Spark算子总结(带案例)
2017-10-11 11:21
148 查看
Spark算子总结(带案例)
spark算子大致上可分三大类算子:
1、Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据。
2、Key-Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Key-Value型的数据。
3、Action算子,这类算子会触发SparkContext提交作业。
1)map
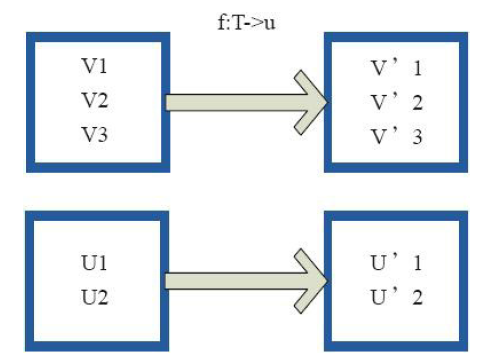
2)flatMap

3)mapPartiions
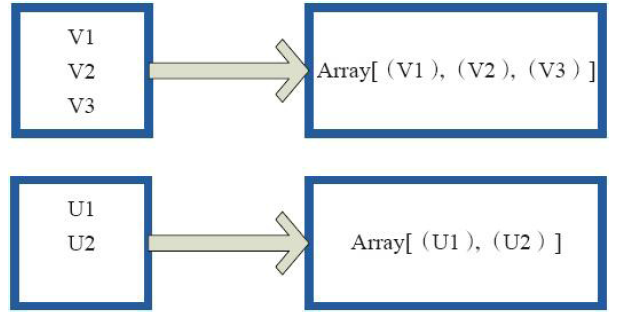
4)glom(形成一个Array数组)
5)union
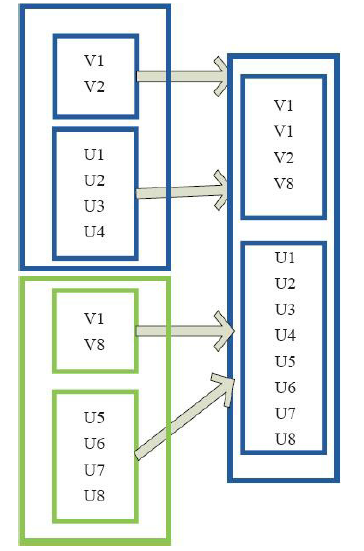
6)cartesian(笛卡尔操作)
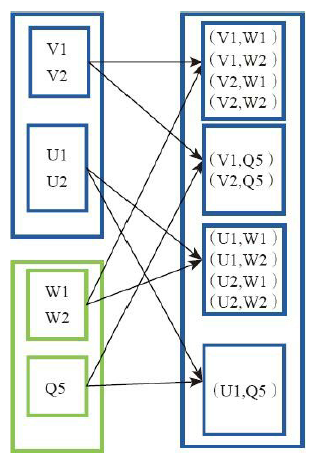
7)groupBy(生成相应的key,相同的放在一起)
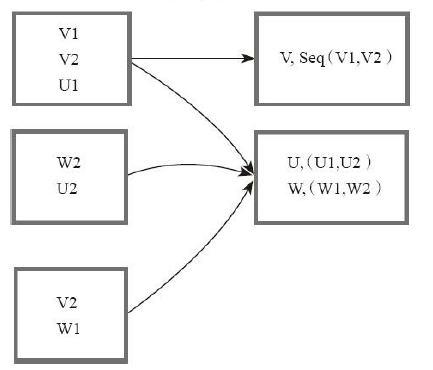
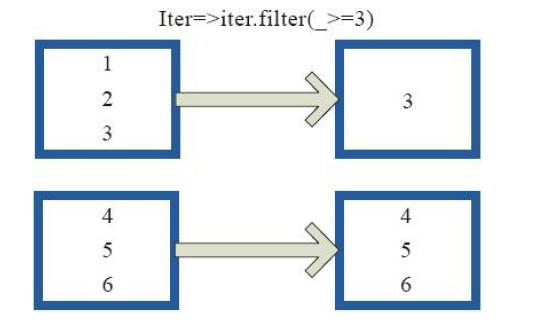
8)filter
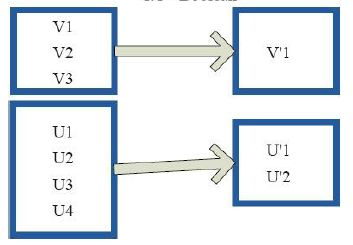
9)distinct(去重)
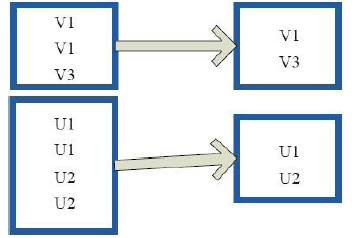
10)subtract(去掉含有重复的项)
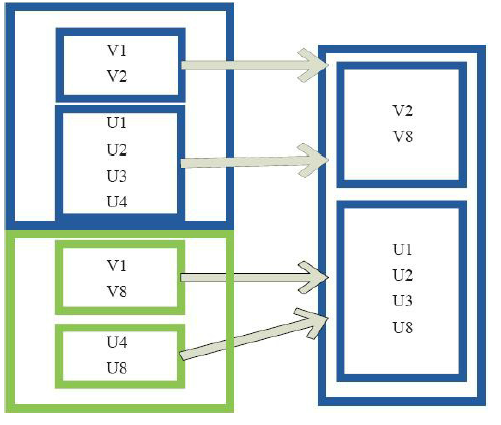
11)sample

12)takesample
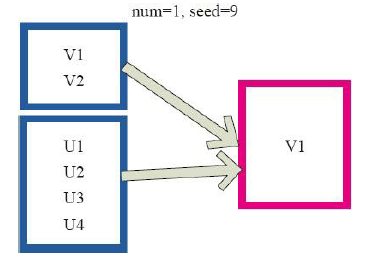
13)cache、persist
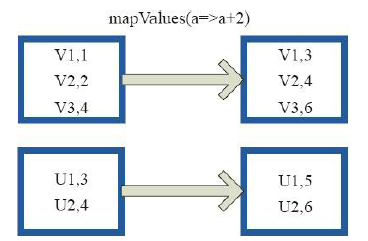
1)mapValues
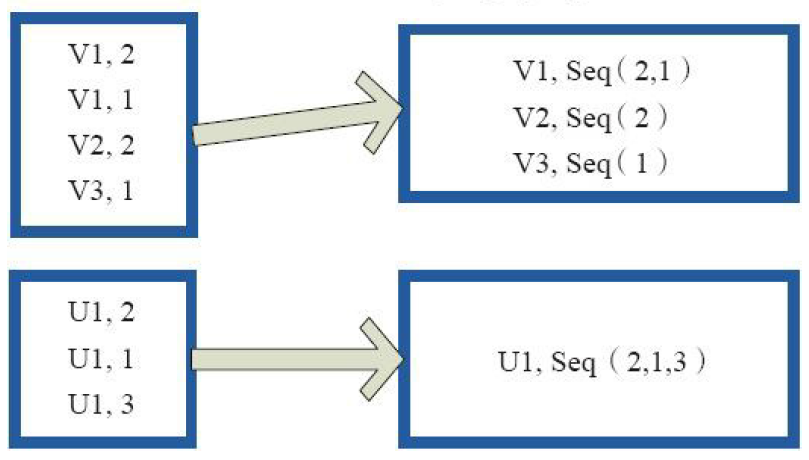
2)combineByKey
3)reduceByKey
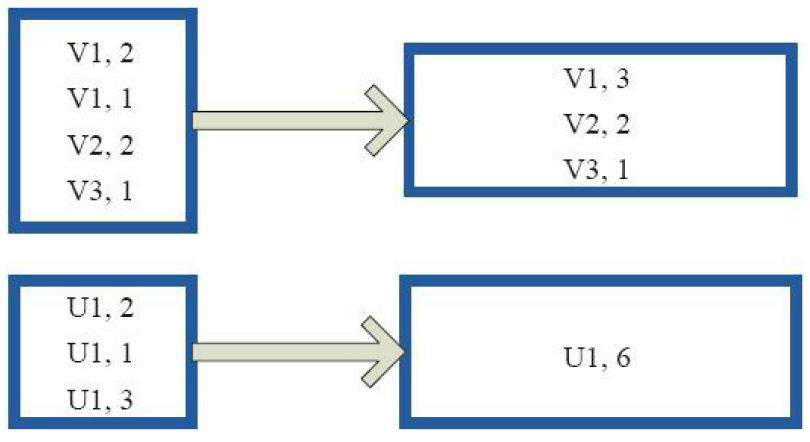
4)partitionBy
(对RDD进行分区操作)
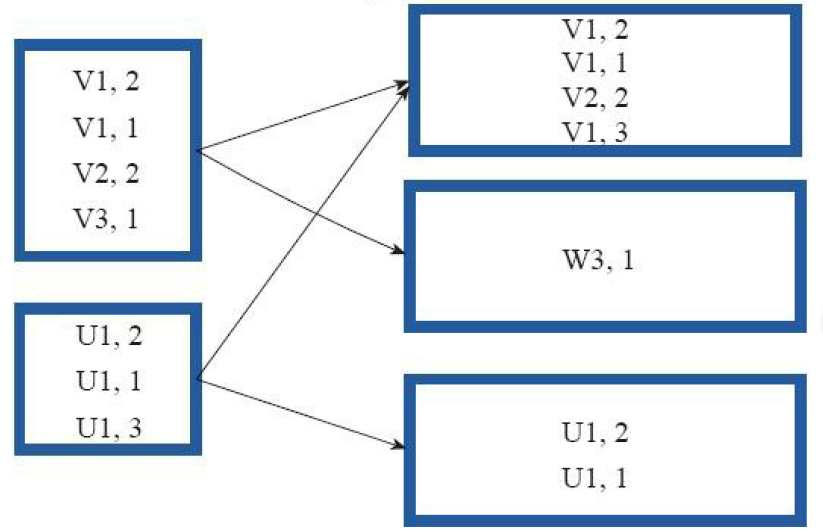
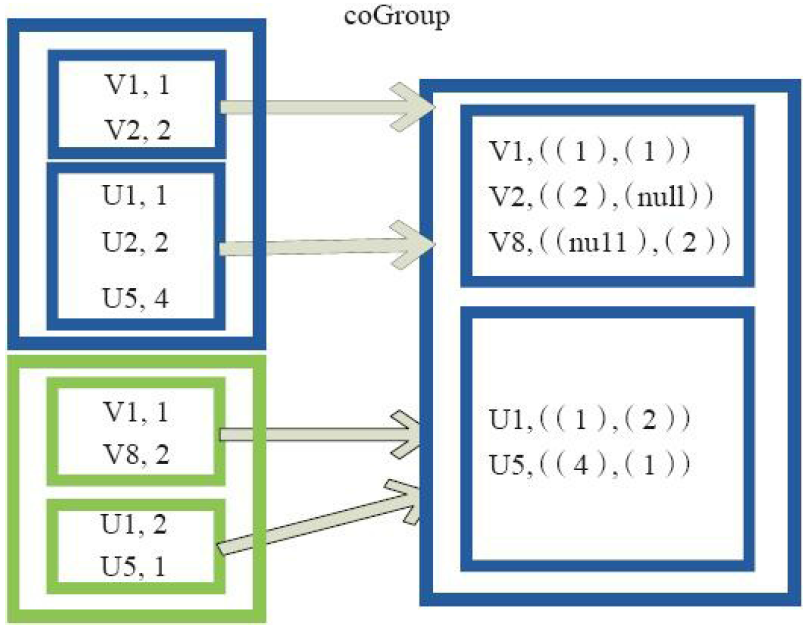
5)cogroup
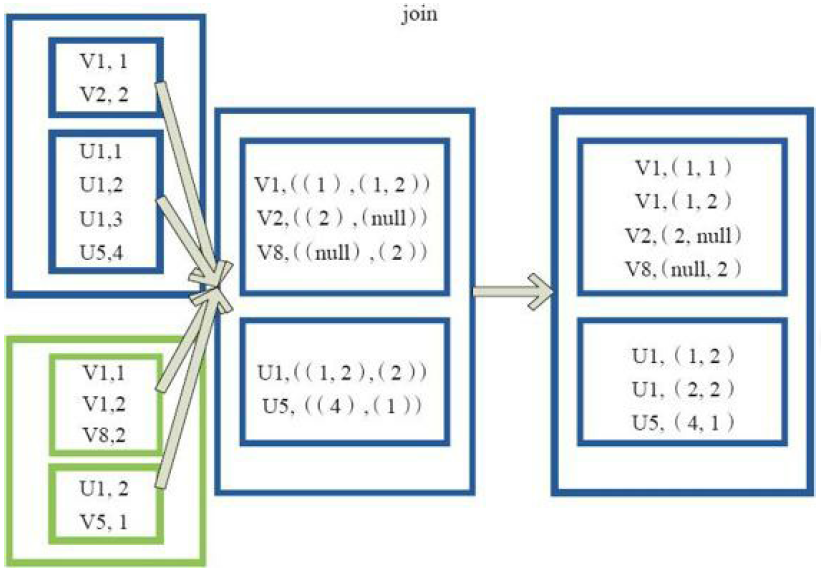
6)join
7)leftOutJoin
8)rightOutJoin
1)foreach

2)saveAsTextFile
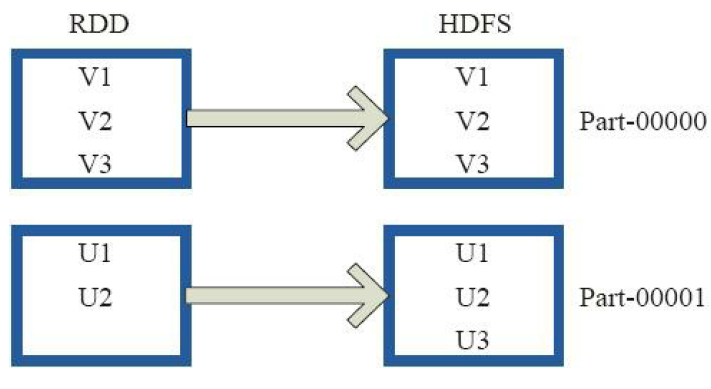
3)saveAsObjectFile

4)collect
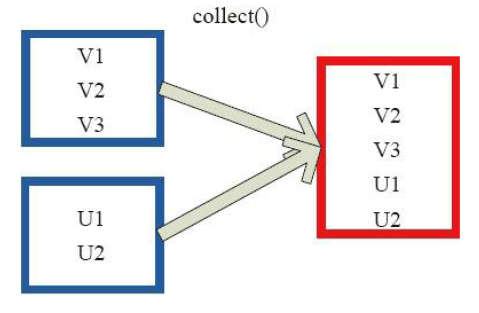
5)collectAsMap
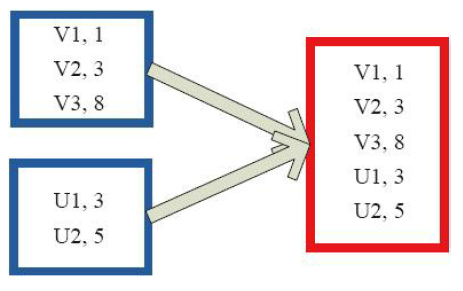
6)reduceByKeyLocally
7)lookup
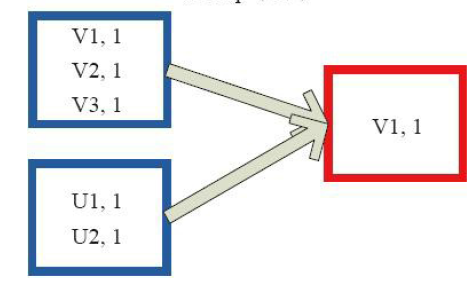
8)count
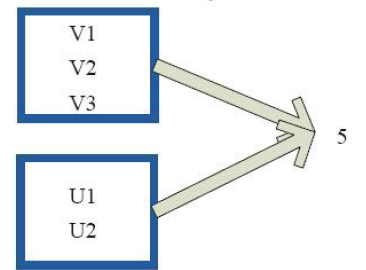
9)top
10)reduce
11)fold
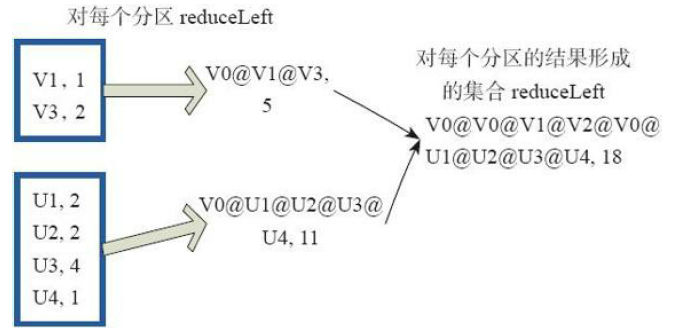
12)aggregate
