Neural Networks(神经网络)
2017-10-20 17:13
141 查看
神经网络基本原理:

人类一向善于从大自然中寻找启发,并做出必要的改进来满足某种需要。而人类本身就有很多不可思议的事情,比如大脑。机器学习,学习学习,参考人类本身的学习就是对所见的事物一步一步的总结,一层一层的抽象,而大脑的神经-中枢-大脑的工作过程或许是一个不断迭代,不断抽象的过程,从原始的信号,做低级的抽象,逐渐向高级抽象迭代。
在感知机中,它采用了多个输入单元来抽象,但是学习能力非常有限,无法解决非线性可分的问题,虽然SVM延伸了核技术解决了这一点,但是实际上利用多层的感知机(Multi-layer Perception)也能完成,不过虽然是多层,其实是只有一层隐层节点的浅层模型。比如很多的分类,回归的学习方法都是浅层的算法,在于有限的样本和计算单元情况下对复杂的函数的表达能力有限,泛化能力不佳,计算量大。所以简单的多层网络的学习规则肯定是不够的,类比大脑产生更强大的算法是必要的。
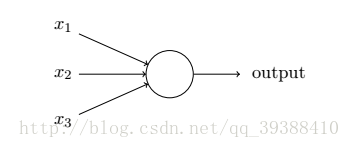
正如一个感知机一样,它有多个输入,不过这些输入可以取0~1的任何值而不是仅仅0,1。改进原先的激活函数为Sigmoid函数:σ(z)=11+e−z
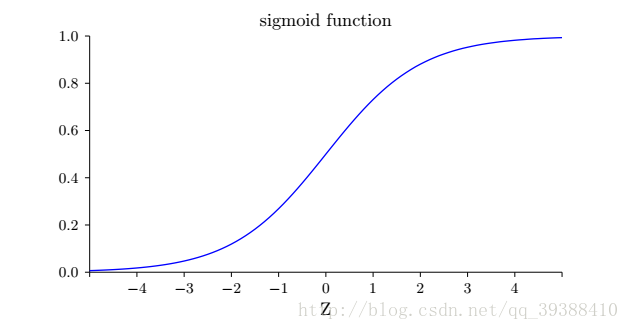
为什么用Sigmoid?其实使用不同的激活函数最大的变化只是求偏导时某些值的改变,事实证明这样做能够简化计算。

模拟生物神经网络,当神经元“兴奋”时就会向其相连的神经元发送某些化学物质去改变相连神经元的电位,而且如果电位超过某个阈值(threshold),神经元将就会被激活。事实上,不考虑它是否真的模拟了生物神经网络,只需将一个神经网络视为包含了许多参数的数学模型,由若干个函数相互嵌套即可。采用Sigmoid做激活函数(activation function),可以构建一个多层感知机,由许多逻辑单元按照不同层级组织起来,每一层的输出变量都是下一层的输入变量:
