Java集合和泛型
2017-10-14 00:00
381 查看
集合
定义:Java中的集合类:是一种工具类,就像是容器,存储任意数量的具有共同属性的对象。注意:对象!对象!是对象!基本数据类型需要转换为对象类型。
一、集合框架图
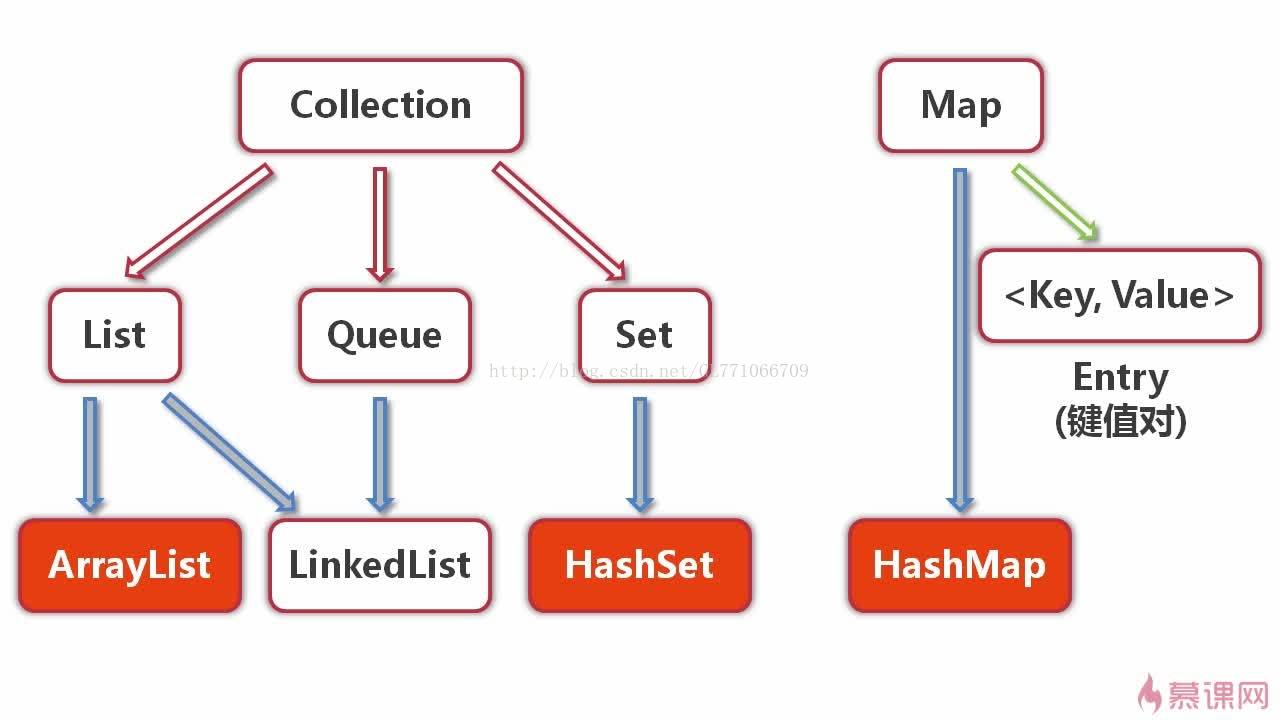
看上面的框架图,先抓住它的主干,即Collection和Map。
1、Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作和属性。Collection包含了List和Set两大分支。
(1)List是一个有序的队列,每一个元素都有它的索引。第一个元素的索引值是0。
(2)Set是一个不允许有重复元素的集合。
2、Map是一个映射接口,即key-value键值对。Map中的每一个元素包含“一个key”和“key对应的value”。
有了上面的整体框架之后,我们接下来对每个类分别进行分析。
二、Collection接口
Collection接口是处理对象集合的根接口,其中定义了很多对元素进行操作的方法。Collection接口有两个主要的子接口List和Set,注意Map不是Collection的子接口,这个要牢记。1 Collection接口常用的方法
(1)容器类中单个元素的添加,删除的方法boolean add(object o) //将对象添加给集合 boolean remove(object o) //删除对象o
(2) 容器类中元素查询的方法
int size() //返回当前集合中元素的数量 boolean empty() //查找集合中是否包含元素 boolean contain(object o) //查找集合中是否包含指定的元素 boolean contain(Collection c) //查找集合中是否包含c中的所有元素 Iterator iterator() //返回一个该集合上的迭代器,用来访问该集合中的各个元素 boolean containAll(Collection c) //查找集合中是否含有c中的所有元素
(3) 组操作,作用于元素组或整个集合
boolean addAll(Collection c) //将指定集合c中的所有元素加给该集合 void clear() //删除该集合中所有元素 void removeAll(Collection c) //从集合中删除集合c中所有的元素 void retainAll(Collection c) //从集合中删除指定集合c中不包含的元素
(4) 转换操作,用于集合与数组间的转换
object[] toarray() //将此Collection转换为对象数组 object[] toarray(object[] a) //返回一个内含该集合所有元素的array
(5) Iterator接口中的方法
boolean hasNext() //判断游标右端是否有元素 object next() //返回游标右边的元素,并将游标向右移动一位、 void remove() //删除游标左边的元素
2 List接口
List集合代表一个有序集合,集合中每个元素都有其对应的顺序索引。List集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。(1)ArrayList
ArrayList是一个动态数组,也是我们最常用的集合。它允许任何符合规则的元素插入甚至包括null。每一个ArrayList都有一个初始容量(10),该容量代表了数组的大小。随着容器中的元素不断增加,容器的大小也会随着增加。在每次向容器中增加元素的同时都会进行容量检查,当快溢出时,就会进行扩容操作。所以如果我们明确所插入元素的多少,最好指定一个初始容量值,避免过多的进行扩容操作而浪费时间、效率。
ArrayList 类对于使用索引取出元素有较高的效率,它可以使用索引来快速定位对象,但元素做删除和插入操作的速度较慢,因为使用了数组,需要移动后面的元素来调整索引顺序,ArrayList是非同步的。
ArrayList类的构造方法如下:
ArrayList() //构造一个初始容量为10的空列表 ArrayList(int capacity) //构造一个指定初始容量的空列表 ArrayList(Collection c) //构造一个包含指定Collection的元素的列表
用一段代码总结一下ArrayList的相关用法:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class ListDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
Collection c1=new ArrayList();//创建一个具体的子类对象
for (int i = 0; i < 5; i++) {
c1.add(new Integer(i)); //注意要转换为对象
}
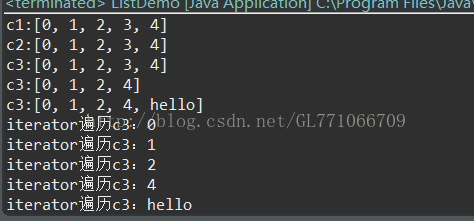
System.out.println("c1:"+c1);
Collection c2 =new ArrayList(c1);
System.out.println("c2:"+c2);
Collection c3 =new ArrayList();
c3.addAll(c1);
System.out.println("c3:"+c3);
c3.remove(new Integer(3));
System.out.println("c3:"+c3);
c3.add("hello");
System.out.println("c3:"+c3);
