24-最大间隔分类器——SVM
2017-10-15 20:16
429 查看
有时我想:人为什么会喜新厌旧?难道不知新的总会变成旧的。又想:人为什么忽略过程只求结果?难道不知一切结果也都是虚幻的。人能把握的只有现在、此刻正在经历的点点滴滴。所以走路时千万不要忘记看风景,有时良辰美景也只是惊鸿一瞥,如果一味向前冲,早晚会为自己的鲁莽而后悔。最好的不一定总在前面,回忆往事,最好的也许就是今天、此刻的限量版。所以不用为什么远大目的而奔忙,即刻享受当下吧。
今天学习另一种分类算法SVM(Support Vector Machine,支持向量机),它的目的是最大化分类间隔,间隔是指分离决策边界与离之最近的训练样本点之间的距离。
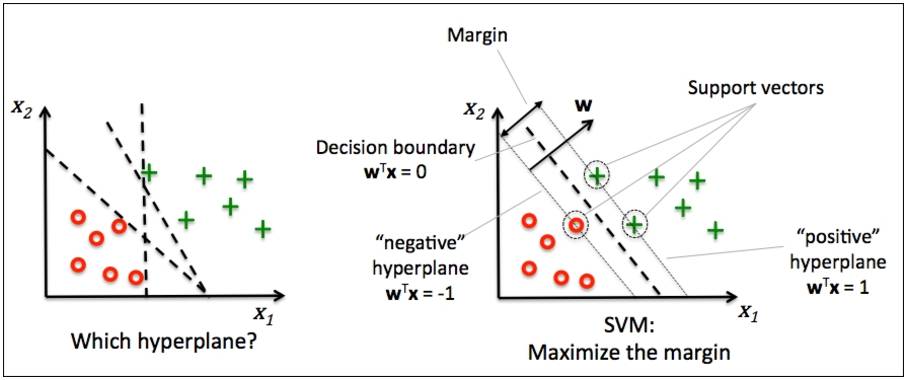
线性可分和线性分类器
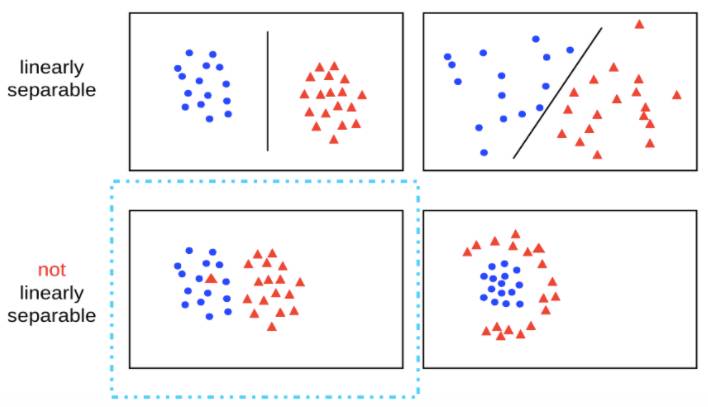
对于一个二分类问题,如果存在至少一个超平面能够将不同类别的样本分开,我们就说这些样本是线性可分的(linear separable)。所谓超平面,就是一个比原特征空间少一个维度的子空间,在二维情况下就是一条直线(注意不能是曲线),在三维情况下就是一个平面。
线性分类器(linear classifier)是一类通过将样本特征进行线性组合来作出分类决策的算法,它的目标就是找到一个如上所述能够分割不同类别样本的超平面。这样在预测的时候,我们就可以根据样本位于超平面的哪一边来作出决策。
用数学语言来描述,一个线性函数可以简单表示为:f(x)=wTx+b,而线性分类器则根据线性函数的结果进行分类决策:y=g(f(x))=g(wTx+b)
其中g(⋅)是一个将变量映射到不同类别的非线性函数,可以简单取为:
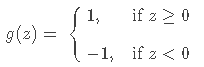
即分类的结果由 f(x) 的符号决定,f(x)=wTx+b=0即为分类超平面。
下图展示了几个线性可分/不可分的例子,并且画出了一个可能的分类超平面:
最大化间隔
在样本线性可分的情况下,可行的分类超平面可能会有很多,如下图的L1、L2和L3。
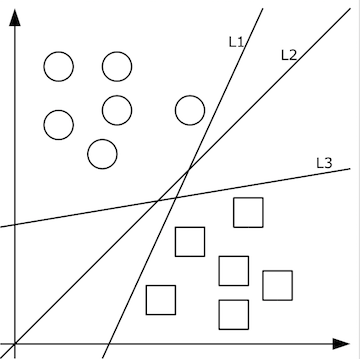
那么怎么选择一个最好的呢?从上图我们可以直观看出,L2比另外两条分界线要更好,这是因为L2离样本的距离更远一些,让人觉得确信度更高。这好比人(相当于样本)站在离悬崖边(分类边界)越远,人就会感到越安全(分类结果是安全还是危险)。从统计的角度讲,由于正负样本可以看作从两个不同的分布随机抽样而得,若分类边界与两个分布的距离越大,抽样出的样本落在分类边界另一边的概率就会越小。
SVM正是基于这种直观思路来确定最佳分类超平面的:通过选取能够最大化类间间隔的超平面,得到一个具有高确信度和泛化能力的分类器,即最大间隔分类器。
间隔
既然SVM的目标是最大化间隔,我们便要先对“间隔”进行定义。所谓间隔,就是分类超平面与所有样本距离的最小值,表示为:
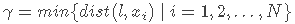
其中l表示分类超平面,N为样本个数,xi为第i个样本。接下来我们还需要定义样本到超平面的“距离” dist(l,x)。
假设任意一个样本点x0,其在分类超平面上的投影记作
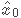
。对于分类超平面wTx+b=0,我们知道他的法向量是w,法向量方向的单位向量可以由法向量除以其模长所得:

。我们将dist(l,xi)记为d(d≥0),则可以得到:
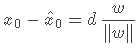
等式两边同时左乘wT并加上b,并且利用超平面上的点
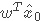
+b=0的性质,我们可以得到:
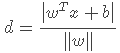
记y∈{−1,1}为分类标签,由于y(wTx+b)=∣wTx+b∣,我们可以以此消去上式的绝对值。
综上所述,我们可以得到对于分类超平面l和N个样本xi的“间隔”的表达式:
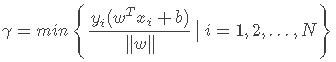
最大化
有了上述定义的间隔,接下来的事情就很直接了——求解能使间隔最大化的参数w和b,即求解以下优化函数:
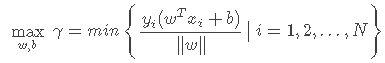
令
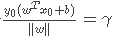
,上述优化函数也可以写成如下等价的形式:
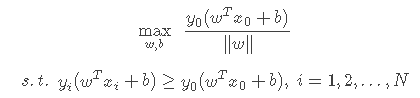
其中第二行的约束条件是为了满足对“间隔”的定义。下面我们来做一些数学上的小变换,使形式更为简洁。
我们定义
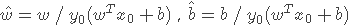
,则目标函数可写成:
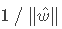
,约束条件可写成:
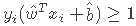
,i=1,2,...,N。再用w替换
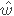
,b替换
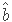
,并且利用
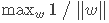
与
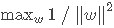
等价的原理,可以得到以下下等价的优化问题:
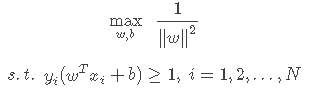
松弛变量
以上我们都只关心一个目的:寻找能够最大化间隔的分类超平面。然而,由于样本点中异常点的存在,只考虑这一个因素往往无法得到一个最佳的分类器。我们来看下图的例子:
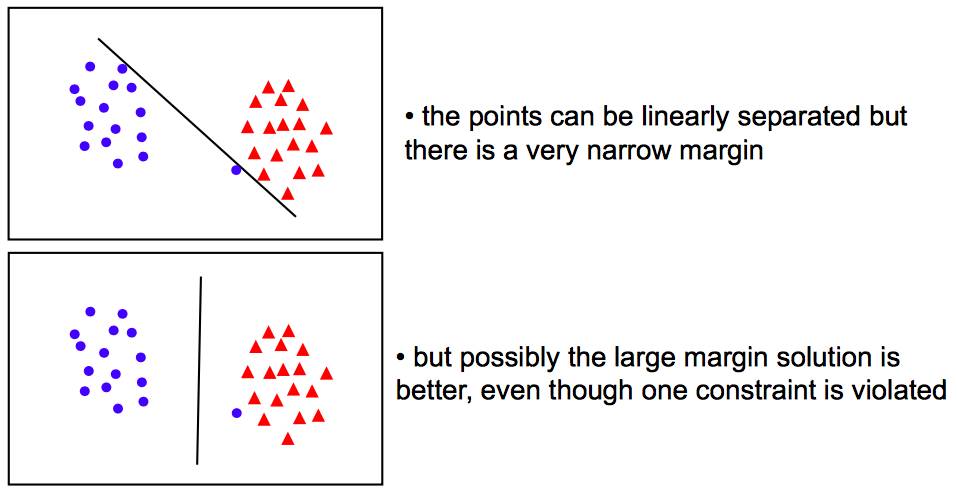