spark算子大致上可分三大类算子:
1、Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据。
2、Key-Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Key-Value型的数据。
3、Action算子,这类算子会触发SparkContext提交作业。
一、Value型Transformation算子
1)mapval a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val b = a.map(_.length)
val c = a.zip(b)
c.collect
res0: Array[(String, Int)] = Array((dog,3), (salmon,6), (salmon,6), (rat,3), (elephant,8))2)flatMap
val a = sc.parallelize(1 to 10, 5) a.flatMap(1 to _).collect res47: Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10) sc.parallelize(List(1, 2, 3), 2).flatMap(x => List(x, x, x)).collect res85: Array[Int] = Array(1, 1, 1, 2, 2, 2, 3, 3, 3)
3)mapPartiions
val x = sc.parallelize(1 to 10, 3) x.flatMap(List.fill(scala.util.Random.nextInt(10))(_)).collect res1: Array[Int] = Array(1, 2, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 6, 6, 6, 6, 6, 6, 6, 6, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 9, 9, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 10)
4)glom(形成一个Array数组)
val a = sc.parallelize(1 to 100, 3) a.glom.collect res8: Array[Array[Int]] = Array(Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33), Array(34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66), Array(67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100))
5)union
val a = sc.parallelize(1 to 3, 1) val b = sc.parallelize(5 to 7, 1) (a ++ b).collect res0: Array[Int] = Array(1, 2, 3, 5, 6, 7)
6)cartesian(笛卡尔操作)