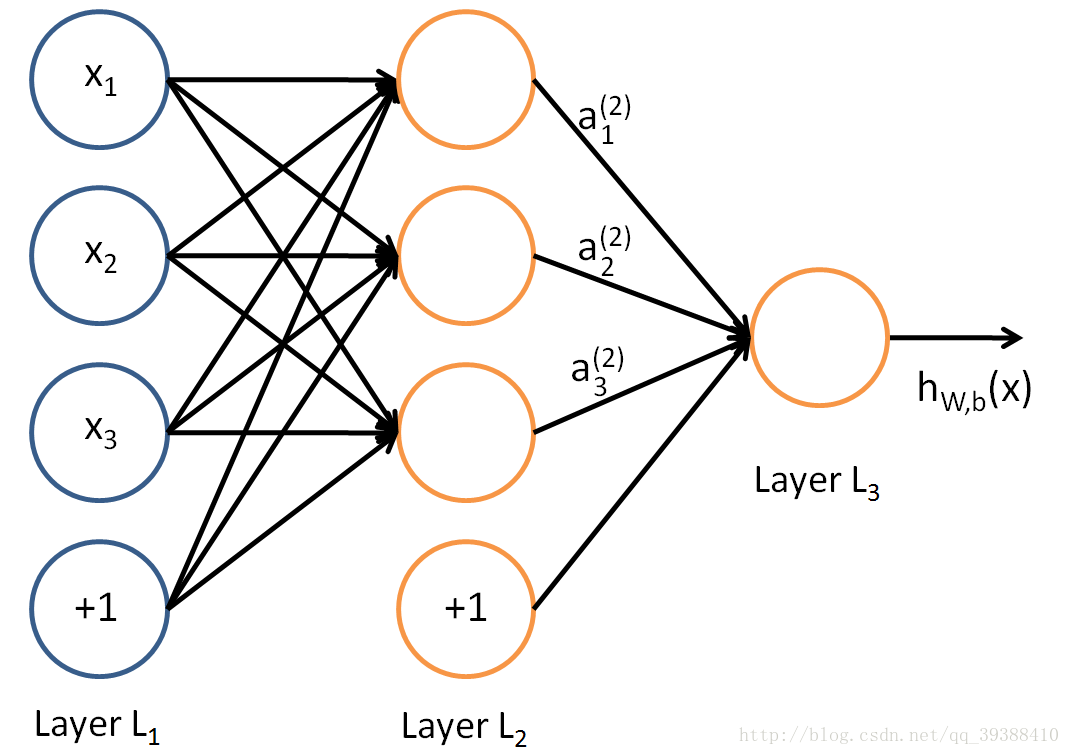
其中x1,x2,x3是输入单元(input units),将原始数据输入给它们。a1,a2,a3是中间单元,负责处理数据,然后呈递到下一层,最后是输出单元,它负责计算h(x)。然后与感知机类似,可以算出a(2)1=σ(w(1)11x1+w(1)12x2+w(1)13x3+b(1)1)
a(2)2=σ(w(1)21x1+w(1)22x2+w(1)23x3+b(1)2)
a(2)3=σ(w(1)31x1+w(1)32x2+w(1)33x3+b(1)3)
计算结果做下一次的输入,然后可得:
hW,b(x)=σ(w(2)11a(2)1+w(2)12a(2)2+w(2)13a(2)3+b(2)1)
机器学习老套路,此时需要一个损失函数来微调,常见的均方误差:J(W,b,x,y)=12||hW,b(x)−y||22
然后基于梯度下降策略,对参数们进行一层一层的误差逆传递(Error BackPropagation,BP)更新参数。
Wl=Wl−α∑i=1mδi,l(ai,l−1)T
bl=bl−α∑i=1mδi,l

简单来说就是参数的随机初始化,利用正向传播计算所有的h(x),计算代价函数j,利用反向传播计算所有的偏导,利用数值检验来检验偏导,最后使用优化算法(梯度下降等)来最小化代价函数。
收敛速度太慢?损失函数改进
采用交叉熵:
J(W,b,a,y)=−y∙lna−(1−y)∙ln(1−a)
第一,它非负;第二结果越接近,交叉熵接近0。这两点将使收敛速度变快。
分类问题如何解决?