从上图可以看出:若我们严格遵守“间隔”的限制,由于蓝色异常点的存在,最终只能得到一个间隔很小的分类超平面。反之,如果我们能够放宽对于间隔的限制,便可以一定程度的忽略异常点的影响,反而能得到间隔更大的分类超平面。
上述容忍异常点的思路可以通过引入“松弛变量”(slack variable)实现。在原优化问题中,我们对“间隔”的限制表现在 yi(wTxi+b)≥1, i=1,2,...,N 当中。为了放宽对此的限制,我们对每个样本引入其对应的松弛变量 ζi (ζi≥0),则限制条件变为:yi(wTxi+b)≥1−ζi, i=1,2,...,N。
从上式可以看出,若样本点xi不是异常点(满足 yi(wTxi+b)≥1),则其松弛变量ζi=0,与原限制一样。若样本点xi是异常点,只要ζi足够大,限制条件便能满足,分类超平面(由w、b决定)不受影响。直观上讲,ζi等于将异常点“拉”回原间隔处所需要移动的距离,如下图所示:
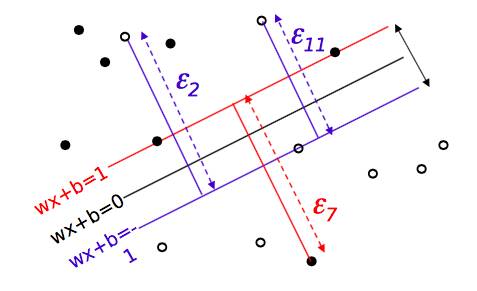
松弛变量的引入有助于增强模型对异常点的容忍能力,还能解决一定的数据线性不可分的问题。然而,如果不对松弛变量进行限制,得到的分类器又会变得没有用处(大量的错误分类)。因此,我们需要同时对两个目标进行优化:最大化间隔和容忍异常样本,并且引入一个平衡参数 C (C≥0)来衡量这两个方面的重要程度。引入松弛变量后的完整优化问题如下:
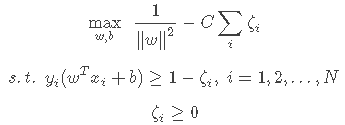
最后,我们再来分析一下平衡参数 C 对求得分类超平面的影响。
C 取无穷:ζi只能为零,代表无法容忍任何误判样本的出现,即严格遵守“间隔”的限制,得到没有引入松弛变量时的分类超平面
C取零:ζi可以任意大,即任何误判结果都可以被容忍,得到分类超平面没有意义
C较大:ζi不能很大,因此限制条件难以被忽略,会得到较为狭窄间隔的分类超平面
C较小:ζi影响较小,因此限制条件可以被忽略,会得到较为宽间隔的分类超平面
下周学习如何在scikit-learn中使用SVM分类器,敬请期待:)
今天学习另一种分类算法SVM(Support Vector Machine,支持向量机),它的目的是最大化分类间隔,间隔是指分离决策边界与离之最近的训练样本点之间的距离。
线性可分和线性分类器
对于一个二分类问题,如果存在至少一个超平面能够将不同类别的样本分开,我们就说这些样本是线性可分的(linear separable)。所谓超平面,就是一个比原特征空间少一个维度的子空间,在二维情况下就是一条直线(注意不能是曲线),在三维情况下就是一个平面。
线性分类器(linear classifier)是一类通过将样本特征进行线性组合来作出分类决策的算法,它的目标就是找到一个如上所述能够分割不同类别样本的超平面。这样在预测的时候,我们就可以根据样本位于超平面的哪一边来作出决策。
用数学语言来描述,一个线性函数可以简单表示为:f(x)=wTx+b,而线性分类器则根据线性函数的结果进行分类决策:y=g(f(x))=g(wTx+b)