val x = sc.parallelize(List(1,2,3,4,5)) val y = sc.parallelize(List(6,7,8,9,10)) x.cartesian(y).collect res0: Array[(Int, Int)] = Array((1,6), (1,7), (1,8), (1,9), (1,10), (2,6), (2,7), (2,8), (2,9), (2,10), (3,6), (3,7), (3,8), (3,9), (3,10), (4,6), (5,6), (4,7), (5,7), (4,8), (5,8), (4,9), (4,10), (5,9), (5,10))
7)groupBy(生成相应的key,相同的放在一起)
val a = sc.parallelize(1 to 9, 3)
a.groupBy(x => { if (x % 2 == 0) "even" else "odd" }).collect
res42: Array[(String, Seq[Int])] = Array((even,ArrayBuffer(2, 4, 6, 8)), (odd,ArrayBuffer(1, 3, 5, 7, 9)))8)filter
val a = sc.parallelize(1 to 10, 3) val b = a.filter(_ % 2 == 0) b.collect res3: Array[Int] = Array(2, 4, 6, 8, 10)
9)distinct(去重)
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog", "Gnu", "Rat"), 2)
c.distinct.collect
res6: Array[String] = Array(Dog, Gnu, Cat, Rat)10)subtract(去掉含有重复的项)
val a = sc.parallelize(1 to 9, 3) val b = sc.parallelize(1 to 3, 3) val c = a.subtract(b) c.collect res3: Array[Int] = Array(6, 9, 4, 7, 5, 8)
11)sample
val a = sc.parallelize(1 to 10000, 3) a.sample(false, 0.1, 0).count res24: Long = 960
12)takesample
val x = sc.parallelize(1 to 1000, 3) x.takeSample(true, 100, 1) res3: Array[Int] = Array(339, 718, 810, 105, 71, 268, 333, 360, 341, 300, 68, 848, 431, 449, 773, 172, 802, 339, 431, 285, 937, 301, 167, 69, 330, 864, 40, 645, 65, 349, 613, 468, 982, 314, 160, 675, 232, 794, 577, 571, 805, 317, 136, 860, 522, 45, 628, 178, 321, 482, 657, 114, 332, 728, 901, 290, 175, 876, 227, 130, 863, 773, 559, 301, 694, 460, 839, 952, 664, 851, 260, 729, 823, 880, 792, 964, 614, 821, 683, 364, 80, 875, 813, 951, 663, 344, 546, 918, 436, 451, 397, 670, 756, 512, 391, 70, 213, 896, 123, 858)
13)cache、persist
