【翻译】App Architecture (Android架构组件) 指南
2017-10-05 16:11
447 查看
【翻译】App Architecture 指南
译者:Android的新出架构系列指南还是很有意义的,在API层为MVVM架构提供了支持。也为追求更清晰的项目架构提供了更低门槛的指导。正好国庆无事可做,因为特别喜欢这几篇指南,所以抽几天时间翻译一下,英文水平不是很好,各位就将就着看,欢迎指正。以下是正文。==正文==
本篇指南适用于那些有过开发 app经验的人。而且想要找到更好的架构来帮助构建健壮的,高质量的app。
注:本篇指南假设读者已经熟悉Android Framework. 如果你是Android新手,那你应该先 Getting Started 系列文章,那里有本篇指南的预备知识。
app开发者常面临的问题
在大部分情况下,传统桌面应用只一个入口(在Launcher中的快捷方式中),并且只在单个进程中运行。但Android app 不一样,它有着更复杂的架构。一个典型的Android app 是由多个app components 组成,包括多个activity,fragment,service,content provider 以及 broadcast receiver.app 的大部分组件都在 manifest 中声明,Android OS 通过 manifest来决定如何将app整合到设备中,以便统一用户体验。然而正如上文提到的,传统桌面应用只在单个进程中执行,但一个好而规范的Android App需要更加的灵活,因为用户经常在各个app之间跳转,经常切换工作流和任务。
举个例子,你想在最喜欢的社交app上分享一张照片,这个app 触发一个camera Intent,Android 接收并处理 这个Intent,然后打开相机app。 在这时,虽然用户离开了社交app,但是仍然保持一致的用户体验。反过来,相机也可能触发其他Intent,比如打开图片选择器,这又可能打开其他app。 最终,用户又可以回到社交app并分享照片。这个过程中,如果来了一个电话,用户可能被迫中断去接电话,接完电话,然后再返回app分享图片。
在Android 中,这种App之间跳转的行为很常见,所以你的app必须能正确地处理流程。记住,手机app的资源是有限的,所以在任何时候,操作系统都可能杀死一些app来为新的app打开提供空间。
说到底,就是你的app组件可以被单独启动,且没有顺序限制,并且可以随时被系统或者用户销毁。因为app组件是短暂的,并且它们的生命周期(从创建到销毁)不受你的控制,所以不应该在app组件中存储任何的数据和状态 ,并且你的app组件不应该彼此依赖。
通用架构原则
如果不能在 app components 中保存数据和状态,那app应该怎样构建呢?在你的app中,应该关注的最重要的原则是分离关注点, 一个常见的错误就是,把所有的代码都写在Activity和Fragment中。其实任何非UI操作或者系统交互的代码都不应该写在这些类中,让它们尽可能地保持简洁,这样能避免很多生命周期相关的问题。因为你并不是真正地“拥有”这些类,它们只是连接OS和你App的衔接类。Android OS 可能基于用户的操作和其他因素(比如内存情况)来销毁这些它们。所以最好减少对这些类的依赖,以便为用户提供稳定的用户体验。
第二个重要原则是用Model 驱动UI,最好是可持久化的model。为什么是持久化的呢?有两个原因: 1. 如果系统杀死了你的app,用户不会丢失数据;2. 就算网络环境很差,你的app也可以继续工作。 Model负责处理App的数据,它可以独立于app 组件的生命周期,这样就可以避免生命周期导致的数据问题。让UI相关代码保持简洁且与app的逻辑分离,这样将更容易管理。如果App基于的Models 有着清晰的数据管理职责,那app将会变得方便测试,并且更加稳健。
推荐app架构
在本节,我们会通过一个用例来展示使用 Architecture Components 来构建app。注:没有任何一种app编写方式在任何场景下都是最好的。也就是说,这个推荐的架构应该只是一个开始,它适用于常见的应用场景。如果你已经有一个好的架构来编写你的app,那你没必要改变。
想象一下,我们将要构建UI来展示一个用户的基本信息。并通过REST接口从我们私有的后台获取用户基本信息。
构建用户界面
UI将会由一个fragment(UserProfileFragment.java) 和 它相关的layout文件(user_profile_layout.xml)组成。为了驱动UI,我们的数据模型需要持有两个数据元素:
The User ID: 用户的标识。 通过fragment arguments 将一个用户传入fragment,用ID是最好的方式。
The User Object: 一个保存用户数据的POJO
我们将会创建基于
ViewModel的
UserProfileViewModel类来保持这些信息。
ViewModel为指定的UI组件提供数据(比如一个fragment或者一个activity),并且负责和业务数据处理的交互,比如调用其他组件加载数据或者传递用户数据的修改。
ViewModel不与View接触,也不受configuration 变化的影响,比如旋转屏幕导致的Activity重新创建。
现在我们有3个文件:
user_profile.xml :屏幕的UI定义
UserProfileViewModel.java: 这个类为UI准备数据
UserProfileFragment.java :UI控制器,用于展示
ViewModel中的数据并且响应用户交互。
下面是我们的实现(为了简化,layout 文件就不写在下面了)
public class UserProfileViewModel extends ViewModel {
private String userId;
private User user;
public void init(String userId) {
this.userId = userId;
}
public User getUser() {
return user;
}
}public class UserProfileFragment extends LifecycleFragment {
