java基础专栏—ArrayFrame(1)
2017-10-20 00:00
127 查看
摘要: 笔者在java学习的这条道路上也是断断续续走了一年多了,视频啊,数据啊什么的也看了好几遍了,真的是java从入门到放弃啊,哈哈,看的多了一渐渐的明白了一点东西,笔者整理了一些自己的学习笔记,在此与大家分享,不喜勿喷,多多指教,万分感谢。
集合是长度可变的
集合存储的是引用类型(自动装箱)
对对象的存储
打印一个对象都会调用toString()方法
遍历集合,取出对象
集合特性
选择容器的类型
public boolean add()
public boolean remove(Object object)
public boolean contains(Object object)
是否存在
public int size()
三种长度表现形式
数组.
字符串.length(),返回值
集合.
pulblic Object[] toArray()
集合中的元素转换成数组,应用于
public Iterator iterator()
public static boolean isEmpty()
Collection转型问题
public boolean hasNext()
public E next()
public void remove()
在接口中没有关于Iterator的方法体,实在实现了Collection的实现类中有public Iterator Iterator
面向接口编程:
接口(interface是一组规则,规定实现该接口的类的方法的规则)
之关心这个方法,但是具体的实现类在那个位置不关心
弊端: 没有
**例:**对集合使用迭代器方式进行获取,同时判断集合中是否存在某个对象,如果有,在添加一个对象。
在
<T> T[] toArray(T[] a)
防止在运行时期的转换异常
可以提前预知发生的错误
高级 for的使用
减少代码量
定义方法,同时遍历三个集合,同时可以代用方法
是
提供了大量的
public static void addFirst()
public static void addLast()
public static E removeFirst()
public static E removeLast()
从上面集合框架中可知,LinkedList是Collection的实现类,所有有Collection的方法,我们只关注他自己的特性方法
add(int index, E)
将元素插入到指定的索引上,注意
public static
Collection的重载,
public static
返回被修改的元素
先进后出:最先存入的元素,最后取出
栈的入口,出口都是栈的顶部
压栈:在入口处压入一个元素
弹栈:从入口处取出一个元素
队列
先进先出
队列的入口,出口各站一侧
数组
查找快,通过索引可以快速访问
增删慢,由于地址连续
链表
查找慢,通过连接的节点来查找
增删快
通过查询equals,来判断是否为重复元素
可以采用迭代器,高价for遍历
没有索引
这个接口的方法与
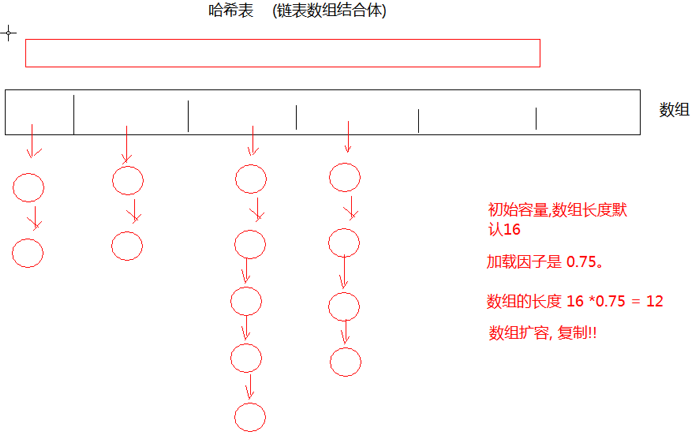
底层数据结构:哈希表(散列)--链表数组结合体
初始容量:默认16,加载因子:0.75
对象的
结果是
如果有相同hash值,就去调用对象的
出现相同的hash值,但是equals不相同,采用
参考
如果出现了相同的hash值,就会一直去调用equals方法,就会降低程序的效率
<u>怎样降低相同hash值出现的概率?</u>
不包含重复的key,但是可以value重复
是一个接口,其实现类是
Entry--关系映射对象实
ArrayFrame
ArrayList回顾
集合与数组的区别:集合是长度可变的
集合存储的是引用类型(自动装箱)
ArrayList<Integer> array = new ArrayList<Integer>(); array.add(123);
对对象的存储
打印一个对象都会调用toString()方法
集合目标
使用集合存储对象遍历集合,取出对象
集合特性
选择容器的类型
集合框架继承目录
|--`java.util` |-- `java.lang.Object` |-- `java.util.AbstractCollection<E>` |-- `java.util.AbstractList<E>` |-- `java.util.ArrayList<E>` |-- Iterable<E>,<u>Collection<E></u>,List<E>,RandomAccess |--Collection:root |--List:可重复,有序 |--ArrayList |--LinkedList |--Set:不可重复,无序 |--HashSet |--LinkedHasSet
Collection接口方法
public void clear()public boolean add()
public boolean remove(Object object)
public boolean contains(Object object)
是否存在
Collection<String> coll = new ArrayList<String>(); //接头多态
public int size()
三种长度表现形式
数组.
