Hierarchical Clustering(层次聚类)
2017-10-15 13:27
274 查看
层次聚类原理:
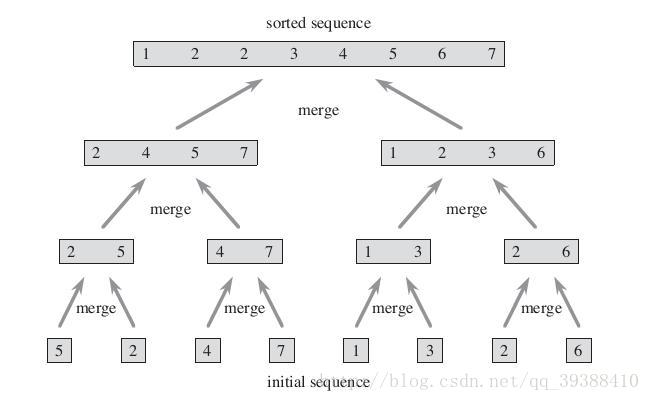
唔?排序的图?分治?没错,与原型聚类和密度聚类不同,层次聚类试图在不同的“层次”上对样本数据集进行划分,一层一层地进行聚类。就划分策略可分为自底向上的凝聚方法(agglomerative hierarchical clustering),比如AGNES。自上向下的分裂方法(divisive hierarchical clustering),比如DIANA。
AGNES先将所有样本的每个点都看成一个簇,然后找出距离最小的两个簇进行合并,不断重复到预期簇或者其他终止条件。
DIANA先将所有样本当作一整个簇,然后找出簇中距离最远的两个簇进行分裂,不断重复到预期簇或者其他终止条件。
如何判断两个cluster之间的距离呢?
1.最小距离,单链接Single Linkage
两个簇的最近样本决定。
2.最大距离,全链接Complete Linkage
两个簇的最远样本决定。
3.平均距离,均链接Average Linkage
两个簇所有样本共同决定。
1和2都容易受极端值的影响,而3这种方法计算量比较大,不过这种度量方法更合理。
和决策树相似,层次聚类的优点在于能一次性得到整棵树,同控制某些条件不管是深度还是宽度都是可控的,但是它存在不少的问题:
计算量
划分确定不可再作更改
凝聚和划分相互组合!!
每次选择“最优”
贪心算法,容易局部最优化,可以通过适当的随机操作。
或者是采用平衡迭代规约和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies,BIRCH)它首先把邻近样本点划分到微簇(microcluseters)中,然后对这些微簇使用K-means算法。
HC应用:
AgglomerativeClustering参数说明:
AgglomerativeClustering(affinity=’euclidean’, compute_full_tree=’auto’,connectivity=None, linkage=’ward’,memory=Memory(cachedir=None), n_clusters=6,pooling_func=)
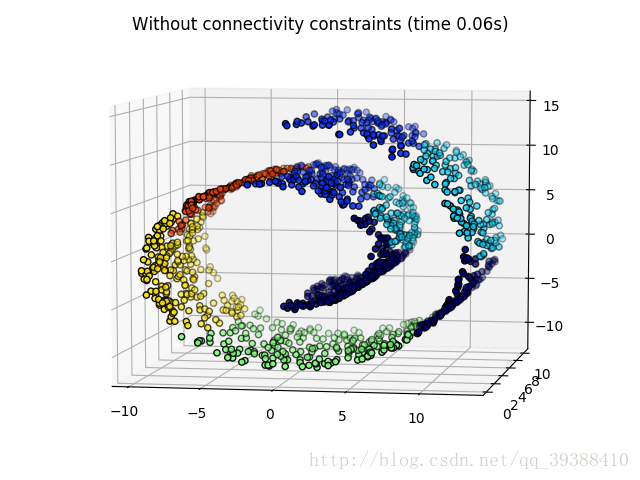
可见没有连接性约束的忽视其数据本身的结构,于是形成了跨越流形的不同褶皱。
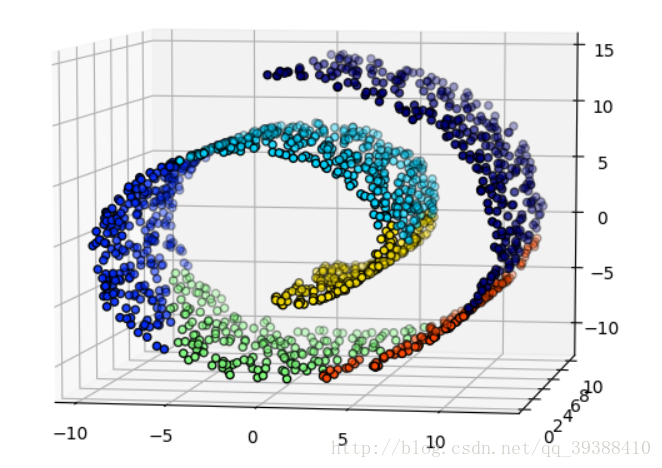
修改部分代码后,添加connectivity便可以得到很好的结果。
唔?排序的图?分治?没错,与原型聚类和密度聚类不同,层次聚类试图在不同的“层次”上对样本数据集进行划分,一层一层地进行聚类。就划分策略可分为自底向上的凝聚方法(agglomerative hierarchical clustering),比如AGNES。自上向下的分裂方法(divisive hierarchical clustering),比如DIANA。
AGNES先将所有样本的每个点都看成一个簇,然后找出距离最小的两个簇进行合并,不断重复到预期簇或者其他终止条件。
DIANA先将所有样本当作一整个簇,然后找出簇中距离最远的两个簇进行分裂,不断重复到预期簇或者其他终止条件。
如何判断两个cluster之间的距离呢?