private static final String UID_KEY = "uid";
private UserProfileViewModel viewModel;
@Override
public void onActivityCreated(@Nullable Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
String userId = getArguments().getString(UID_KEY);
viewModel = ViewModelProviders.of(this).get(UserProfileViewModel.class);
viewModel.init(userId);
}
@Override
public View onCreateView(LayoutInflater inflater,
@Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {
return inflater.inflate(R.layout.user_profile, container, false);
}
}注: 上面例子中是继承 LifecycleFragment 而不是Fragment。当Architecture Components 中的生命周期API稳定后,Android Support 库中的Fragment 将会实现 LifecycleOwner
现在,我们有这三个代码模块,我们应该怎么样关联它们呢?至少,当
ViewModel的数据发生改变,我们需要一个方式通知到UI。 其实,这就是
LiveData类的作用所在。
LiveData 一个数据的持有者,这个数据可以被外部观察。app 组件可以观察LiveData对象,从而知道数据的变化。而且不需要在它们之间建立显式死板的依赖。LiveData 自动适配app组件的生命周期(activities,fragments,services),并且会做一些操作来防止对象泄露,这样你的app就不会消耗更多的内存。
注: 如果你已经用了RxJava 或者Agera这样的库,你可以继续使用他们而不是LiveData。但是,当你使用它们或者其他类似的方法时,请保证你合适地处理生命周期,这样在相关的LifecycleOwner 停止时,数据流也会暂停。你可以添加android.arch.lifecycle:reactivestreams工件来将其他响应流库(比如RxJava2)与LiveData结合使用。
现在我们将
UserProfileViewModel中User成员替换为
LiveData<User>这样当数据发生更新时,就能通知到
Fragment。
LiveData的优势就是它是生命周期相关的,并且在数据无用时会自动清除引用。
public class UserProfileViewModel extends ViewModel {
...
private User user;
private LiveData<User> user;
public LiveData<User> getUser() {
return user;
}
}现在我们修改
UserProfileFragment,以便可以观察数据并更新UI。
@Override
public void onActivityCreated(@Nullable Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
viewModel.getUser().observe(this, user -> {
// update UI
});
}每次user 更新,
onChange方法都会调用,然后UI会刷新
如果熟悉其他的有使用观察回调的库,你可能会意识到,我们并没有重写fragment的
onStop()方法来终止对数据的观察。使用
LiveData不需要这么做,因为它本身就是生命周期相关的,这意味着它只会在
Fragment处于active state(即在
onStart到
onStop之间的状态)时才会调用
onChange回调。当
Fragment调用
onDestroy后,
LiveData也会自动移除
Fragment的观察。
我们也不需要应对configuration changes(比如屏幕旋转)的情况,因为
ViewMode会自动重置数据。所以,只要新的
Fragment重新初始化,它会收到一个相同的
ViewModel实例,并且回调方法也会被立即调用。这就是
ViewModel不应该直接引用View 的原因。因为
ViewModel可以在View的生命周期之外生存。详细请看The lifecycle of a ViewModel。
获取数据
现在,我们将Fragment和ViewModel联系起来了,但是
ViewModel应该如何获取user 数据呢?在这个例子中,假设后台提供一个REST 接口,我们使用Retrofit库来获取后台数据(你也可以使用其他库,只有能达到目的就行)。
这是和我们后台交互的
retrofit Webservice:
public interface Webservice {
/**
* @GET declares an HTTP GET request
* @Path("user") annotation on the userId parameter marks it as a
* replacement for the {user} placeholder in the @GET path
*/
@GET("/users/{user}")
Call<User> getUser(@Path("user") String userId);
}不成熟的
ViewModel实现可能会直接调用
WebService来获取数据,然后通过回调给user 对象赋值。尽管这样能实现功能,但是随着app业务的成长,这样会很难维护。因为
ViewModel承担了太多的职责,而这违反了之前提到的“分离关注点”原则。而且,
ViewModel的适应范围是与
Activity和
Fragment绑在一起的,这样生命周期一结束就丢失数据,用户体验不好。 取而代之,我们的
ViewModel会将获取数据的工作代理给一个新的Repository module.