Iterator it =c3.iterator();
while(it.hasNext())
{
Object o=it.next();
System.out.println("iterator遍历c3:"+o);
}
}
}
2)LinkedList
同样实现List接口的LinkedList与ArrayList不同,ArrayList是一个动态数组,而LinkedList是一个双向链表。所以它除了有ArrayList的基本操作方法外还额外提供了get,remove,insert方法在LinkedList的首部或尾部。它适合实现队列。
与ArrayList一样,LinkedList也是非同步的。如果多个线程同时访问一个List,则必须自己实现访问同步
LinkedList类的构造方法如下:
LinkedList() //建立一个空的链接列表 LinkedList(Collection c) //建立一个链接列表,该链接列表由类集c中元素初始化
LinkedList类本身还定义了一些有用的方法,下面用一个程序来总结一下LinkedList相关用法
import java.util.LinkedList;
public class ListDemo2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
LinkedList lst=new LinkedList();
lst.add("F");
lst.add("B");
lst.add("D");
lst.add("E");
lst.add("C");
System.out.println("初始化后的lst:"+lst);
lst.addFirst("G");
lst.addLast("A");
lst.add(3, "three");
System.out.println("添加后lst:"+lst);
lst.remove(3);
lst.removeLast();
lst.removeFirst();
lst.remove("F");
System.out.println("删除后lst:"+lst);
Object o=lst.get(1);//修改内容
}
}
3.Set接口
Set是一种不包括重复元素的Collection。它维持它自己的内部排序,所以随机访问没有任何意义。与List一样,它同样允许null的存在但是仅有一个。由于Set接口的特殊性,所有传入Set集合中的元素都必须不同。Set接口有三个具体实现类,分别是散列集HashSet、链式散列集LinkedHashSet和树形集TreeSet。Set是一种不包含重复的元素的Collection,无序,即任意的两个元素e1和e2都有e1.equals(e2)=false,Set最多有一个null元素。需要注意的是:虽然Set中元素没有顺序,但是元素在set中的位置是由该元素的HashCode决定的,其具体位置其实是固定的。
此外需要说明一点,在set接口中的不重复是有特殊要求的。
举一个例子:对象A和对象B,本来是不同的两个对象,正常情况下它们是能够放入到Set里面的,但是如果对象A和B的都重写了hashcode和equals方法,并且重写后的hashcode和equals方法是相同的话。那么A和B是不能同时放入到Set集合中去的,也就是Set集合中的去重和hashcode与equals方法直接相关。
看一个例子:
public class TestSet {
public static void main(String[] args){
Set<String> books = new HashSet<String>();
//添加一个字符串对象
books.add(new String("Struts2权威指南"));
//再次添加一个字符串对象,
//因为两个字符串对象通过equals方法比较相等,所以添加失败,返回false
boolean result = books.add(new String("Struts2权威指南"));
System.out.println(result);
//下面输出看到集合只有一个元素
System.out.println(books);
}
}运行结果:
false
[Struts2权威指南]
说明:程序中,book集合两次添加的字符串对象明显不是一个对象(程序通过new关键字来创建字符串对象),当使用==运算符判断返回false,使用equals方法比较返回true,所以不能添加到Set集合中,最后只能输出一个元素。
(1)HashSet
HashSet 是一个没有重复元素的集合。它是由HashMap实现的,不保证元素的顺序(这里所说的没有顺序是指:元素插入的顺序与输出的顺序不一致),而且HashSet允许使用null 元素。HashSet是非同步的,如果多个线程同时访问一个哈希set,而其中至少一个线程修改了该set,那么它必须保持外部同步。 HashSet按Hash算法来存储集合的元素,因此具有很好的存取和查找性能。
HashSet使用和理解中容易出现的误区:
a.HashSet中存放null值
HashSet中是允许存入null值的,但是在HashSet中仅仅能够存入一个null值。
b.HashSet中存储元素的位置是固定的
HashSet中存储的元素的是无序的,但是由于HashSet底层是基于Hash算法实现的,使用了hashcode,所以HashSet中相应的元素的位置是固定的。
(2)LinkedHashSet
LinkedHashSet继承自HashSet,其底层是基于LinkedHashMap来实现的,有序,非同步。LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
