第二次结队作业
2017-10-25 02:34
176 查看
第二次结对作业-部门学生智能匹配系统
170320078 孙敏铭170327076 余国鹏
Github地址
https://github.com/sunminming/match数据模型
部门的数据模型包括部门编号(int型,1-20),部门纳新人数(0-15),部门特色标签(字符串向量),部门活动时间(字符串),已确定学生(int型向量)。这部分需要特别注意的是部门编号不能重复,应该从1开始,每次加1。已确定学生向量record中保存已加入部门的学生学号,这个属性是在算法执行的过程中赋值的。学生的数据模型包括学生学号(int型,1-300),学生绩点(int型,1-5),学生兴趣标签(字符串向量),学生报名意愿(int型向量),学生空闲时间(字符串向量)。另外学生还有一个特别的属性intmatch,用来表示学生和当前部门的标签匹配程度,这个属性是在算法执行的过程中赋值的。学生数据模型中,学号不能重复。
部门数据格式
/部门 /部门编号 /活动时间 /部门特点标签 /部门纳新人数 /部门确定学生
部门数据截图

学生数据格式
/学生 /学号 /绩点 /学生意愿 /学生兴趣标签 /学生空闲时间 /与当前部门匹配程度
学生数据截图

数据生成方式
除了上面提到的部门编号和学生学号,每个学生或部门的兴趣个数随机生成,然后从一个“兴趣池”中随机抽取。部门活动时间和学生活动时间同理。学生的部门意愿则是随机生成一个小于5的数l(学生报名不能多于5个),而后在1-20(部门编号)中随机抽取一个数x,学生的部门意愿即为[x,x+l];部门纳新人数随机生成[0-15]中的一个,所以在我的数据中出现了3个不纳新的部门(纳新人数为0)。以上为在生成数据文件中随机生成的数据。还有两个属性:“部门的确定学生”和“与当前部门匹配程度”是在匹配算法中确定的。留在下一部分介绍。
输入输出采用文本文件.txt的方式。
匹配算法
基于结队中两人的算法并不是很好,我们在结队中使用简单的暴力算法,两重循环。第一层遍历部门,第二层遍历学生。具体过程如下: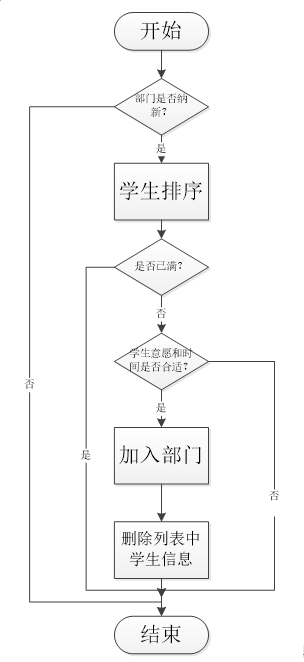
其中,学生排序时需要用到“与当前部门匹配程度(intmatch)”,这个属性可以根据优先规则进行赋值,比如兴趣越接近值越大等;而“加入部门”要将学生加入“部门确定学生(reord)”,同时将学生从列表中删除,避免两个部门同时选中同一个学生。
缺点和改正方法:
1.这个算法使用暴力循环,耗时大。更好的匹配算法我们目前还没有想出来;
2.由于时间紧迫,类的定义中缺少构造,析构和一些操作符的定义。
代码规范
类中操作选择规范为“操作+属性”。比如:添加学生的兴趣,addinterset;获得学生学号,getnum等;
结果分析
| 优先条件 | 匹配学生个数 | 未匹配学生个数 | 实际耗时 | 输出文件路径 |
|---|---|---|---|---|
| 兴趣优先 | 125 | 6 | 10.6 | https://github.com/sunminming/match/blob/master/record.txt |
| 绩点优先 | 125 | 6 | 10.9 | https://github.com/sunminming/match/blob/master/BIN/record.txt |
对于不同优先条件变更的适应能力:若要修改优先条件,比如从兴趣优先改成绩点优先或从绩点优先改成兴趣优先,只要修改排序函数中调用的两个函数即可。