其中g(⋅)是一个将变量映射到不同类别的非线性函数,可以简单取为:
即分类的结果由 f(x) 的符号决定,f(x)=wTx+b=0即为分类超平面。
下图展示了几个线性可分/不可分的例子,并且画出了一个可能的分类超平面:
最大化间隔
在样本线性可分的情况下,可行的分类超平面可能会有很多,如下图的L1、L2和L3。
那么怎么选择一个最好的呢?从上图我们可以直观看出,L2比另外两条分界线要更好,这是因为L2离样本的距离更远一些,让人觉得确信度更高。这好比人(相当于样本)站在离悬崖边(分类边界)越远,人就会感到越安全(分类结果是安全还是危险)。从统计的角度讲,由于正负样本可以看作从两个不同的分布随机抽样而得,若分类边界与两个分布的距离越大,抽样出的样本落在分类边界另一边的概率就会越小。
SVM正是基于这种直观思路来确定最佳分类超平面的:通过选取能够最大化类间间隔的超平面,得到一个具有高确信度和泛化能力的分类器,即最大间隔分类器。
间隔
既然SVM的目标是最大化间隔,我们便要先对“间隔”进行定义。所谓间隔,就是分类超平面与所有样本距离的最小值,表示为:
其中l表示分类超平面,N为样本个数,xi为第i个样本。接下来我们还需要定义样本到超平面的“距离” dist(l,x)。
假设任意一个样本点x0,其在分类超平面上的投影记作
。对于分类超平面wTx+b=0,我们知道他的法向量是w,法向量方向的单位向量可以由法向量除以其模长所得:
。我们将dist(l,xi)记为d(d≥0),则可以得到:
等式两边同时左乘wT并加上b,并且利用超平面上的点
+b=0的性质,我们可以得到:
记y∈{−1,1}为分类标签,由于y(wTx+b)=∣wTx+b∣,我们可以以此消去上式的绝对值。
综上所述,我们可以得到对于分类超平面l和N个样本xi的“间隔”的表达式:
最大化
有了上述定义的间隔,接下来的事情就很直接了——求解能使间隔最大化的参数w和b,即求解以下优化函数:
令
,上述优化函数也可以写成如下等价的形式:
其中第二行的约束条件是为了满足对“间隔”的定义。下面我们来做一些数学上的小变换,使形式更为简洁。
我们定义
,则目标函数可写成:
,约束条件可写成:
,i=1,2,...,N。再用w替换
,b替换
,并且利用
与
等价的原理,可以得到以下下等价的优化问题:
松弛变量
以上我们都只关心一个目的:寻找能够最大化间隔的分类超平面。然而,由于样本点中异常点的存在,只考虑这一个因素往往无法得到一个最佳的分类器。我们来看下图的例子:
从上图可以看出:若我们严格遵守“间隔”的限制,由于蓝色异常点的存在,最终只能得到一个间隔很小的分类超平面。反之,如果我们能够放宽对于间隔的限制,便可以一定程度的忽略异常点的影响,反而能得到间隔更大的分类超平面。
上述容忍异常点的思路可以通过引入“松弛变量”(slack variable)实现。在原优化问题中,我们对“间隔”的限制表现在 yi(wTxi+b)≥1, i=1,2,...,N 当中。为了放宽对此的限制,我们对每个样本引入其对应的松弛变量 ζi (ζi≥0),则限制条件变为:yi(wTxi+b)≥1−ζi, i=1,2,...,N。