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog", "Gnu", "Rat"), 2)
c.getStorageLevel
res0: org.apache.spark.storage.StorageLevel = StorageLevel(false, false, false, false, 1)
c.cache
c.getStorageLevel
res2: org.apache.spark.storage.StorageLevel = StorageLevel(false, true, false, true, 1)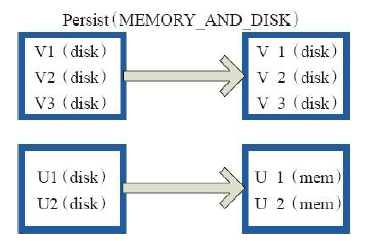
二、Key-Value型Transformation算子
1)mapValuesval a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val b = a.map(x => (x.length, x))
b.mapValues("x" + _ + "x").collect
res5: Array[(Int, String)] = Array((3,xdogx), (5,xtigerx), (4,xlionx), (3,xcatx), (7,xpantherx), (5,xeaglex))2)combineByKey
val a = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
val b = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)
val c = b.zip(a)
val d = c.combineByKey(List(_), (x:List[String], y:String) => y :: x, (x:List[String], y:List[String]) => x ::: y)
d.collect
res16: Array[(Int, List[String])] = Array((1,List(cat, dog, turkey)), (2,List(gnu, rabbit, salmon, bee, bear, wolf)))3)reduceByKey
val a = sc.parallelize(List("dog", "cat", "owl", "gnu", "ant"), 2)
val b = a.map(x => (x.length, x))
b.reduceByKey(_ + _).collect
res86: Array[(Int, String)] = Array((3,dogcatowlgnuant))
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val b = a.map(x => (x.length, x))
b.reduceByKey(_ + _).collect
res87: Array[(Int, String)] = Array((4,lion), (3,dogcat), (7,panther), (5,tigereagle))4)partitionBy
(对RDD进行分区操作)
5)cogroup
val a = sc.parallelize(List(1, 2, 1, 3), 1) val b = a.map((_, "b")) val c = a.map((_, "c")) b.co ee94 group(c).collect res7: Array[(Int, (Iterable[String], Iterable[String]))] = Array( (2,(ArrayBuffer(b),ArrayBuffer(c))), (3,(ArrayBuffer(b),ArrayBuffer(c))), (1,(ArrayBuffer(b, b),ArrayBuffer(c, c))) )