package javaproject;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
public class hashset {
public static void main(String[] args) {
// TODO Auto-generated method stub
LinkedHashSet<String> hs = new LinkedHashSet<>();
hs.add("1");
hs.add("2");
hs.add("4");
hs.add("3");
hs.add("3");
hs.add(null);
hs.add(null);
//System.out.println("hello");
Iterator<String> it = hs.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}
运行结果:1
2
4
3
null(3)TreeSet
TreeSet是一个有序集合,其底层是基于TreeMap实现的,非线程安全。TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式。当我们构造TreeSet时,若使用不带参数的构造函数,则TreeSet的使用自然比较器;若用户需要使用自定义的比较器,则需要使用带比较器的参数。
注意:TreeSet集合不是通过hashcode和equals函数来比较元素的.它是通过compare或者comparaeTo函数来判断元素是否相等.compare函数通过判断两个对象的id,相同的id判断为重复元素,不会被加入到集合中。
三、map接口
Map与List、Set接口不同,它是由一系列键值对组成的集合,提供了key到Value的映射。同时它也没有继承Collection。在Map中它保证了key与value之间的一一对应关系。也就是说一个key对应一个value,所以它不能存在相同的key值,当然value值可以相同。Map常用的方法如下:
Object put(Object key,Object value) //如果该关键字已经存在,那么新值将代替旧值,方法返回关键字的旧值,如果关键字原先并不存在,则返回null Object remove(Object key) Object putAll(Map m) void clear() Object get(Object key) boolean containKey(Object key) boolean contaiinValue(Object value) int size() boolean isEmpty()
Set keySet() //返回映像中所有的“键”set集 Collection values() //返回映像中所有“值”的Collection集 Set entrySet() //返回映像中所有的“键/值对”set集
1.HashMap
HashMap是基于哈希表得Map接口的实现,它是使用频率最高的一个容器,提供所有可选的映射操作,它内部对“键“用set进行散列存放,所以根据“键”来取“值”效率很高,并且它允许使用null值和null键,但它不保证映射的顺序。package map;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class hashmap {
public static void main(String[] args) {
// TODO Auto-generated method stub
HashMap h=new HashMap();
h.put(1, "a");
h.put(2, "b");
h.put(3, "a");
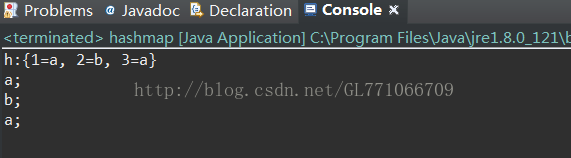
System.out.println("h:"+h);
Set s=h.keySet();
Iterator it =s.iterator();
while(it.hasNext())
{
System.out.println(h.get(it.next())+";");
}
}
}
2.LinkedHashMap
LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
由于LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能,但在迭代访问Map里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
3.TreeMap
TreeMap 是一个有序的key-value集合,非同步,基于红黑树(Red-Black tree)实现,TreeMap存储时会进行排序的,会根据key来对key-value键值对进行排序,其中排序方式也是分为两种,一种是自然排序,一种是定制排序,具体取决于使用的构造方法。自然排序:TreeMap中所有的key必须实现Comparable接口,并且所有的key都应该是同一个类的对象,否则会报ClassCastException异常。
定制排序:定义TreeMap时,创建一个comparator对象,该对象对所有的treeMap中所有的key值进行排序,采用定制排序的时候不需要TreeMap中所有的key必须实现Comparable接口。
package map;
import java.util.TreeMap;
public class LinkedHashMap {
public static void main(String[] args) {
// TODO Auto-generated method stub
