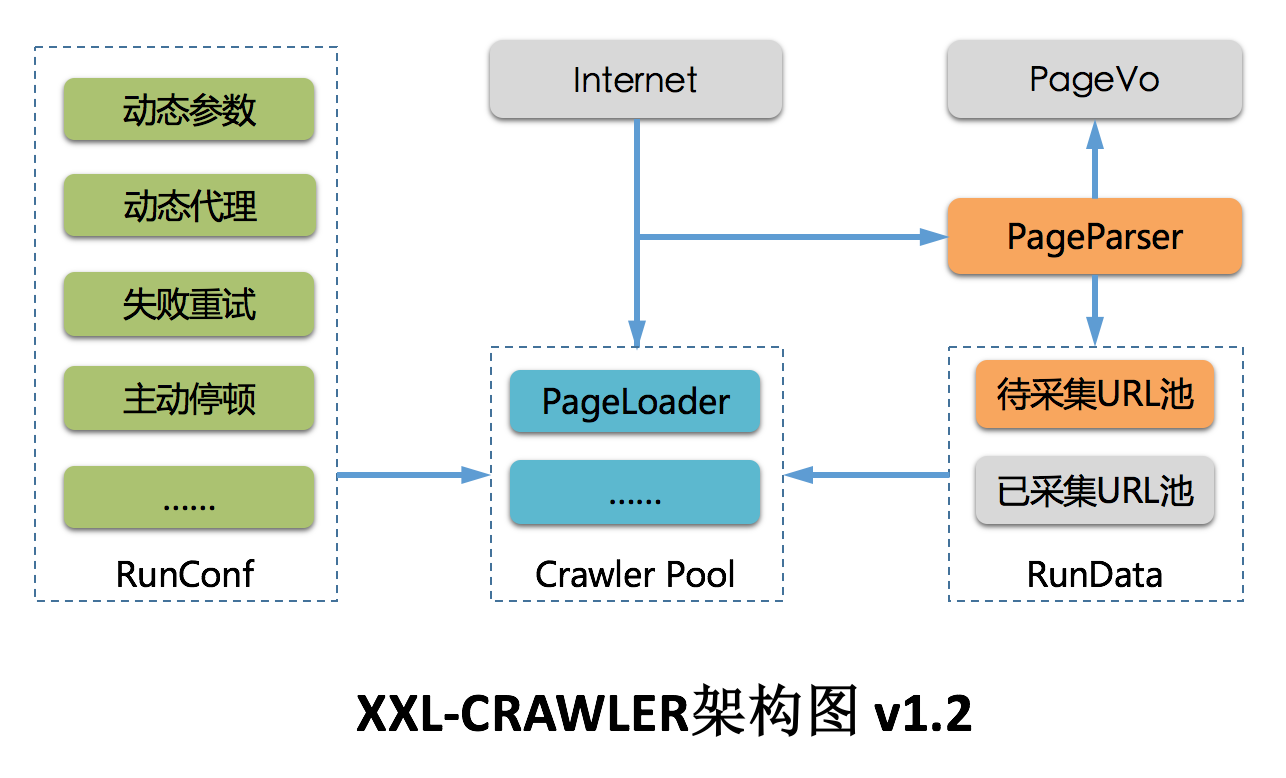
3.1 功能定位
XXL-CRAWLER 是一个分布式Web爬虫框架。采用模块化设计,各个模块可灵活进行自定义和扩展。借助 XXL-CRAWLER,一行代码开发一个分布式爬虫。
3.2 核心概念
| 概念 | 说明 |
|---|---|
| XxlCrawler | 爬虫对象,维护爬虫信息 |
| PageVo | 页面数据对象,一张Web页面可抽取一个或多个PageVo |
| PageLoader | 页面加载器,负责加载页面数据,支持灵活的自定义和扩展 |
| PageParser | 页面解析器,绑定泛型PageVO后将会自动抽取页面数据对象,同时支持运行时调整请求参数信息 |
3.3 爬虫对象:XxlCrawler
功能:爬虫对象,维护爬虫信息,可选属性如下。| 方法 | 说明 |
|---|---|
| setUrls | 待爬的URL列表 |
| setAllowSpread | 允许扩散爬取,将会以现有URL为起点扩散爬取整站 |
| setWhiteUrlRegexs | URL白名单正则,非空时进行URL白名单过滤页面 |
| setIfPost | 请求方式:true=POST请求、false=GET请求 |
| setUserAgent | UserAgent |
| setParamMap | 请求参数 |
| setCookieMap | 请求Cookie |
| setTimeoutMillis | 超时时间,毫秒 |
| setPauseMillis | 停顿时间,爬虫线程处理完页面之后进行主动停顿,避免过于频繁被拦截; |
| setProxyMaker | 代理生成器,支持设置代理IP,同时支持调整代理池实现动态代理; |
| setThreadCount | 爬虫并发线程数 |
| setPageParser | 页面解析器 |
| setPageLoader | 页面加载器,默认提供 "JsoupPageParser" 和 "HtmlUnitPageLoader" 两种实现; |
| setRunData | 设置运行时数据模型,默认提供LocalRunData单机模型,支持扩展实现分布式模型; |
| start | 运行爬虫,可通过入参控制同步或异步方式运行 |
| stop | 终止爬虫 |
3.4 核心注解:PageSelect
功能:描述页面数据对象,通过该注解从页面抽取PageVo数据信息,可选属性如下。| PageSelect | 说明 |
|---|---|
| cssQuery | CSS选择器, 如 "#body" |
3.5 核心注解:PageFieldSelect
功能:描述页面数据对象的属性信息,通过该注解从页面抽取PageVo的属性信息,可选属性如下。(支持基础数据类型 T ,包括 List<T>)
| PageFieldSelect | 说明 |
|---|---|
| cssQuery | CSS选择器, 如 "#title" |
| selectType | jquery 数据抽取方式,如 ".html()/.text()/.val()/.attr()"等 |
| selectVal | jquery 数据抽取参数,SelectType=ATTR 时有效,如 ".attr("abs:src")" |
| datePattern | 时间格式化,日期类型数据有效 |
3.6 多线程
以线程池方式并行运行,提供对应API(可参考"章节3.3")调整线程池大小,提高运行效率;3.7 异步
支持同步、异步两种方式启动运行。同步:将会阻塞业务逻辑,爬虫爬取完全部页面后才会继续执行后续逻辑。
异步:不会阻塞业务逻辑,爬虫逻辑以异步方式运行。
3.8 动态代理
ProxyMaker(代理生成器):实现代理支持的组件。支持设置代理IP,同时支持调整代理池实现动态代理;系统已经提供了两种策略实现;