6)join
val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val b = a.keyBy(_.length)
val c = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
val d = c.keyBy(_.length)
b.join(d).collect
res0: Array[(Int, (String, String))] = Array((6,(salmon,salmon)), (6,(salmon,rabbit)), (6,(salmon,turkey)), (6,(salmon,salmon)), (6,(salmon,rabbit)), (6,(salmon,turkey)), (3,(dog,dog)), (3,(dog,cat)), (3,(dog,gnu)), (3,(dog,bee)), (3,(rat,dog)), (3,(rat,cat)), (3,(rat,gnu)), (3,(rat,bee)))7)leftOutJoin
val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val b = a.keyBy(_.length)
val c = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
val d = c.keyBy(_.length)
b.leftOuterJoin(d).collect
res1: Array[(Int, (String, Option[String]))] = Array((6,(salmon,Some(salmon))), (6,(salmon,Some(rabbit))), (6,(salmon,Some(turkey))), (6,(salmon,Some(salmon))), (6,(salmon,Some(rabbit))), (6,(salmon,Some(turkey))), (3,(dog,Some(dog))), (3,(dog,Some(cat))), (3,(dog,Some(gnu))), (3,(dog,Some(bee))), (3,(rat,Some(dog))), (3,(rat,Some(cat))), (3,(rat,Some(gnu))), (3,(rat,Some(bee))), (8,(elephant,None)))8)rightOutJoin
val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val b = a.keyBy(_.length)
val c = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
val d = c.keyBy(_.length)
b.rightOuterJoin(d).collect