TreeMap T = new TreeMap();
T.put("0","D");
T.put("2", "E");
T.put("2", "B");
T.put("1", "C");
T.put("3", "B");
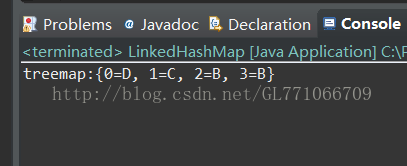
System.out.println("treemap:"+T);
}
}
4.遍历Map对象
方法一 在for-each循环中使用entries来遍历这是最常见的并且在大多数情况下也是最可取的遍历方式。在键值都需要时使用。
public class testMap {
public static void main(String[] args) {
Map<Integer, Integer> map = new HashMap<>();
map.put(1, 2);
map.put(3, 4);
map.put(5, 6);
if (!map.isEmpty()) {
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println("key=" + entry.getKey() + "value=" + entry.getValue());
}
}
}
}注意:for-each循环在java 5中被引入所以该方法只能应用于java 5或更高的版本中。如果你遍历的是一个空的map对象,for-each循环将抛出NullPointerException,因此在遍历前你总是应该检查空引用。
方法二 在for-each循环中遍历keys或values。
如果只需要map中的键或者值,你可以通过keySet或values来实现遍历,而不是用entrySet。
public class testMap {
public static void main(String[] args) {
Map<Integer, Integer> map = new HashMap<>();
map.put(1, 2);
map.put(3, 4);
map.put(5, 6);
for(Integer key:map.keySet())
{
System.out.println("key="+key);
}
for(Integer value:map.values())
{
System.out.println("value="+value);
}
}
}该方法比entrySet遍历在性能上稍好(快了10%),而且代码更加干净。
方法三使用Iterator遍历
使用泛型:
public class testMap {
public static void main(String[] args) {
Map<Integer, Integer> map = new HashMap<>();
map.put(1, 2);
map.put(3, 4);
map.put(5, 6);
Iterator<Map.Entry<Integer, Integer>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry<Integer, Integer> entry = entries.next();
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
}
}不使用泛型:
public class testMap {
public static void main(String[] args) {
Map<Integer, Integer> map = new HashMap<>();
map.put(1, 2);
map.put(3, 4);
map.put(5, 6);
Iterator entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry entry = (Entry) entries.next();
Integer key = (Integer) entry.getKey();
Integer value = (Integer) entry.getValue();
System.out.println("Key = " + key + ", Value = " + value);
}
}
}你也可以在keySet和values上应用同样的方法。
该种方式看起来冗余却有其优点所在。首先,在老版本java中这是惟一遍历map的方式。另一个好处是,你可以在遍历时调用iterator.remove()来删除entries,另两个方法则不能。根据javadoc的说明,如果在for-each遍历中尝试使用此方法,结果是不可预测的。
从性能方面看,该方法类同于for-each遍历(即方法二)的性能。
方法四、通过键找值遍历(效率低)
public class testMap {
public static void main(String[] args) {
Map<Integer, Integer> map = new HashMap<>();
map.put(1, 2);
map.put(3, 4);
map.put(5, 6);
for (Integer key : map.keySet()) {
Integer value = map.get(key);
System.out.println("key=" + key + ",value=" + value);
}
}
}作为方法一的替代,这个代码看上去更加干净;但实际上它相当慢且无效率。因为从键取值是耗时的操作(与方法一相比,在不同的Map实现中该方法慢了20%~200%)。如果你安装了FindBugs,它会做出检查并警告你关于哪些是低效率的遍历。所以尽量避免使用。