length返回值
int
字符串.length(),返回值
int
集合.
size,返回值
int
pulblic Object[] toArray()
集合中的元素转换成数组,应用于
IO流
public Iterator iterator()
public static boolean isEmpty()
Collection转型问题
Collection coll = new ArrayList() //在不用泛型指定存什么的情况下什么都可以往里面存 //既自动向上提型,但是只有强转之后才可调用对应的特性
Iterator
其前身是向量枚举
Iterator接口方法
iterator存在意义集合的存储方法不一样,存取的步骤方式都不一样,对于使用者来说不需要学习每一种集合的方法,Iterator来封装所有的容器的存取方法。
public boolean hasNext()
public E next()
public void remove()
在接口中没有关于Iterator的方法体,实在实现了Collection的实现类中有public Iterator Iterator
面向接口编程:
接口(interface是一组规则,规定实现该接口的类的方法的规则)
之关心这个方法,但是具体的实现类在那个位置不关心
Iterable接口——高级for循环
实现了Iterable的类都可以使用高级for循环
for(数据类型 变量名:数组或者集合){
}弊端: 没有
index不能对容器里面的内容做修改
Iterator并发修改异常
既在迭代器在工作的时候,集合发生了变化
**例:**对集合使用迭代器方式进行获取,同时判断集合中是否存在某个对象,如果有,在添加一个对象。
List<String> list = new ArrayList<String>();
list.add("ABC1");
list.add("ABC2");
list.add("ABC3");
list.add("ABC4");
Iterator it = list.Iterator();
while(it.hasNext()){
String s = it.next();
//String不是基础数据类型,他是引用类型
//ConcurrentModificationException
if(s.equals("ABC3")){
list.add("ABC5");
}
}泛型
定义: 明确集合的数据类型,避免安全隐患。
java中的泛型——伪泛型
java通过编译阶段来控制存储,不符合泛型的数据就不让存储在
.class中是没有泛型的
泛型类,接口,方法
ArrayList<E>,Iterator
<E>,带
<E>就是泛型类或者接口
<T> T[] toArray(T[] a)
public interface List<E>{
abstract boolean add(E e);
}
//实现接口一种是先实现接口,不管泛型
public class ArrayList<E> implements List<E>{
}
//好处是可以在创建对象的时候去实例是什么类型的
new ArrayList<String>();
//对于调用者可以自行创建类型
public class XXX<String> implements List<E>{
}泛型的优点
让运行时期的错误提前到了编译时期防止在运行时期的转换异常
可以提前预知发生的错误
高级 for的使用
减少代码量
泛型的通配符
?就是泛型的通配符
//实现一个方法来读取不同的集合的数据
ArrayList<String> array = new ArrayList<String>();
HashSet<Integer> set = new HashSet<Integer>();
//由于要实现不同的集合的遍历,将集合当做参数传进去
//要么填入他们共同的父类
//要么填入他们共同的接口
//由于不同的集合都有不同的泛型,所以以?来通配所有的泛型
public static void iterator(Collection<?> colle){
Iterator<?> it = coll.iterator();
while(it.hasNext()){
//由于类型不确定,所以不能强转
System.out.print(it.next());
}
}泛型实例讲解—泛型的限定
将酒店员工(Employee),厨师(cooker),服务员(waiter),经理(managaner)分别存储到三个集合当中去定义方法,同时遍历三个集合,同时可以代用方法
public class GenericTest{
public static void main(String[] args){
ArrayList<cooker> c = new ArrayList<cooker>();
ArrayList<Waiter> w = new ArrayList<Waiter>();
ArrayList<Managener> m = new ArrayList<Managener>();
c.add(new Cooker());
c.add(new Cooker());
w.add(new Waiter());
w.add(new Waiter());
m.add(new Managener());
m.add(new Managener());
}
//?通配符取出来的是Object对象,存在了强制类型转换(安全隐患)
//多态思想:强制类型转换转换成共同的父类或者共同父接口(employee)
//泛型的限定:<? extends Employee>
public static void iterator(ArrayList<? extends Employee> array){
Iterator<? extends Employee> it = array.iterator();
}
