使用Eclipse构建Spark Java集成开发环境
2017-10-23 11:16
537 查看
最近在eclipse构建spark java开发环境走了很多坑,把步骤记录下来。
第一步、从spark官网上下载spark安装包,我下载的为spark-1.5.1-bin-hadoop2.6
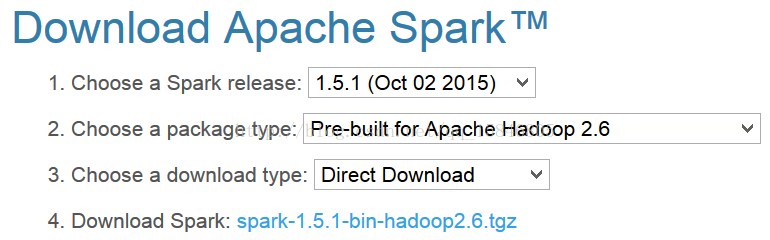
直接解压缩即可,在环境变量path中配置为你解压缩的路径+\bin,我的path为D:\spark-1.5.1-bin-hadoop2.6\bin,在cmd中输入spark-shell
第二步、在eclipse中新建一个工程,添加依赖jar包(在解压缩spark文件夹的lib目录下,我的为D:\spark-1.5.1-bin-hadoop2.6\lib)。

注意:从spark 2.0开始没有这个jar包,需要将lib文件夹下的所有jar包添加。
第三步、使用java 8的lambda表达式编写经典的wordcount。import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class test {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("word count");
JavaSparkContext sc = new JavaSparkContext(conf);
sc
.textFile(test.class.getResource("").toString()+"README.md")
.flatMap(x -> {
return Arrays.asList(x.split(""));
})
.mapToPair(x -> {
return new Tuple2<>(x,1);})
.reduceByKey((x,y) ->{
return x+y;})
.foreach(x ->
{
System.out.println(x._1+"出现了"+x._2);
});
sc.close();
}
}
运行会报错failed to locate the winutils binary in the hadoop binary path,并不影响结果,解决方法去下载对应版本的hadoop binary,我们这里去下载hadoop-2.6.0,添加环境变量path:D:\hadoop-2.6.0\bin,再次运行成功,结果截图一部分为:

第一步、从spark官网上下载spark安装包,我下载的为spark-1.5.1-bin-hadoop2.6
直接解压缩即可,在环境变量path中配置为你解压缩的路径+\bin,我的path为D:\spark-1.5.1-bin-hadoop2.6\bin,在cmd中输入spark-shell
第二步、在eclipse中新建一个工程,添加依赖jar包(在解压缩spark文件夹的lib目录下,我的为D:\spark-1.5.1-bin-hadoop2.6\lib)。
注意:从spark 2.0开始没有这个jar包,需要将lib文件夹下的所有jar包添加。
第三步、使用java 8的lambda表达式编写经典的wordcount。import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class test {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("word count");
JavaSparkContext sc = new JavaSparkContext(conf);
sc
.textFile(test.class.getResource("").toString()+"README.md")
.flatMap(x -> {
return Arrays.asList(x.split(""));
})
.mapToPair(x -> {
return new Tuple2<>(x,1);})
.reduceByKey((x,y) ->{
return x+y;})
.foreach(x ->
{
System.out.println(x._1+"出现了"+x._2);
});
sc.close();
}
}
运行会报错failed to locate the winutils binary in the hadoop binary path,并不影响结果,解决方法去下载对应版本的hadoop binary,我们这里去下载hadoop-2.6.0,添加环境变量path:D:\hadoop-2.6.0\bin,再次运行成功,结果截图一部分为:

相关文章推荐
- 使用Eclipse+Maven+Jetty构建Java Web开发环境(几个教程综合集成2014发行)
- 利用eclipse构建spark集成开发环境
- Spark:利用Eclipse构建Spark集成开发环境
- Spark:利用Eclipse构建Spark集成开发环境
- 使用Eclipse IDE搭建Apache Spark的Java开发环境
- Java - 集成开发环境Eclipse的使用方法和技巧
- windows下集成maven+eclipse开发环境二:集成maven到eclipse,并使用nexus作为maven仓库
- 基于Eclipse的TI集成开发环境IDE-CCSv5使用教程
- 【嵌入式linux】(第六步):使用eclipse集成开发环境开发第一个嵌入式Linux程序,并测试LED驱动
- 如何在 Eclipse 中使用插件构建 PHP 开发环境[转]
- 在Eclipse 集成 Tomcat,准备Java Web开发环境
- Java开发环境的搭建以及使用eclipse从头一步步创建java项目
- java开发环境eclipse的使用(模块代码折叠、可视化开发插件、生成Jar插件)
- 用Eclipse+Maven+Jetty构建Java Web开发环境(综合几篇教程整合2014年版)
- Java开发环境的搭建以及使用eclipse创建项目
- 使用Eclipse(CDT)和MinGW构建Windows上的C/C++开发环境
- 配置基于Eclipse的Java、C++、Python集成开发环境.
- java集成开发环境构建
- windows下集成maven+eclipse开发环境一:安装使用maven私服nexus
- 如何在 Eclipse 中使用插件构建 PHP 开发环境