深度学习的几个重要关键点解释
2017-10-20 19:23
267 查看
人工智能的热度逐渐上升,身边许多人都投身于这方面开始学习,所以最近我也研究了些深度学习方面的知识,在刷完了网易云Andrew Ng的课程之后就流浪在github与csdn中,虽然了解了基本原理但是感觉自己动手建立模型还是有些难度的。
在学习的过程中我会发现有几个关键点是我们必须要明确的,可能我们在听课的时候会一带而过,像是什么梯度、损失函数啊,但是如果不理解他们的作用,会很难展开接下来的学习,故在此总结出这几个模糊的概念。
1、机器学习与深度学习还有人工智能的关系
可以这么理解:深度学习是机器学习的子集,机器学习是人工智能的子集。
要搞清它们的关系,最直观的表述方式就是同心圆,最先出现的是理念,然后是机器学习,当机器学习繁荣之后就出现了深度学习,今天的AI大爆发是由深度学习驱动的。

2、什么是感知器
第一次见到这个词我也是蒙的,后来查了下发现他其实就是我们神经网络里面的神经元(据说是一个里程碑式的存在),了解神经网络的小伙伴可能瞬间就懂了,神经元其实就是做基本决策的,举个例子,我今天晚上想要打游戏,然后要考虑的是有没有作业要写、有没有朋友叫出去玩、加不加班啊。。等等,这些因素都会有相应的权重,然后把这些权重都加在一起通过激活函数来判断晚上能不能打游戏。

可以看出这个感知器有 输入的权重w、偏置项b、激活函数g()、输出向量y 正向输出通常由y = g(wx + b)推导得出
3、损失函数(loss function)
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。
4、激活函数
激活函数是为了给神经网络加入非线性的影响,不加激活函数也是可以实现的可以解决线性分类的问题,但是如果是非线性问题上效果会很差,加入了激活函数后可以让我们的神经网络解决更复杂的问题,常见的激活函数有 Sigmoid函数 tanh函数 (ReLU函数)目前ReLU是最受欢迎的,相比起Sigmoid和tanh,ReLU在SGD中能够快速收敛,有效缓解了梯度消失的问题。
激活函数部分可以参考http://blog.csdn.net/cyh_24/article/details/50593400
5、学习率
学习率的大小对模型有着极大的影响,可以通过经验手工调整尝试不同的学习率,例如1、0.1、0.3、0.001观察迭代次数与损失函数的变化,确定出loss最快的学习率,学习率决定了参数移动到最优值的速度快慢。如果学习率过大很可能会越过最优值,如果学习率过小会造成优化效率底下,收敛速度缓慢。
6、梯度下降
梯度:多元参数求偏导以向量的形式写出就是梯度
梯度下降:是用来我们优化算法的过程中最小化loss函数的方式,因为偏导数的几何意义是函数变化的快慢,所以我们可以最快寻找到函数的最小值,从而确定反向传播计算出更合适的权重w。这么说可能比较抽象,再举个Andrew Ng老师的栗子:我们在某一座高山的山顶,不知道怎么走,环视四周后每次都选择最陡峭的方向下山,每走一次就计算一次梯度,然后再次选择最陡峭的方向直到我们走到最低点,当然这里可能是局部最低点,除非损失函数是凹凸函数。
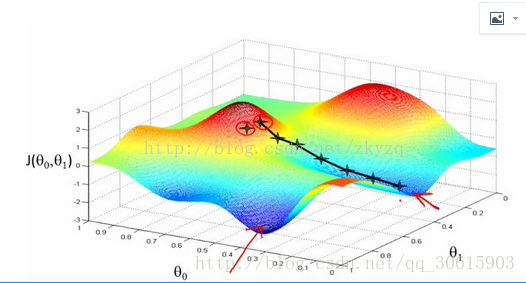
详细的推导公式请参见https://www.zybuluo.com/hanbingtao/note/448086
这篇博客给我启发很多,关于深度学习的讲解与公式推导十分详细
7、过拟合与欠拟合
过拟合与欠拟合一般在参数设置不当发生,过拟合是对于预测过于严格对于噪声没有选择性的省略,欠拟合是指要求过于宽泛是算法不能正确的分类或预测。