Repository modules负责处理数据操作。他们为app其他部分提供纯粹的API。它们从哪儿获取数据,当数据发送变化时应该调用什么API。你可以将它们看作不同数据源(持久化module,web service,cache等)之间的中间件。
下面的
UserRepository类使用
WebService来获取user data item.
java
public class UserRepository {
private Webservice webservice;
// ...
public LiveData<User> getUser(int userId) {
// This is not an optimal implementation, we'll fix it below
final MutableLiveData<User> data = new MutableLiveData<>();
webservice.getUser(userId).enqueue(new Callback<User>() {
@Override
public void onResponse(Call<User> call, Response<User> response) {
// error case is left out for brevity
data.setValue(response.body());
}
});
return data;
}
}尽管repository module看起来多余,但是有着它的重要目的。它将app的rest数据源抽象出来。现在我们
ViewModel不依赖于WebService,这意味着需要时就可以替换成另外一个实现。
注:为了简化例子,我们忽略了网络错误的情况。提供一个暴露网络错误和加载状态的实现,see Addendum: exposing network status.
管理组件之间的依赖
上面的
UserRepository类需要一个
Webservice实例,如果简单地创建它,那也需要知道
Webservice的依赖。这会显著地让代码变复杂且重复(e.g. 每个需要
Webservice的类需要知道如何创建它,以及它的依赖),并且,可能除了
UserRepository之外,还有其他类需要
Webservice。如果每个类都创建一个新的
WebService那会很耗资源。
解决这个问题,你可以使用以下两种模式:
Dependency Injection 依赖注入可以让类定义它们的依赖,却不用创建它们。在运行时,另一个类来负责提供这些依赖。我们推荐谷歌的 Dagger 2 库来实现Android app 的依赖注入。 Dagger 2 通过遍历依赖树自动构建对象,并且在编译时有依赖保证。
Service Locator Service Locator 提供了一个注册关系,这个注册关系描述了哪里可以获取他们的依赖,而不是通过构造方法创建它们。相比Dependency Injection (DI) 来说,Service Locator更容易实现。所以,如果你不熟悉DI,那就使用Service Locator。
这些模式让你的代码更容易扩展,因为它们提供一种清晰的依赖管理模式,这种模式避免了重复代码和 增加复杂性。使用这两种模式,就可以为了测试更改实现,这是使用它们的主要的好处。
在这个例子中,我们将使用 Dagger 2 来管理依赖。
连接 ViewModel 和 repository
现在我们修改UserProfileViewModel,使用repository。
public class UserProfileViewModel extends ViewModel {
private LiveData<User> user;
private UserRepository userRepo;
@Inject // UserRepository parameter is provided by Dagger 2
public UserProfileViewModel(UserRepository userRepo) {
this.userRepo = userRepo;
}
public void init(String userId) {
if (this.user != null) {
// ViewModel is created per Fragment so
// we know the userId won't change
return;
}
user = userRepo.getUser(userId);
}
public LiveData<User> getUser() {
return this.user;
}
}缓存数据
上面的repository 实现利于将web 服务的调用抽象出来,但是由于它只依赖一个数据源,所以显得不是特别腻害。上面
UserRepository的实现的问题在于在获取数据后,它没有保存数据。 如果用户离开
UserProfileFragment然后再回来,那app会重新获取数据。这样有两个不好的地方:1.浪费了宝贵的网络带宽。 2.用户被强制等待新的网络查询完成。为了解决这个,我们会加一个新的数据源到
UserRepository中 ,这个数据源会将
User对象缓存到内存中。
@Singleton // informs Dagger that this class should be constructed once
public class UserRepository {
private Webservice webservice;
// simple in memory cache, details omitted for brevity
private UserCache userCache;
public LiveData<User> getUser(String userId) {
LiveData<User> cached = userCache.get(userId);
if (cached != null) {
return cached;
}
final MutableLiveData<User> data = new MutableLiveData<>();
userCache.put(userId, data);
// this is still suboptimal but better than before.