res2: Array[(Int, (Option[String], String))] = Array((6,(Some(salmon),salmon)), (6,(Some(salmon),rabbit)), (6,(Some(salmon),turkey)), (6,(Some(salmon),salmon)), (6,(Some(salmon),rabbit)), (6,(Some(salmon),turkey)), (3,(Some(dog),dog)), (3,(Some(dog),cat)), (3,(Some(dog),gnu)), (3,(Some(dog),bee)), (3,(Some(rat),dog)), (3,(Some(rat),cat)), (3,(Some(rat),gnu)), (3,(Some(rat),bee)), (4,(None,wolf)), (4,(None,bear)))
三、Actions算子
1)foreachval c = sc.parallelize(List("cat", "dog", "tiger", "lion", "gnu", "crocodile", "ant", "whale", "dolphin", "spider"), 3)
c.foreach(x => println(x + "s are yummy"))
lions are yummy
gnus are yummy
crocodiles are yummy
ants are yummy
whales are yummy
dolphins are yummy
spiders are yummy2)saveAsTextFile
val a = sc.parallelize(1 to 10000, 3)
a.saveAsTextFile("mydata_a")
14/04/03 21:11:36 INFO FileOutputCommitter: Saved output of task 'attempt_201404032111_0000_m_000002_71' to file:/home/cloudera/Documents/spark-0.9.0-incubating-bin-cdh4/bin/mydata_a3)saveAsObjectFile
val x = sc.parallelize(1 to 100, 3)
x.saveAsObjectFile("objFile")
val y = sc.objectFile[Int]("objFile")
y.collect
res52: Array[Int] = Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100)4)collect
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog", "Gnu", "Rat"), 2)
c.collect
res29: Array[String] = Array(Gnu, Cat, Rat, Dog, Gnu, Rat)5)collectAsMap
val a = sc.parallelize(List(1, 2, 1, 3), 1) val b = a.zip(a) b.collectAsMap res1: scala.collection.Map[Int,Int] = Map(2 -> 2, 1 -> 1, 3 -> 3)
6)reduceByKeyLocally
val a = sc.parallelize(List("dog", "cat", "owl", "gnu", "ant"), 2)
val b = a.map(x => (x.length, x))
b.reduceByKey(_ + _).collect
res86: Array[(Int, String)] = Array((3,dogcatowlgnuant))7)lookup