}<? extends XXX>父类限定,上限限定,可以传入子类
<? super XXX>下限限定,可以传入父类和本身
List
有序
可重复
有索引
ArrayList
List接口的
大小可变的**
数组**的实现,
不同步的
是
最常使用的集合
private transient Object[] elementDate;
private static final Object[] EMPTY_ELEMENTDATE = [];
public ArrayList(){
super();
this.elementDate = EMPTY_ELEMENTDATE;LinkedList
List接口的队列实现,
单向列,
不同步的(线程不安全)
提供了大量的
首尾操作
public static void addFirst()
public static void addLast()
public static E removeFirst()
public static E removeLast()
从上面集合框架中可知,LinkedList是Collection的实现类,所有有Collection的方法,我们只关注他自己的特性方法
既带有索引的方法要研究子类的
特有功能就不能使用
多态调用
add(int index, E)
将元素插入到指定的索引上,注意
数组越界IndexOutOfBoundException
public static
Eremove(int index)
Collection的重载,
public static boolean remove(Object obj)
E是泛型的知识,表示被删除的元素
public static
Eset(int index, E)
返回被修改的元素
LinkedList<String> link = new LinkedList<String>();
List数据结构
堆栈先进后出:最先存入的元素,最后取出
栈的入口,出口都是栈的顶部
压栈:在入口处压入一个元素
弹栈:从入口处取出一个元素
队列
先进先出
队列的入口,出口各站一侧
数组
查找快,通过索引可以快速访问
增删慢,由于地址连续
链表
查找慢,通过连接的节点来查找
增删快
Vector集合
Vector实现了可增长的数组,从java 1.2 之后改进实现了
List接口,成为<u>collection framwork</u>的一部分,但是他是
线程同步的,同时也导致了
速度慢。
Set
元素不可重复通过查询equals,来判断是否为重复元素
可以采用迭代器,高价for遍历
没有索引
这个接口的方法与
Collection中的方法一样
底层数据结构:哈希表(散列)--链表数组结合体
初始容量:默认16,加载因子:0.75
对象的
Hash值:一个普通的十进制数,来自Object的
public int hashCode()
public static void main(String[] args){
Person p = new Person();
int i = p.hashCode();
System.out.println(i);
}结果是
不可预知的,hash值是存储到HashSet中的依据。
hash的存储过程
调用对象的hash值,然后找有没有同样hash值的对象
如果有相同hash值,就去调用对象的
equals方法
出现相同的hash值,但是equals不相同,采用
桶的存储方式
存储自定义对象
对于自定义对象,需要根据不同的需求去重写hashCode()和equals()
参考
String类的hash算法:
public int hashCode(){
int h = hash;//default to 0
if(h == 0 && value.length > 0){
char val[] = value;
for(int i = 0; i < value.length; i++){
h = 31 * h + val[i];
}
hash = h;
}
return hash;
}如果出现了相同的hash值,就会一直去调用equals方法,就会降低程序的效率
<u>怎样降低相同hash值出现的概率?</u>
给数据乘一个数,当然这种方法只能是降低概率,并不能解决这个问题
HashSet
由哈希表支持(实质
HashMap)
public HashSet(){
map = new HashMap();
}LinkedHashSet extends HashSet
具有可预知的迭代顺序的set接口,维护着一个
运行于所有条目的双向链表,他也是
线程不安全的。但是也
不允许存储相同的元素
Map--双列集合
双列集合,在继承关系中,Map和Collection是没有关系的
不包含重复的key,但是可以value重复
是一个接口,其实现类是
HashMap,
LinkedHashMap,
HashTable线程安全
Entry--关系映射对象实

相关文章推荐
- java基础专栏—ArrayFrame(2)
- java基础专栏—JDBC
- java基础专栏—Thread
- java基础专栏—DBUtils(2)
- java基础专栏—Properties
- java基础专栏—DB(1)
- java基础专栏—Exception
- java基础专栏—IOUtils(4)
- java基础专栏—java网络编程
- java基础专栏—IO转换(3)
- java基础专栏—IOBuffer(2)
- java基础专栏—IO(1)
- java基础专栏—CommonApi
- 面试专栏:算法与数据结构,虚拟机,Java基础,JavaWeb
- java基础专栏—ThreadSafe
- java基础-序列化与反序列化
- Java并发(1)-基础概念
- java基础 六 自定义类,ArrayList集合
- java基础第21天
- JAVA基础--方法的重写overwrite 和 重载overload