// a complete implementation must also handle the error cases.
webservice.getUser(userId).enqueue(new Callback<User>() {
@Override
public void onResponse(Call<User> call, Response<User> response) {
data.setValue(response.body());
}
});
return data;
}
}数据持久化
在当前的实现中,如果用户旋转屏幕或者离开再返回app,已经存在的UI将会立即展示,因为repository 是从内存cache中获取数据。但是如果用户离开app,数小时后Android OS杀死进程,这时用户才返回app,那会发生什么呢?在当前的实现中,我们需要从网络重新获取数据。这不仅是一个坏的用户体验,而且也会浪费用户手机流量。你可以通过缓存Web请求来简单修复这个问题,但是它会引入新的问题。如果
一个合适的解决方案就是使用一个持久化模型。这就轮到Room持久化库在救场了。
Room是一个对象映射库,它提供了本地数据持久化功能,只需要编写很少的模板代码。在编译时,它将每一个query 和 schema做检查,所以错误的SQL查询会导致编译错误,而不是运行时才查询失败。Room抽象了一些表查询潜在的实现细节。同时,它也允许外部观察数据库中的变化(包括集合和联表查询),它通过LiveData对象暴露这些变化。而且,它显式地定义了线程约束,这样就解决了一些常见问题。比如在主线程获取内部存储数据。
注: 如果你熟悉其他的持久化解决方案(比如SQLite ORM) 或者其他不同的数据库(比如 Realm),你不必用Room替换它们,除非Room的特征集更适合你的情况。
为了使用Room,我们需要定义本地的Schema。首先,给
User类添加
@Entity注解,标志这个类映射数据库中的一个table.
@Entity
class User {
@PrimaryKey
private int id;
private String name;
private String lastName;
// getters and setters for fields
}然后,继承
RoomDatabase为你的app创建一个数据库
@Database(entities = {User.class}, version = 1)
public abstract class MyDatabase extends RoomDatabase {
}注意,
MyDatabase是抽象的。Room自动提供一个实现。详细请看Room 文档。
现在我们需要一种插入user对象到数据库的方式,下面我们创建一个 data access object (DAO)
@Dao
public interface UserDao {
@Insert(onConflict = REPLACE)
void save(User user);
@Query("SELECT * FROM user WHERE id = :userId")
LiveData<User> load(String userId);
}然后,在我们数据库类中引用这个DAO
@Database(entities = {User.class}, version = 1)
public abstract class MyDatabase extends RoomDatabase {
public abstract UserDao userDao();
}注意,load 方法返回一个
LiaveData<User>。Room知道数据库何时被修改,并且会通知所有的观察者。因为使用LiveData,这种方式会变得高效,因为只在有至少一个active状态的观察者情况下,才会更新数据。
注:因为是alpha1 版本,Room针对表修改的检查可能会失效,这意味它可能发出虚假的修改通知。
现在,我们修改
UserRepository类来协调Room 数据源
@Singleton
public class UserRepository {
private final Webservice webservice;
private final UserDao userDao;
private final Executor executor;
@Inject
public UserRepository(Webservice webservice, UserDao userDao, Executor executor) {
this.webservice = webservice;
this.userDao = userDao;
this.executor = executor;
}
public LiveData<User> getUser(String userId) {
refreshUser(userId);
// return a LiveData directly from the database.
return userDao.load(userId);
}
private void refreshUser(final String userId) {
executor.execute(() -> {
// running in a background thread
// check if user was fetched recently
boolean userExists = userDao.hasUser(FRESH_TIMEOUT);
if (!userExists) {
// refresh the data
Response response = webservice.getUser(userId).execute();
// TODO check for error etc.