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val b = a.map(x => (x.length, x))
b.lookup(5)
res0: Seq[String] = WrappedArray(tiger, eagle)8)count
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog"), 2)
c.count
res2: Long = 49)top
val c = sc.parallelize(Array(6, 9, 4, 7, 5, 8), 2) c.top(2) res28: Array[Int] = Array(9, 8)
10)reduce
val a = sc.parallelize(1 to 100, 3) a.reduce(_ + _) res41: Int = 5050
11)fold
val a = sc.parallelize(List(1,2,3), 3) a.fold(0)(_ + _) res59: Int = 6
12)aggregate
val z = sc.parallelize(List(1,2,3,4,5,6), 2)
// lets first print out the contents of the RDD with partition labels
def myfunc(index: Int, iter: Iterator[(Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
z.mapPartitionsWithIndex(myfunc).collect
res28: Array[String] = Array([partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3], [partID:1, val: 4], [partID:1, val: 5], [partID:1, val: 6])
z.aggregate(0)(math.max(_, _), _ + _)
res40: Int = 9
相关文章推荐
- Spark算子总结(带案例)
- JS加强总结第二天(实现select的全选和反选不选的操作 案例)
- 详细的KVO总结,包括基本改变,使用案例,注意点.看我就够了!
- IO流_字符流、IO流小结、IO流案例总结
- 《转型之战:传统企业的互联网机会》转型案例+访谈。案例一般,分析总结水平一般,二星推荐。
- 微信小程序知识总结及案例集锦
- 写的小案例中问题总结--baidumap
- 反射部分案例总结
- 购物车案例--张国亮--总结心得
- Java基础-17总结,登录注册案例,Set集合,HashSet,TreeSet,LinkHashSet
- 转:VC运行库版本不同导致链接.LIB静态库时发生重复定义问题的一个案例分析和总结
- 大数据时代:基于微软案例数据库数据挖掘知识点总结(Microsoft 关联规则分析算法)
- document.all的一个比较完整的总结及案例
- (原创)大数据时代:基于微软案例数据库数据挖掘知识点总结(Microsoft 神经网络分析算法)
- OpenGL编程指南(第八版)第一个渲染三角形案例代码在win8双显卡电脑VS2015中运行方法总结
- 17 API-集合(登录注册案例集合版,Set集合(Set_HashSet_TreeSet),Collection单列集合总结)
- JAVA问题总结之16-一维数组案例
- OAF开发概念和案例总结(项目总结)
- VC运行库版本不同导致链接.LIB静态库时发生重复定义问题的一个案例分析和总结
- 【总结】常见Java故障案例