总结
如果仅需要键(keys)或值(values)使用方法二。如果你使用的语言版本低于java 5,或是打算在遍历时删除entries,必须使用方法三。否则使用方法一(键值都要)。
四、异同点
1.ArrayList和LinkedList(1)ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
(2)对于随机访问get和set,ArrayList绝对优于LinkedList,因为LinkedList要移动指针。
(3)对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
2.HashSet、LinkedHashSet、TreeSet比较
Set接口
Set不允许包含相同的元素,如果试图把两个相同元素加入同一个集合中,add方法返回false。
Set判断两个对象相同不是使用==运算符,而是根据equals方法。也就是说,只要两个对象用equals方法比较返回true,Set就不会接受这两个对象。
HashSet
HashSet有以下特点:
-> 不能保证元素的排列顺序,顺序有可能发生变化。
-> 不是同步的。
-> 集合元素可以是null,但只能放入一个null。
当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值也相等。
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对象通过equals方法比较返回true时,其hashCode也应该相同。另外,对象中用作equals比较标准的属性,都应该用来计算 hashCode的值。
public class student{
private String name;
private int a age;
public int hashCode(){
return age*name.hashCode;
}
public boolean equals(Object c)
{
student s=(student) o;
return age=s.age&&name.equals(s.name);
}
}TreeSet类
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0。
自然排序
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是负数,则表明obj1小于obj2。如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0。
定制排序
自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(T o1,T o2)方法。
package com.test;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.TreeSet;
/**
* @description 几个set的比较
* HashSet:哈希表是通过使用称为散列法的机制来存储信息的,元素并没有以某种特定顺序来存放;
* LinkedHashSet:以元素插入的顺序来维护集合的链接表,允许以插入的顺序在集合中迭代;
* TreeSet:提供一个使用树结构存储Set接口的实现,对象以升序顺序存储,访问和遍历的时间很快。
* @author Zhou-Jingxian
*
*/
public class SetDemo {
public static void main(String[] args) {
HashSet<String> hs = new HashSet<String>();
hs.add("B");
hs.add("A");
hs.add("D");
hs.add("E");
hs.add("C");
hs.add("F");
System.out.println("HashSet 顺序:\n"+hs);
LinkedHashSet<String> lhs = new LinkedHashSet<String>();
lhs.add("B");
lhs.add("A");
lhs.add("D");
lhs.add("E");
lhs.add("C");
lhs.add("F");
System.out.println("LinkedHashSet 顺序:\n"+lhs);
TreeSet<String> ts = new TreeSet<String>();
ts.add("B");
ts.add("A");
ts.add("D");
ts.add("E");
ts.add("C");
ts.add("F");
System.out.println("TreeSet 顺序:\n"+ts);
}
}输出结果:
HashSet 顺序:[D, E, F, A, B, C] LinkedHashSet 顺序:[B, A, D, E, C, F] TreeSet 顺序:[A, B, C, D, E, F]
3.HashMap、Hashtable、LinkedHashMap和TreeMap比较
Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为Null;允许多条记录的值为Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力。
Hashtable 与 HashMap类似,不同的是:它不允许记录的键或者值为空;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.