RoundProxyMaker(循环代理生成器): 以循环方式获取代理池中代理;
RandomProxyMaker(随机代理生成器): 以随机方式获取代理池中代理;
3.9、PageParser
PageParser(页面解析器):绑定泛型PageVO后将会自动抽取页面数据对象,同时支持运行时调整请求参数信息;| 内部方法 | 说明 |
|---|---|
| public void preLoad(PageLoadInfo pageLoadInfo) | 可选实现,发起页面请求之前触发调用,可基于此运行时调整请求参数; |
| public void postLoad(Document html) | 可选实现,发起页面请求之后触发调用,可基于此运行时调整页面数据; |
| public abstract void parse(Document html, Element pageVoElement, T pageVo) | 必须实现,页面抽离封装每个PageVO之后触发调用,可基于此处理PageVO文档或数据; |
3.10、分布式支持 & RunData
支持自定义RunData(运行时数据模型)并结合Redis或DB共享运行数据来实现分布式爬虫。默认提供LocalRunData实现单机版爬虫。RunData:运行时数据模型,维护爬虫运行时的URL和白名单规则。
单机:单机方式维护爬虫运行数据,默认提供 "LocalRunData" 的单机版实现。
分布式/集群:集群方式维护爬虫爬虫运行数据,可通过Redis或DB定制实现。
| RunData抽象方法 | 说明 |
|---|---|
| public abstract boolean addUrl(String link); | 新增一个待采集的URL,接口需要做URL去重,爬虫线程将会获取到并进行处理; |
| public abstract String getUrl(); | 获取一个待采集的URL,并且将它从"待采集URL池"中移除,并且添加到"已采集URL池"中; |
| public abstract int getUrlNum(); | 获取待采集URL数量; |
3.11、JS动态渲染 & PageLoader
页面数据通过 "PageLoader" 组件加载,默认使用以下两种实现:JsoupPageLoader:速度最快,推荐采用这种方式(不支持JS动态渲染);
HtmlUnitPageLoader:支持JS动态渲染,速度较慢。
得益于模块化结构设计,可自由扩展其他 "PageLoader" 实现,如 "Selenium" 方式等;
注意:
1、HtmlUnitPageLoader 为扩展功能,因此maven依赖(htmlunit)scope为provided类型,使用时请单独引入;
2、不推荐使用JS渲染方式采集数据:
2.1:JS渲染,速度较慢;
2.1:JS渲染,环境要求较高;
2.3:在需要JS渲染的场景下,推荐做法是:分析页面请求,模拟并主动发起Ajax请求来代替JS引擎自动请求渲染。因为速度更快,更可控;
四、版本更新日志
版本 V1.0.0,新特性[2017-09-13]
1、面向对象:通过VO对象描述页面信息,提供注解方便的映射页面数据,爬取结果主动封装Java对象返回;2、多线程:线程池方式并行运行;
3、异步:支持同步、异步两种方式运行;
4、扩散全站:支持以入口URL为起点扩散爬取整站;
5、去重:防止重复爬取;
6、URL白名单:支持设置页面白名单正则,过滤URL;
7、自定义请求信息,如:请求参数、Cookie、Header、UserAgent轮询、Referrer等;
8、轻量级:底层实现仅依赖jsoup,简洁高效;
9、超时控制:支持设置爬虫请求的超时时间;
10、主动停顿:爬虫线程处理完页面之后进行主动停顿,避免过于频繁被拦截;
