python基础===获取知乎标题时候,文件编码失败的总结
2017-10-26 16:37
501 查看
总结一下,关于获取到的信息编码失败。
刚才在执行代码的时候,发现一个问题:
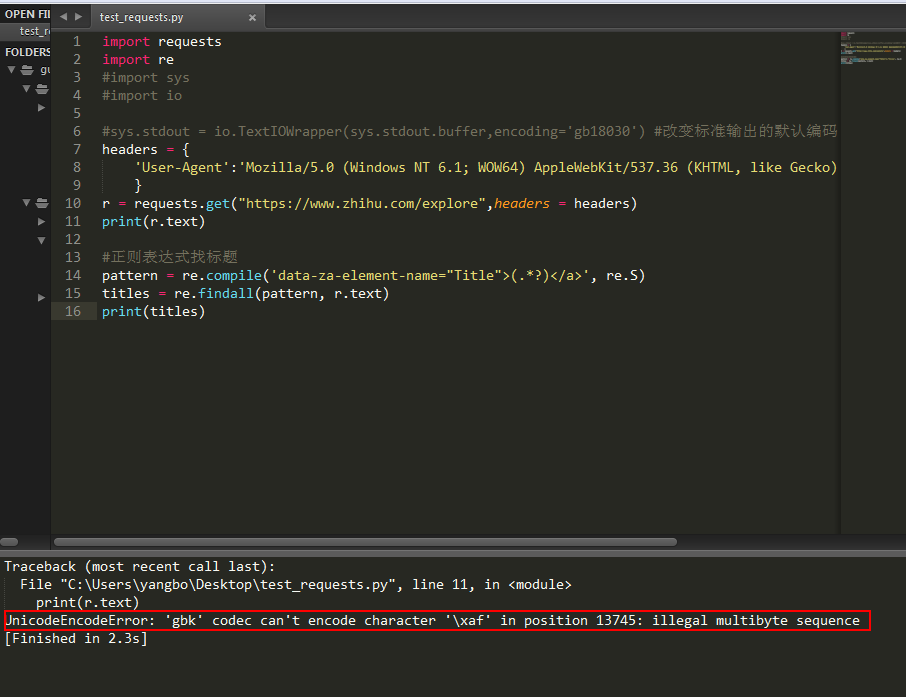
然后修改代码如下:
'''
爬取知乎界面的标题
'''
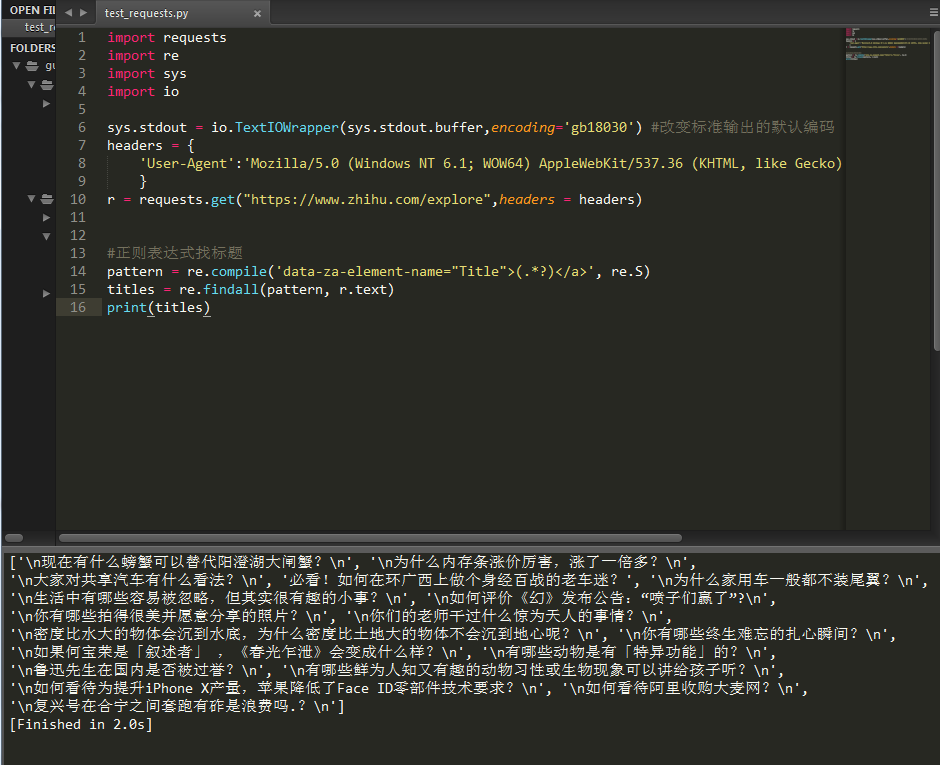
import requests import re import sys import io sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #改变标准输出的默认编码 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' } r = requests.get("https://www.zhihu.com/explore",headers = headers) print(r.text) #正则表达式找标题 pattern = re.compile('data-za-element-name="Title">(.*?)</a>', re.S) titles = re.findall(pattern, r.text) print(titles)
执行成功:

相关文章推荐
- python_基础总结1 python由来 字符编码 注释 pyc文件 python变量 导入模块 获取用户输入 流程控制if while
- python 基础 —— 获取文件路径
- Python基础 —— 获取当前文件所在目录,遍历当前目录,获取指定后缀的文件
- python基础之元组、文件操作、编码、函数、变量
- python 文件操作知识总结: 获取当前路径
- 分析:windows下cmd默认的编码是ASCII编码 ,windows的中文环境下编码是GBK 方法一:在保存输出流保存的时候做一个对文字GBK编码,在输出到文件 如下 [python] view
- python获取系统基础性能参数实现写入文件
- Python3基础 try-指定except-as reason 捕获打开一个不存在的文件的时候,会产生OSError异常的示例
- 【转】python基础===codecs打开文件,解决文件编码格式的问题
- python基础教程总结10——文件
- python3-练习-爬取网站-中文编码-获取页面源代码-保存文件
- Python3基础 getatime getctime getmtime 获取一个文件的最近访问时间 创建时间 最新修改时间
- python基础学习总结——文件操作
- python基础===codecs打开文件,解决文件编码格式的问题
- python基础之元组、文件操作、编码、函数、变量
- WebView使用(内存泄露+获取网页标题+js交互+调用浏览器下载文件+网页加载失败+清缓存)
- Windows 8 系统环境下,Python3默认编码错误,导致运行文件失败的解决方法。
- Python 获取图片文件大小并转换为base64编码
- 是该总结编码的时候了
- PHP 获取文件 或 字符串的编码方式 mb_detect_encoding()