TreeMap实现SortMap接口,内部实现是红黑树。能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
一般情况下,我们用的最多的是HashMap,HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。
import java.util.HashMap;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.TreeMap;
public class MapTest {
public static void main(String[] args) {
//HashMap
HashMap<String,String> hashMap = new HashMap();
hashMap.put("4", "d");
hashMap.put("3", "c");
hashMap.put("2", "b");
hashMap.put("1", "a");
Iterator<String> iteratorHashMap = hashMap.keySet().iterator();
System.out.println("HashMap-->");
while (iteratorHashMap.hasNext()){
Object key1 = iteratorHashMap.next();
System.out.println(key1 + "--" + hashMap.get(key1));
}
//LinkedHashMap
LinkedHashMap<String,String> linkedHashMap = new LinkedHashMap();
linkedHashMap.put("4", "d");
linkedHashMap.put("3", "c");
linkedHashMap.put("2", "b");
linkedHashMap.put("1", "a");
Iterator<String> iteratorLinkedHashMap = linkedHashMap.keySet().iterator();
System.out.println("LinkedHashMap-->");
while (iteratorLinkedHashMap.hasNext()){
Object key2 = iteratorLinkedHashMap.next();
System.out.println(key2 + "--" + linkedHashMap.get(key2));
}
//TreeMap
TreeMap<String,String> treeMap = new TreeMap();
treeMap.put("4", "d");
treeMap.put("3", "c");
treeMap.put("2", "b");
treeMap.put("1", "a");
Iterator<String> iteratorTreeMap = treeMap.keySet().iterator();
System.out.println("TreeMap-->");
while (iteratorTreeMap.hasNext()){
Object key3 = iteratorTreeMap.next();
System.out.println(key3 + "--" + treeMap.get(key3));
}
}
}运行结果:
HashMap--> 3--c 2--b 1--a 4--d LinkedHashMap--> 4--d 3--c 2--b 1--a TreeMap--> 1--a 2--b 3--c 4--d
泛型
为什么使用泛型
提高安全性: 将运行期的错误转换到编译期. 如果我们在对一个对象所赋的值不符合其泛型的规定, 就会编译报错.避免强转: 比如我们在使用List时, 如果我们不使用泛型, 当从List中取出元素时, 其类型会是默认的Object, 我们必须将其向下转型为String才能使用。比如:
List l = new ArrayList();
l.add("abc");
String s = (String) l.get(0);而使用泛型,就可以保证存入和取出的都是String类型, 不必在进行cast了。比如:
List<String> l = new ArrayList<>();
l.add("abc");
String s = l.get(0);神么是泛型?
