XSS初学记录
2017-11-02 23:25
281 查看
之前对基本Web安全的书籍只是单纯的阅读过了,并未动手实践。今天试着对学校图书馆进行了一下XSS漏洞的挖掘,居然还真找到一个,记录一下。
在复旦大学图书馆下面的站内搜索框中并未对用户的input进行过滤

在其中输入Test测试,

可在源码中发现是用td标签闭合的构造payload "></td><script>alert("xss")</script> 关闭Chrome过滤器后可成功弹窗。
一个很典型的反射型XSS
不过鉴于现在游览器的过滤功能这么强大,反射型XSS存在的意义还大吗?
还是说游览器只是单纯的过滤URL?有待学习一下筛查制度
在复旦大学图书馆下面的站内搜索框中并未对用户的input进行过滤

在其中输入Test测试,
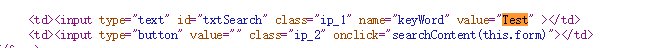
可在源码中发现是用td标签闭合的构造payload "></td><script>alert("xss")</script> 关闭Chrome过滤器后可成功弹窗。
一个很典型的反射型XSS
不过鉴于现在游览器的过滤功能这么强大,反射型XSS存在的意义还大吗?
还是说游览器只是单纯的过滤URL?有待学习一下筛查制度

相关文章推荐
- RabbitMQ初学之安装与常见问题记录
- C语言初学记录
- React Native 初学之遇到的错误记录
- React-Native 初学之组件生命周期记录
- 【初学python】错误SSLError: [Errno 1] _ssl.c:504:的解决记录
- Java -Xms -Xmx -Xss -XX:MaxNewSize -XX:MaxPermSize含义记录
- 初学linux,记录1
- xss 表单劫持(from通用明文记录)
- 菜鸟柳--23种设计模式初学记录笔记(二)装饰者设计模式
- python初学常见问题记录(3)--Ipython用法
- python初学常见问题记录(4)
- 初学Photoshop的一些记录
- Web初学-入门和tomcat介绍记录
- DOM,SAX,PULL读写xml(初学、记录)
- XSS 练习题记录
- XSS----payload,绕过,xss小游戏记录
- jsp初学记录(jsp, session, gb2312, utf-8)
- 初学C++基本知识记录
- (记录)初学python篇:一
- 初学c# -- 记录QQ键盘