// Update the database.The LiveData will automatically refresh so
// we don't need to do anything else here besides updating the database
userDao.save(response.body());
}
});
}
}注意,尽管我们改变了
UserRepository中数据的来源,但是我们不需要修改
UserProfileViewModel和
UserProfileFragment这两个类。这就体现了抽象化的灵活之处。这样也有利于测试,比如你在测试
UserProfileViewModel时,你可以写一个假的
UserRepository。
现在代码已经完成了。如果用户几天后重返相同的UI界面上,用户信息会立即显示出来,因为我们做了持久化存储。同时,如果数据变化,repository会在后台更新数据。当然这都取决于你的业务场景,也有可能持久化保存的数据太旧了,你不想要显示它们。
在一些场景中,比如下拉刷新,如果有网络操作在进行,需要通过UI告诉用户。这也是一个分离UI与实际数据的实践场景,因为数据可能因为多种原因被更新(比如,下拉刷新好友列表,user信息可能会重新获取从而触发LiveData\更新。从UI的角度,一个正在进行的请求只是一个数据点,和其他的数据点相似(比如 user 对象)
有2个常见的解决方案:
修改
getUser方法,让它返回一个包含网络操作状态的LiveData。 在 Addendum: exposing network status这一节中提供了一个实现示例。
提供其他能返回User刷新状态的public方法。如果只为了响应用户的行为(比如下拉刷新)而显示网络状态,那这种方案会更好。
单一数据源(source of truth)
不同的REST API端点返回相同的数据,这种现象很常见。以此举例,如果我们的后台有另一个端点(endPoint)也返回好友列表,那同一个用户数据就可能来自这两个不同的API端点,可能只会有细微的差别。如果
UserRepository只是原样返回Webservice请求的响应,我们不同UI界面就可能显示不一致的数据,因为这两次请求有时间差,服务器的数据可能已经改变。这就是为什么在
UserRepository的实现中,web service的回调只将数据保存至数据库,然后,数据库一旦被修改,就会触发LiveData的回调 。
在这个模型中,数据库作为单一数据源,并且app的其他部分通过repository获取数据。不管是否用到磁盘缓存,我们建议你的repository指定一个数据源作为单一数据源。
最终架构
下面的示例图展示了我们推荐的架构,包括所有的Modules以及彼此交互。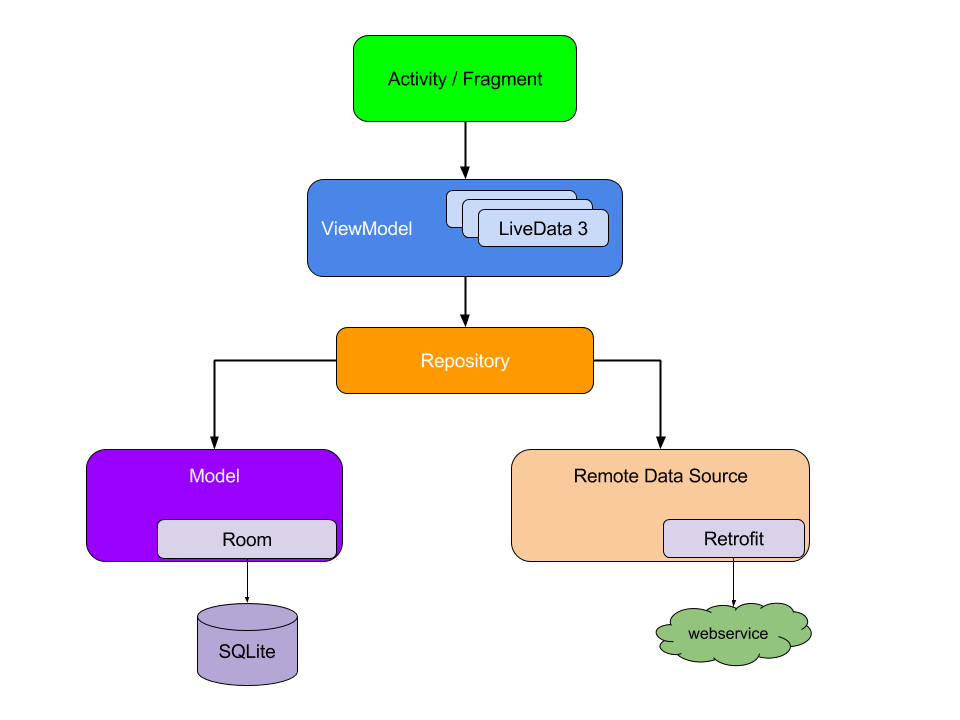
指导原则
编程是一个创造性的领域,编写Android app 也不例外。解决同一个问题有许多方式,不管是多个activities 或者 fragments中间的数据交互,还是远程获取数据并存入本地,或者稍微重量级的app会遇到任何常见的场景。当下面的建议并不是强制性的,它是我们经验的结晶,从长远看来,按照这些建议编程会让你的代码更加稳健,方便测试和维护。