1.最小距离,单链接Single Linkage
两个簇的最近样本决定。
2.最大距离,全链接Complete Linkage
两个簇的最远样本决定。
3.平均距离,均链接Average Linkage
两个簇所有样本共同决定。
1和2都容易受极端值的影响,而3这种方法计算量比较大,不过这种度量方法更合理。
和决策树相似,层次聚类的优点在于能一次性得到整棵树,同控制某些条件不管是深度还是宽度都是可控的,但是它存在不少的问题:
计算量
划分确定不可再作更改
凝聚和划分相互组合!!
每次选择“最优”
贪心算法,容易局部最优化,可以通过适当的随机操作。
或者是采用平衡迭代规约和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies,BIRCH)它首先把邻近样本点划分到微簇(microcluseters)中,然后对这些微簇使用K-means算法。
HC应用:
AgglomerativeClustering参数说明:
AgglomerativeClustering(affinity=’euclidean’, compute_full_tree=’auto’,connectivity=None, linkage=’ward’,memory=Memory(cachedir=None), n_clusters=6,pooling_func=)
affinity='euclidean':距离度量方式 connectivity:是否有连通性约束 linkage='ward':链接方式 memory:存储方式 n_clusters=6:簇类数
import numpy as np import matplotlib.pyplot as plt import mpl_toolkits.mplot3d.axes3d as p3 from sklearn.cluster import AgglomerativeClustering from sklearn.datasets.samples_generator import make_swiss_roll n_samples = 1500 noise = 0.05 X, _ = make_swiss_roll(n_samples, noise)#卷型数据集 #进行放缩 X[:, 1] *= .5 ward = AgglomerativeClustering(n_clusters=6, linkage='ward').fit(X) label = ward.labels_#得到lable值 fig = plt.figure() ax = p3.Axes3D(fig) ax.view_init(7, -80) for l in np.unique(label): ax.scatter(X[label == l, 0], X[label == l, 1], X[label == l, 2], color=plt.cm.jet(np.float(l) / np.max(label + 1)), s=20, edgecolor='k') plt.show()
可见没有连接性约束的忽视其数据本身的结构,于是形成了跨越流形的不同褶皱。
from sklearn.neighbors import kneighbors_graph connectivity = kneighbors_graph(X, n_neighbors=10, include_self=False) ward = AgglomerativeClustering(n_clusters=6, connectivity=connectivity, linkage='ward').fit(X)
修改部分代码后,添加connectivity便可以得到很好的结果。

相关文章推荐
- 基于层次的聚类----AGNES算法使用(R语言)
- 机器学习(6): 层次聚类 hierarchical clustering
- 层次聚类简介
- 使用Python进行层次聚类/主成分分析绘图观察结果/绘制热图
- 层次聚类之AGNES及Python实现
- 层次聚类
- 聚类-birch(层次方法的平衡迭代规约和聚类)
- python实现层次聚类
- 层次聚类(1)
- R语言 : 层次聚类分析
- 聚类算法之层次聚类与密度聚类
- 层次聚类 Hierarchical Clustering
- MATLAB的层次聚类及k-均值聚类应用简述zz
- python中做层次聚类,使用scipy.cluster.hierarchy.fclusterdata方法
- 系统聚类(层次聚类)
- 层次聚类(1)
- 层次聚类
- 层次聚类和固定宽度聚类
- 机器学习算法复习--层次聚类
- 层次凝聚聚类法