从上式可以看出,若样本点xi不是异常点(满足 yi(wTxi+b)≥1),则其松弛变量ζi=0,与原限制一样。若样本点xi是异常点,只要ζi足够大,限制条件便能满足,分类超平面(由w、b决定)不受影响。直观上讲,ζi等于将异常点“拉”回原间隔处所需要移动的距离,如下图所示:
松弛变量的引入有助于增强模型对异常点的容忍能力,还能解决一定的数据线性不可分的问题。然而,如果不对松弛变量进行限制,得到的分类器又会变得没有用处(大量的错误分类)。因此,我们需要同时对两个目标进行优化:最大化间隔和容忍异常样本,并且引入一个平衡参数 C (C≥0)来衡量这两个方面的重要程度。引入松弛变量后的完整优化问题如下:
最后,我们再来分析一下平衡参数 C 对求得分类超平面的影响。
C 取无穷:ζi只能为零,代表无法容忍任何误判样本的出现,即严格遵守“间隔”的限制,得到没有引入松弛变量时的分类超平面
C取零:ζi可以任意大,即任何误判结果都可以被容忍,得到分类超平面没有意义
C较大:ζi不能很大,因此限制条件难以被忽略,会得到较为狭窄间隔的分类超平面
C较小:ζi影响较小,因此限制条件可以被忽略,会得到较为宽间隔的分类超平面
下周学习如何在scikit-learn中使用SVM分类器,敬请期待:)

相关文章推荐
- 最大间隔多超平面分类器(多线性SVM分类器)介绍及Matlab实现
- 三个角度看SVM(1)——最大间隔分类器
- SVM 最大间隔目标优化函数(NG课件2)
- 支持向量机(SVM)(三)-- 最优间隔分类器(optimal margin classifier)
- 机器学习笔记八 - SVM(Support Vector Machine,支持向量机)的剩余部分。即核技法、软间隔分类器、对SVM求解的序列最小化算法以及SVM的一些应用
- Andrew Ng - SVM【1】最优间隔分类器
- 【机器学习-西瓜书】六、支持向量机(SVM):最大间隔;对偶问题;KKT条件
- 支持向量机(SVM)(三)-- 最优间隔分类器(optimal margin classifier)
- 学习理论之感知器与最大间隔分类器
- 最优间隔分类器与SVM
- 学习SVM(二) 如何理解支持向量机的最大分类间隔
- 支持向量机(SVM)关键点攻略(最大间隔,对偶问题)
- 砥志研思SVM(一) 最优间隔分类器问题(上):硬间隔SVM
- [置顶] 最优间隔分类器、原始/对偶问题、SVM的对偶问题——斯坦福ML公开课笔记7
- 最优间隔分类器.原始/对偶优化问题.KKT.SVM对偶
- 砥志研思SVM(三) 最优间隔分类器问题(下):软间隔SVM
- 最优间隔分类器-SVM
- 支持向量机系列之最大间隔分类器
- 机器学习笔记七 - 最优间隔分类器、原始/对偶问题、svm的对偶问题
- 支持向量机SVM(一):支持向量机SVM的推倒:从logistic回归,到函数间隔,集合间隔,到寻找最优间隔分类器。