Softmax激活函数:
aLi=ezLi∑j=1nLezLj
softmax函数能将输入值映射到(0,1),且所有输出值的累和为1,所以可以直接把它当概率,选取概率最大作最终结果。
继续加深神经网络效果怎么样?梯度问题
在BP算法中,使用了链式法则来求梯度,这样将会导致梯度问题。如果是一堆小于1的数字连乘,那么网络越深,连乘越多,慢慢的导致梯度消失,反过来如果是大于1的数据,将导致梯度爆炸。
修正线性单元(Rectified Linear Unit,ReLU)激活函数:
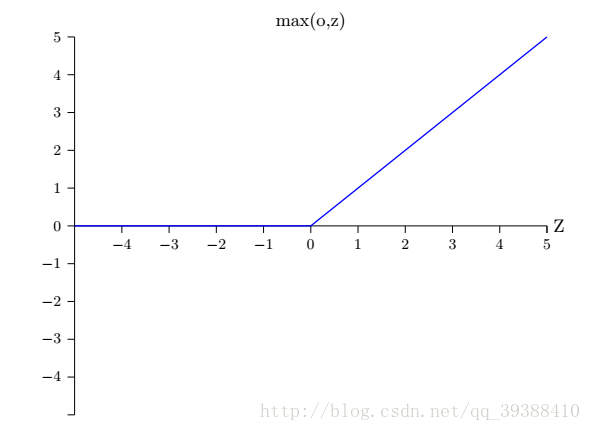
它在一定程度上能解决梯度消失,原因在于函数的右端的不会趋近于饱和,求导数时,导数不为零,从而梯度不消失,不过对于小于0的左边依然存在问题。
正则化问题
除了用L1,L2这种正则化外,神经网络可以通过dropout 来正则化,即在训练时随机去掉部分隐藏层的神经元。

随机dropout相当于训练了多个不同的神经网络,这样做能减轻过拟合,提升其泛化能力
如何选择超参数?。
比如梯度下降的步率,批量数据的规模,周期和正则化的系数等等。
解决方案:可视化,不断尝试与调整以得到最好的结果。
简单的NN应用:
主要参考:
Michael Nielsen 《Neural Networks and Deep Learning》
人类一向善于从大自然中寻找启发,并做出必要的改进来满足某种需要。而人类本身就有很多不可思议的事情,比如大脑。机器学习,学习学习,参考人类本身的学习就是对所见的事物一步一步的总结,一层一层的抽象,而大脑的神经-中枢-大脑的工作过程或许是一个不断迭代,不断抽象的过程,从原始的信号,做低级的抽象,逐渐向高级抽象迭代。
在感知机中,它采用了多个输入单元来抽象,但是学习能力非常有限,无法解决非线性可分的问题,虽然SVM延伸了核技术解决了这一点,但是实际上利用多层的感知机(Multi-layer Perception)也能完成,不过虽然是多层,其实是只有一层隐层节点的浅层模型。比如很多的分类,回归的学习方法都是浅层的算法,在于有限的样本和计算单元情况下对复杂的函数的表达能力有限,泛化能力不佳,计算量大。所以简单的多层网络的学习规则肯定是不够的,类比大脑产生更强大的算法是必要的。
正如一个感知机一样,它有多个输入,不过这些输入可以取0~1的任何值而不是仅仅0,1。改进原先的激活函数为Sigmoid函数:σ(z)=11+e−z
为什么用Sigmoid?其实使用不同的激活函数最大的变化只是求偏导时某些值的改变,事实证明这样做能够简化计算。
模拟生物神经网络,当神经元“兴奋”时就会向其相连的神经元发送某些化学物质去改变相连神经元的电位,而且如果电位超过某个阈值(threshold),神经元将就会被激活。事实上,不考虑它是否真的模拟了生物神经网络,只需将一个神经网络视为包含了许多参数的数学模型,由若干个函数相互嵌套即可。采用Sigmoid做激活函数(activation function),可以构建一个多层感知机,由许多逻辑单元按照不同层级组织起来,每一层的输出变量都是下一层的输入变量:
其中x1,x2,x3是输入单元(input units),将原始数据输入给它们。a1,a2,a3是中间单元,负责处理数据,然后呈递到下一层,最后是输出单元,它负责计算h(x)。然后与感知机类似,可以算出a(2)1=σ(w(1)11x1+w(1)12x2+w(1)13x3+b(1)1)
a(2)2=σ(w(1)21x1+w(1)22x2+w(1)23x3+b(1)2)
a(2)3=σ(w(1)31x1+w(1)32x2+w(1)33x3+b(1)3)
计算结果做下一次的输入,然后可得:
hW,b(x)=σ(w(2)11a(2)1+w(2)12a(2)2+w(2)13a(2)3+b(2)1)
机器学习老套路,此时需要一个损失函数来微调,常见的均方误差:J(W,b,x,y)=12||hW,b(x)−y||22
然后基于梯度下降策略,对参数们进行一层一层的误差逆传递(Error BackPropagation,BP)更新参数。
Wl=Wl−α∑i=1mδi,l(ai,l−1)T
bl=bl−α∑i=1mδi,l
简单来说就是参数的随机初始化,利用正向传播计算所有的h(x),计算代价函数j,利用反向传播计算所有的偏导,利用数值检验来检验偏导,最后使用优化算法(梯度下降等)来最小化代价函数。
import random
import numpy as np
class Network(object):
def __init__(self, sizes):#sizes包含各层神经元的数量
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]#随机初始化
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
def feedforward(self, a):
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):#梯度下降
if test_data: n_test = len(test_data)
n = len(training_data)
for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in xrange(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)#更新
if test_data:
print "Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test)
else:
print "Epoch {0} complete".format(j)
def update_mini_batch(self, mini_batch, eta):
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)#调用backprop
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
def backprop(self, x, y):
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x]
zs = []
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def evaluate(self, test_data):#判别正确的数量
test_results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
return (output_activations-y)
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):#导数
"""Derivative of the sigmoid function."""
