Hadoop和Spark学习日记3
2017-10-14 22:27
274 查看
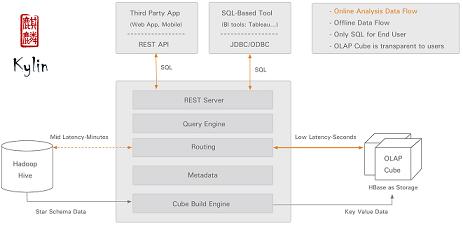
1. Apache Kylin概览
解析:Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的Hive表。
2. QPS
解析:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
3. Load Balancer(负载均衡器)
解析:LVS(Linux Virtual Server);Nginx等。
4. Oozie
解析:Oozie是管理Hadoop作业的工作流调度系统。
5. Snappy
解析:Snappy是一个C++的用来压缩和解压缩的开发包。其目标不是最大限度压缩或者兼容其他压缩格式,而是旨在提供高速压缩速度和合理的压缩率。
6. HDFS Federation
解析:HDFS Federation是Hadoop为解决HDFS单点故障而提出的NameNode水平扩展方案。该方案允许HDFS创建多个NameSpace以提高集群的扩展性和隔离性。
7. InfiniBand
解析:InfiniBand架构是一种支持多并发链接的“转换线缆”技术,在这种技术中,每种链接都可以达到2.5Gbps的运行速度。这种架构在一个链接的时候速度是500MB/秒,四个链接的时候速度是2GB/秒,12个链接的时候速度可以达到6GB/秒。
8. Slider
解析:将已存在的应用程序或者服务部署到YARN上。比如,HBase On YARN,Storm On YARN和Accumulo On YARN等。
9. Apache Accumulo
解析:Apache Accumulo是一个可靠的、可伸缩的、高性能的排序分布式的Key-Value存储解决方案,基于单元访问控制以及可定制的服务器端处理。使用Google BigTable设计思路,基于Apache Hadoop、Zookeeper和Thrift构建。
10. Thrift
解析:Thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引擎,以构建在C++,Java,Go,Python,PHP,Ruby,Erlang,Perl,Haskell,C#,Cocoa,JavaScript,
Node.js,Smalltalk,and OCaml这些编程语言间无缝结合的、高效的服务。
11. StreamDM
解析:用于Spark Streaming的数据挖掘软件。Spark Streaming数据被编成一个DStreams序列,内在地表示成一个RDD序列。
12. ETL工具
解析:Apache Camel;Apache Kafka;Apatar;Heka;Logstash;Scriptella;Talend;Kettle。
13. DataX
解析:DataX是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、
Hive、MaxCompute(原ODPS)、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
14. Lambda架构
解析:Lambda架构可分解为三层Layer,即Batch Layer,Real-Time (Speed) Layer和Serving Layer。
(1)Batch Layer:存储数据集,在数据集上预先计算查询函数,并构建查询所对应的View。Batch Layer可以很好的处理离线数据,但有很多场景数据是不断实时生成且需要实时查询处理,对于这情况,Speed Layer更为适合。
(2)Speed Layer:Batch Layer处理的是全体数据集,而Speed Layer处理的是最近的增量数据流。Speed Layer为了效率,在接收到新数据后会不断更新Real-time View,而Batch Layer根据全体离线数据集直接得到Batch View。
(3)Serving Layer : Serving Layer用于合并Batch View和Real-time View中的结果数据集到最终数据集。
15. Kappa架构
解析:比Lambda更好更灵活的实时处理架构。
16. ZooKeeper中的zoo_sample.cfg
解析:
(1)tickTime:Zookeeper服务器间或客户端与服务器间维持心跳时间间隔,即每隔tickTime时间会发送一个心跳。
(2)dataDir:Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
(3)dataLogDir:Zookeeper保存日志文件的目录
(4)clientPort:客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求。
17. 布隆过滤器,跳表,LSM树
解析:
(1)布隆过滤器是判断海量数据集合中某条数据是否存在的利器,尤其是空间利用率相当高,能够用小内存处理大数据。
(2)跳表用于高效维护序列数据,使用场景也非常多,比如LevelDB维护内存数据时用的就是SkipList,再比如Redis的Sorted Set以及Lucene维护倒排索引都是用的它。
(3)LSM树是很多NoSQL系统的核心构件,比如BigTable、Cassandra、RAMCloud等。
参考文献:
[1] Apache Kylin:http://kylin.apache.org/cn/
解析:Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的Hive表。
2. QPS
解析:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
3. Load Balancer(负载均衡器)
解析:LVS(Linux Virtual Server);Nginx等。
4. Oozie
解析:Oozie是管理Hadoop作业的工作流调度系统。
5. Snappy
解析:Snappy是一个C++的用来压缩和解压缩的开发包。其目标不是最大限度压缩或者兼容其他压缩格式,而是旨在提供高速压缩速度和合理的压缩率。
6. HDFS Federation