就先总结这么多,都是个人的一些感悟,平时都是防止遗忘总结在私有云笔记上的,第一次在csdn上发博客写的有些蹑手蹑脚,欢迎各位大牛批评指正。
在学习的过程中我会发现有几个关键点是我们必须要明确的,可能我们在听课的时候会一带而过,像是什么梯度、损失函数啊,但是如果不理解他们的作用,会很难展开接下来的学习,故在此总结出这几个模糊的概念。
1、机器学习与深度学习还有人工智能的关系
可以这么理解:深度学习是机器学习的子集,机器学习是人工智能的子集。
要搞清它们的关系,最直观的表述方式就是同心圆,最先出现的是理念,然后是机器学习,当机器学习繁荣之后就出现了深度学习,今天的AI大爆发是由深度学习驱动的。
2、什么是感知器
第一次见到这个词我也是蒙的,后来查了下发现他其实就是我们神经网络里面的神经元(据说是一个里程碑式的存在),了解神经网络的小伙伴可能瞬间就懂了,神经元其实就是做基本决策的,举个例子,我今天晚上想要打游戏,然后要考虑的是有没有作业要写、有没有朋友叫出去玩、加不加班啊。。等等,这些因素都会有相应的权重,然后把这些权重都加在一起通过激活函数来判断晚上能不能打游戏。
可以看出这个感知器有 输入的权重w、偏置项b、激活函数g()、输出向量y 正向输出通常由y = g(wx + b)推导得出
3、损失函数(loss function)
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。
4、激活函数
激活函数是为了给神经网络加入非线性的影响,不加激活函数也是可以实现的可以解决线性分类的问题,但是如果是非线性问题上效果会很差,加入了激活函数后可以让我们的神经网络解决更复杂的问题,常见的激活函数有 Sigmoid函数 tanh函数 (ReLU函数)目前ReLU是最受欢迎的,相比起Sigmoid和tanh,ReLU在SGD中能够快速收敛,有效缓解了梯度消失的问题。
激活函数部分可以参考http://blog.csdn.net/cyh_24/article/details/50593400
5、学习率
学习率的大小对模型有着极大的影响,可以通过经验手工调整尝试不同的学习率,例如1、0.1、0.3、0.001观察迭代次数与损失函数的变化,确定出loss最快的学习率,学习率决定了参数移动到最优值的速度快慢。如果学习率过大很可能会越过最优值,如果学习率过小会造成优化效率底下,收敛速度缓慢。
6、梯度下降
梯度:多元参数求偏导以向量的形式写出就是梯度
梯度下降:是用来我们优化算法的过程中最小化loss函数的方式,因为偏导数的几何意义是函数变化的快慢,所以我们可以最快寻找到函数的最小值,从而确定反向传播计算出更合适的权重w。这么说可能比较抽象,再举个Andrew Ng老师的栗子:我们在某一座高山的山顶,不知道怎么走,环视四周后每次都选择最陡峭的方向下山,每走一次就计算一次梯度,然后再次选择最陡峭的方向直到我们走到最低点,当然这里可能是局部最低点,除非损失函数是凹凸函数。
详细的推导公式请参见https://www.zybuluo.com/hanbingtao/note/448086
这篇博客给我启发很多,关于深度学习的讲解与公式推导十分详细
7、过拟合与欠拟合
过拟合与欠拟合一般在参数设置不当发生,过拟合是对于预测过于严格对于噪声没有选择性的省略,欠拟合是指要求过于宽泛是算法不能正确的分类或预测。
就先总结这么多,都是个人的一些感悟,平时都是防止遗忘总结在私有云笔记上的,第一次在csdn上发博客写的有些蹑手蹑脚,欢迎各位大牛批评指正。

相关文章推荐
- 深度学习:几个重要的数学概念
- 深度学习算法的几个难点
- 深度学习中常见的几个基础概念
- 几个概念——关于人工智能、大数据、深度学习
- 深度学习入门系列博客(严重推荐)--如何训练 梯度消失 梯度爆炸等解释的明确
- NAND FLASH学习笔记之MTD下nand flash驱动(二)————几个重要文件和几个重要的结构体
- 深度学习 14. 深度学习调参,CNN参数调参,各个参数理解和说明以及调整的要领。underfitting和overfitting的理解,过拟合的解释。
- HTML其实就是学习几个重要标记的应用
- 《TensorFlow实战》作者黄文坚谈TensorFlow前的几个主要深度学习框架比较
- 深度学习的几个实际小应用!
- 学习Android前需要了解的几个重要概念
- 深度学习 4. MatConvNet 相关函数解释说明,MatConvNet 细节理解,MatConvNet 代码理解
- 学习自动收集表统计信息比较重要的几个数字字典
- 深度学习 5. MatConvNet 相关函数解释说明,MatConvNet 代码理解(一)cnn_mnist.m 的注释
- 【神经网络与深度学习】Caffe部署中的几个train-test-solver-prototxt-deploy等说明
- BW学习九(InfoCube相关的几个重要数字)
- 深度学习算法的几个难点
- HEVC学习(十) —— 与变换有关的几个主要函数及重要变量
- 学习重要的几个QWidget和QFrame子类
- 正则表达式入门经典(学习笔记八)——几个例子及解释汇总