11、单个页面支持抽取一个或多个PageVO;
版本 V1.1.0,新特性[2017-11-08]
1、页面默认cssQuery调整为html标签;2、升级Jsoup至1.11.1版本;
3、修复PageVO注解失效的问题;
4、属性注解参数attributeKey调整为selectVal;
5、代理IP:对抗反采集策略规则WAF;
6、动态代理:支持运行时动态调整代理池,以及自定义代理池路由策略;
版本 V1.2.0,新特性[2017-12-14]
1、爬虫Builder底层API优化;2、支持设置请求Headers;
3、支持设置多UserAgent轮询;
4、失败重试:支持请求失败后主动重试,并支持设置重试次数;
5、动态参数:支持运行时动态调整请求参数;
6、分布式支持:支持自定义RunData(运行时数据模型)并结合Redis或DB共享运行数据来实现分布式。默认提供LocalRunData单机版爬虫。
版本 V1.2.1,新特性[2018-02-07]
1、JS渲染:支持JS渲染方式采集数据,可参考 "爬虫示例6";2、抽象并设计PageLoader,方便自定义和扩展页面加载逻辑,如JS渲染等。底层提供 "JsoupPageLoader(默认/推荐)","HtmlUnitPageLoader"两种实现,可自定义其他类型PageLoader如 "Selenium" 等;
3、修复Jsoup默认加载1M的限制;
4、爬虫线程中断处理优化;
版本 V1.2.2,新特性[迭代中]
TODO LIST
1、扩展SelectType;3、bloomfilter去重,可选接入,大数据量下推荐;
4、对抗爬虫蜜罐,成功率检测,历史数据学习;
5、对抗主动休眠防御,Timeout即可;
五、其他
5.1 项目贡献
欢迎参与项目贡献!比如提交PR修复一个bug,或者新建 Issue 讨论新特性或者变更。5.2 用户接入登记
更多接入的公司,欢迎在 登记地址 登记,登记仅仅为了产品推广。5.3 开源协议和版权
产品开源免费,并且将持续提供免费的社区技术支持。个人或企业内部可自由的接入和使用。Licensed under the GNU General Public License (GPL) v3.
Copyright (c) 2015-present, xuxueli.
捐赠
无论金额多少都足够表达您这份心意,非常感谢 :) 前往捐赠
相关文章推荐
- 分布式爬虫框架XXL-CRAWLER
- 分布式服务通讯框架XXL-RPC
- 分布式服务通讯框架XXL-RPC
- 使用nodejs 爬虫框架 Crawler爬取全国省市区的数据
- 基于Python+scrapy+redis的分布式爬虫实现框架
- 伪分布式网络爬虫框架的设计与自定义实现(一)
- 分布式单点登录框架XXL-SSO
- php爬虫框架crawler
- 分布式单点登录框架XXL-SSO
- 一个自定义python分布式爬虫框架。
- crawler_爬虫分布式设计图收集_01
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第2章 windows下搭建开发环境
- 基于Python,scrapy,redis的分布式爬虫实现框架
- [开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
- akka分布式爬虫框架(一)——设计思路与demo
- 分布式爬虫基本框架
- python的分布式爬虫框架
- [开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [二] 基本使用
- [开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] [一] 初衷与架构设计
- crawler_分布式网络爬虫的设计与实现_设计图