用来规定一个类、接口或方法所能接受的数据的类型. 就像在声明方法时指定参数一样, 我们在声明一个类, 接口或方法时, 也可以指定其"类型参数", 也就是泛型.泛型的使用
1. 定义类/接口:public class Test<T> {
private T obj;
public T getObj() {
return obj;
}
public void setObj(T obj) {
this.obj = obj;
}
}使用方式:
List<String> l = new ArrayList<>( );
重点说明:
变量类型中的泛型,和实例类型中的泛型,必须保证相同(不支持继承关系)。
既然有了这个规定, 因此在JDK1.7时就推出了一个新特性叫菱形泛型(The Diamond), 就是说后面的泛型可以省略直接写成<>, 反正前后一致。
2. 定义方法:
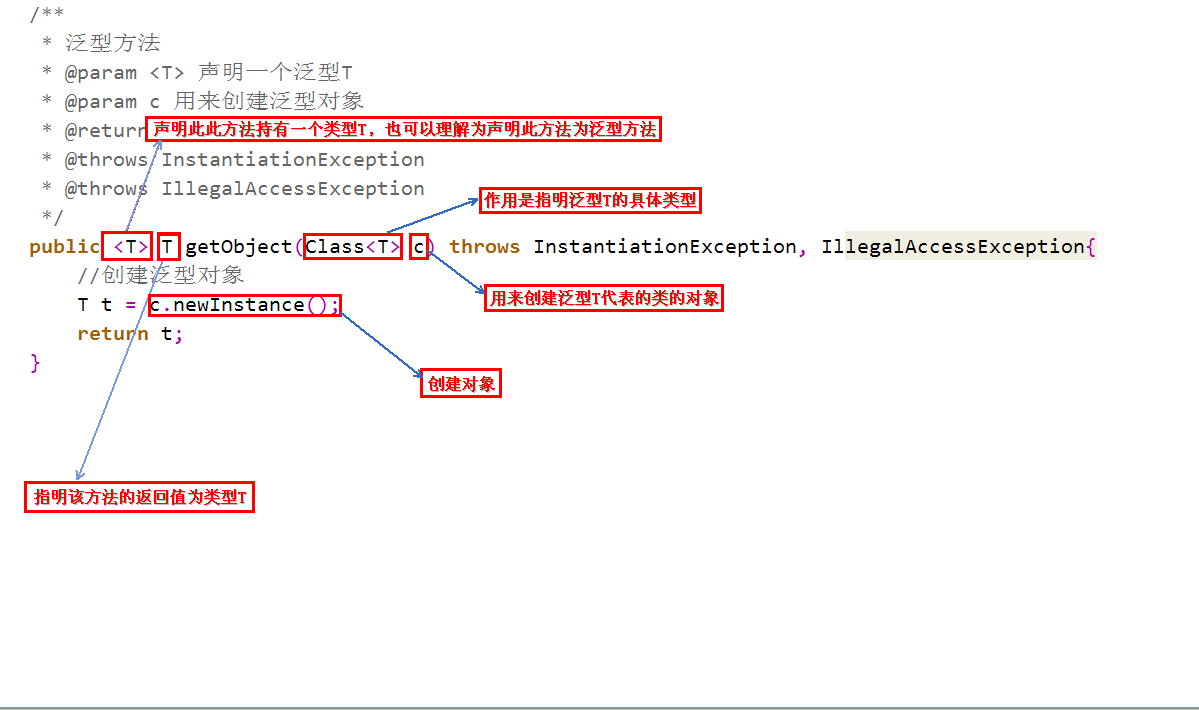
说明:
泛型的声明,必须在方法的修饰符(public,static,final,abstract等)之后,返回值声明之前。
方法参数列表,以及方法体中用到的所有泛型变量,都必须声明。
使用方式:

类型匹配符
<? >允许所有的泛型的引用调用
public static void print(List<?> list)
{
for(Object o:list)
{
System.out.println(o);
}
}
<? extends Number> 只允许Number及Number子类的引用调用
public static void print(List<? extends Number> list)
{
for(Number N:list)
{
System.out.println(N);
}
}
<? super Number>只允许Number及Number父类的引用调用
public static void print(List<? super Number> list)
{
for(Object o:list)
{
System.out.println(o);
}
}

相关文章推荐
- java中利用泛型构建的collection集合
- Java基础-集合框架12 泛型
- java笔记-集合框架-泛型、Map集合
- java语言基础(69)——集合框架(泛型的多种应用场景、泛型类、泛型方法、泛型接口)
- I学霸官方免费教程三十四:Java集合框架之泛型集合
- java集合与泛型
- JAVA集合的区别,常用的方法、遍历、迭代器、泛型
- 黑马程序员_java基础6-集合框架Collection和泛型
- 黑马程序员--JAVA<API>--集合、泛型等
- Java反射--通过反射了解集合泛型的本质
- Java基础之集合与泛型
- 黑马程序员java基础之集合Set中的TreeSet和泛型
- Java反射(六)-Java通过反射了解集合泛型的本质
- Java 泛型学习(二)泛型集合应用:实现对Map的迭代
- java反射之通过反射了解集合泛型的本质
- JavaSE(9):java集合与泛型
- Java基础进阶_day07_(泛型,Collection集合,迭代器,增强for循环)
- Java学习笔记——集合、泛型、异常
- 【java】反射(二)——泛型集合(在ArrayList<Integer>中加入String对象)
- Java总结(8)集合里的泛型