manifest 中定义的入口-activities, fragments, services, broadcast-receiver等- 都不是数据源。相反,它们应该只协调和这个入口相关的数据子集。因为每个app组件的存活都是相当短暂的,取决于用户与设备的交互和整体的运行状况,你肯定不会想任何一个入口变成数据源的。
严格定义各个Module的职责范围。例如,不要将请求网络数据的代码散落在多个类和包中。同样,不要把不相干的功能都塞入同一个类中(比如数据缓存和数据绑定)。
每个module都应该尽可能向外少暴露类和接口。不要被所谓的”就这一次” 的捷径所诱惑, 从而暴露一个module的内部实现。 你可能在短期节省了时间,但是在长期的代码演变过程中,你会为此付出多次代价。
正如定义你Modules之间的交互一样,想想,怎么样才能让每一个Module易于单独测试。举个栗子,如果有一个定义得很好的获取网络数据的API,那将数据保存到数据库的持久化Module会更加容易测试。相反,如果你将这两个module的逻辑混在一起,或者将你的网络请求代码散落在你整个代码基础上,那将会很难测试,甚至不可测试。
app的核心应该是那些让它出类拔萃的东西。不要浪费时间重新造轮子或者一遍又一遍地写模板代码。相反,集中经历在那些让你app独一无二的地方,让Android 架构组件 和 其他推荐的库来做重复的模块代码。
尽可能地将最新的,有意义的数据持久化保存,这样你的app在离线模式也能用。你可能享受着稳定快速的网络连接,但是你的用户可能并没有。
你的repository应该指定一个数据源作为单一数据源(source of truth)。不论什么时候你的app需要获取这些数据,这些数据都应该来源于这个单一数据源。更多信息请看 Single source of truth。
….未完待续…

相关文章推荐
- [译文]Android架构组件-App架构指南
- Android架构组件Room指南
- Android官方架构组件指南
- Android官方架构组件指南
- Android SDK开发指南(翻译)系列一:最佳实践(二)-- 反应速度设计
- Android架构组件学习之LifeCycle
- 谷歌官方Android应用架构库——添加组件到项目中
- Android官方架构组件介绍之ViewModel
- Android Architecture Components应用架构组件源码详解(基于1.0以上)(第一篇生命周期监听分离LifecycleObserver和LifecycleOwner源码详解)
- Android官方技术文档翻译——Gradle 插件用户指南(6)
- Android架构宏观理解和Android四个重要组件概念
- DotNET应用架构设计指南(第二章:设计应用程序和服务组件(1-4))已上传
- Android 开发指南 翻译3:User Interface: Input Events
- Android架构组件——ViewModel
- Android架构组件一 Android Architecture Components开发入门
- Android官方技术文档翻译——Gradle 插件用户指南(4)
- 谷歌官方Android应用架构库——App 架构指南
- Android学习指南之十二:列表组件ListView
- android studio gradle plugin 用户指南 选择性翻译
- jBPM3.12用户指南中文翻译----第十九章 可插式架构