return sigmoid(z)*(1-sigmoid(z))收敛速度太慢?损失函数改进
采用交叉熵:
J(W,b,a,y)=−y∙lna−(1−y)∙ln(1−a)
第一,它非负;第二结果越接近,交叉熵接近0。这两点将使收敛速度变快。
分类问题如何解决?
Softmax激活函数:
aLi=ezLi∑j=1nLezLj
softmax函数能将输入值映射到(0,1),且所有输出值的累和为1,所以可以直接把它当概率,选取概率最大作最终结果。
继续加深神经网络效果怎么样?梯度问题
在BP算法中,使用了链式法则来求梯度,这样将会导致梯度问题。如果是一堆小于1的数字连乘,那么网络越深,连乘越多,慢慢的导致梯度消失,反过来如果是大于1的数据,将导致梯度爆炸。
修正线性单元(Rectified Linear Unit,ReLU)激活函数:
它在一定程度上能解决梯度消失,原因在于函数的右端的不会趋近于饱和,求导数时,导数不为零,从而梯度不消失,不过对于小于0的左边依然存在问题。
正则化问题
除了用L1,L2这种正则化外,神经网络可以通过dropout 来正则化,即在训练时随机去掉部分隐藏层的神经元。
随机dropout相当于训练了多个不同的神经网络,这样做能减轻过拟合,提升其泛化能力
如何选择超参数?。
比如梯度下降的步率,批量数据的规模,周期和正则化的系数等等。
解决方案:可视化,不断尝试与调整以得到最好的结果。
简单的NN应用:
import tensorflow as tf
#导入input_data用于自动下载和安装MNIST数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder("float", [None, 784])
#权重值W和偏置值b
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
#使用softmax
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder("float", [None,10])
#计算交叉墒
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))
#梯度下降最小化交叉墒
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print (sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))主要参考:
Michael Nielsen 《Neural Networks and Deep Learning》

相关文章推荐
- Andrew Ng's deeplearning Course1Week3 Shallow neural networks(浅层神经网络)
- 机器学习之神经网络模型-上(Neural Networks: Representation)
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 机器学习之神经网络模型-上(Neural Networks: Representation)
- 机器学习教程之6-神经网络的学习(Neural Networks:Learning)
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 神经网络指南Hacker's guide to Neural Networks
- 神经网络第二部分:神经元Neural Networks, Part 2: The Neuron
- Stanford机器学习笔记-4. 神经网络Neural Networks (part one)
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 【deeplearning.ai】Neural Networks and Deep Learning——深层神经网络
- 机器学习之神经网络模型-下(Neural Networks: Representation)
- Neural Networks and Deep Learning 神经网络和深度学习
- 20170228#cs231n#5.Neural Networks Part 1神经网络1 /Assignment1-NeuralNetwork
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 机器学习之神经网络模型-上(Neural Networks: Representation)
- Torch 笔记:神经网络(Neural Networks)
- 神经网络的学习 Neural Networks learing
- 循环神经网络(RNN, Recurrent Neural Networks)介绍