解析:HDFS Federation是Hadoop为解决HDFS单点故障而提出的NameNode水平扩展方案。该方案允许HDFS创建多个NameSpace以提高集群的扩展性和隔离性。
7. InfiniBand
解析:InfiniBand架构是一种支持多并发链接的“转换线缆”技术,在这种技术中,每种链接都可以达到2.5Gbps的运行速度。这种架构在一个链接的时候速度是500MB/秒,四个链接的时候速度是2GB/秒,12个链接的时候速度可以达到6GB/秒。
8. Slider
解析:将已存在的应用程序或者服务部署到YARN上。比如,HBase On YARN,Storm On YARN和Accumulo On YARN等。
9. Apache Accumulo
解析:Apache Accumulo是一个可靠的、可伸缩的、高性能的排序分布式的Key-Value存储解决方案,基于单元访问控制以及可定制的服务器端处理。使用Google BigTable设计思路,基于Apache Hadoop、Zookeeper和Thrift构建。
10. Thrift
解析:Thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引擎,以构建在C++,Java,Go,Python,PHP,Ruby,Erlang,Perl,Haskell,C#,Cocoa,JavaScript,
Node.js,Smalltalk,and OCaml这些编程语言间无缝结合的、高效的服务。
11. StreamDM
解析:用于Spark Streaming的数据挖掘软件。Spark Streaming数据被编成一个DStreams序列,内在地表示成一个RDD序列。
12. ETL工具
解析:Apache Camel;Apache Kafka;Apatar;Heka;Logstash;Scriptella;Talend;Kettle。
13. DataX
解析:DataX是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、
Hive、MaxCompute(原ODPS)、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
14. Lambda架构
解析:Lambda架构可分解为三层Layer,即Batch Layer,Real-Time (Speed) Layer和Serving Layer。
(1)Batch Layer:存储数据集,在数据集上预先计算查询函数,并构建查询所对应的View。Batch Layer可以很好的处理离线数据,但有很多场景数据是不断实时生成且需要实时查询处理,对于这情况,Speed Layer更为适合。
(2)Speed Layer:Batch Layer处理的是全体数据集,而Speed Layer处理的是最近的增量数据流。Speed Layer为了效率,在接收到新数据后会不断更新Real-time View,而Batch Layer根据全体离线数据集直接得到Batch View。
(3)Serving Layer : Serving Layer用于合并Batch View和Real-time View中的结果数据集到最终数据集。
15. Kappa架构
解析:比Lambda更好更灵活的实时处理架构。
16. ZooKeeper中的zoo_sample.cfg
解析:
(1)tickTime:Zookeeper服务器间或客户端与服务器间维持心跳时间间隔,即每隔tickTime时间会发送一个心跳。
(2)dataDir:Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
(3)dataLogDir:Zookeeper保存日志文件的目录
(4)clientPort:客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求。
17. 布隆过滤器,跳表,LSM树
解析:
(1)布隆过滤器是判断海量数据集合中某条数据是否存在的利器,尤其是空间利用率相当高,能够用小内存处理大数据。
(2)跳表用于高效维护序列数据,使用场景也非常多,比如LevelDB维护内存数据时用的就是SkipList,再比如Redis的Sorted Set以及Lucene维护倒排索引都是用的它。
(3)LSM树是很多NoSQL系统的核心构件,比如BigTable、Cassandra、RAMCloud等。
参考文献:
[1] Apache Kylin:http://kylin.apache.org/cn/

相关文章推荐
- Hadoop和Spark学习日记2
- Hadoop和Spark学习日记1
- Spark、Hadoop、Hive安装学习
- hadoop学习笔记4:hadoop、spark概念
- hadoop、spark学习中常用的linux命令
- Apache Spark学习:将Spark部署到Hadoop 2.2.0上
- 大数据Hadoop与Spark学习经验谈
- 导入文章“Apache Spark学习:将Spark部署到Hadoop 2.2.0上”中给出的 assembly/target/scala-2.9.3/目录下的spark-assembly-0.8.
- hadoop 入门学习系列之八-----spark安装
- 阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 spark
- Hadoop日记Day17---计数器、map规约、分区学习
- Hadoop概念学习系列之Hadoop、Spark学习路线(很值得推荐)(十八)
- 雅虎开源CaffeOnSpark:基于Hadoop/Spark的分布式深度学习
- ubuntu16.04搭建Hadoop2.7.2+spark1.6.1+mysql+hive2.0.0伪分布学习环境
- 雅虎开源CaffeOnSpark:基于Hadoop/Spark的分布式深度学习
- spark学习1(hadoop集群搭建)
- 雅虎开源CaffeOnSpark:基于Hadoop/Spark的分布式深度学习
- Hadoop概念学习系列之Hadoop、Spark学习路线
- spark学习1——配置hadoop 单机模式并运行WordCount实例(ubuntu14.04 & hadoop 2.6.0)
- Hadoop概念学习系列之Hadoop、Spark学习路线(很值得推荐)