深度学习笔记整理
2017-09-28 19:32
302 查看
近期工作:
1.对车辆碰撞、驾驶行为分析方面论文汇总,并选择性的阅读了几篇。
2.学习深度学习相关知识,Python数据处理知识。
3.学习TensorFlow神经网络库,并搭建了开发环境。
深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。


数学式子:

,其中

是输入向量,

是输出向量,

是偏移向量,

是权重矩阵,

是激活函数。每一层仅仅是把输入

经过如此简单的操作得到

。
数学理解:通过如下5种对输入空间(输入向量的集合)的操作,完成 输入空间 —> 输出空间 的变换 (矩阵的行空间到列空间)。 注:用“空间”二字的原因是被分类的并不是单个事物,而是一类事物。空间是指这类事物所有个体的集合。
1. 升维/降维
2. 放大/缩小
3. 旋转
4. 平移
5. “弯曲” 这5种操作中,1,2,3的操作由

完成,4的操作是由

完成,5的操作则是由
来实现。

每层神经网络的数学理解:用线性变换跟随着非线性变化,将输入空间投向另一个空间。
线性可分视角:神经网络的学习就是学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投向线性可分/稀疏的空间去分类/回归。
增加节点数:增加维度,即增加线性转换能力。
增加层数:增加激活函数的次数,即增加非线性转换次数。
。
既然我们希望网络的输出尽可能的接近真正想要预测的值。那么就可以通过比较当前网络的预测值和我们真正想要的目标值,再根据两者的差异情况来更新每一层的权重矩阵(比如,如果网络的预测值高了,就调整权重让它预测低一些,不断调整,直到能够预测出目标值)。因此就需要先定义“如何比较预测值和目标值的差异”,这便是损失函数或目标函数(loss
function or objective function),用于衡量预测值和目标值的差异的方程。loss function的输出值(loss)越高表示差异性越大。那神经网络的训练就变成了尽可能的缩小loss的过程。所用的方法是梯度下降(Gradient d
1322e
escent):通过使loss值向当前点对应梯度的反方向不断移动,来降低loss。一次移动多少是由学习速率(learning
rate)来控制的。
然而使用梯度下降训练神经网络拥有两个主要难题。
梯度下降寻找的是loss function的局部极小值,而我们想要全局最小值。如下图所示,我们希望loss值可以降低到右侧深蓝色的最低点,但loss有可能“卡”在左侧的局部极小值中。

试图解决“卡在局部极小值”问题的方法分两大类:
调节步伐:调节学习速率,使每一次的更新“步伐”不同。常用方法有:
随机梯度下降(Stochastic Gradient Descent (SGD):每次只更新一个样本所计算的梯度
小批量梯度下降(Mini-batch gradient descent):每次更新若干样本所计算的梯度的平均值
动量(Momentum):不仅仅考虑当前样本所计算的梯度;Nesterov动量(Nesterov Momentum):Momentum的改进
Adagrad、RMSProp、Adadelta、Adam:这些方法都是训练过程中依照规则降低学习速率,部分也综合动量
优化起点:合理初始化权重(weights initialization)、预训练网络(pre-train),使网络获得一个较好的“起始点”,如最右侧的起始点就比最左侧的起始点要好。常用方法有:高斯分布初始权重(Gaussian distribution)、均匀分布初始权重(Uniform distribution)、Glorot 初始权重、He初始权、稀疏矩阵初始权重(sparse matrix)
机器学习所处理的数据都是高维数据,该如何快速计算梯度、而不是以年来计算。 其次如何更新隐藏层的权重? 解决方法是:计算图:反向传播算法 这里的解释留给非常棒的Computational
Graphs: Backpropagation 需要知道的是,反向传播算法是求梯度的一种方法。如同快速傅里叶变换(FFT)的贡献。 而计算图的概念又使梯度的计算更加合理方便。

前馈神经网络采用一种单向多层结构。其中每一层包含若干个神经元,同一层的神经元之间没有互相连接,层间信息的传送只沿一个方向进行。其中第一层称为输入层。最后一层为输出层.中间为隐含层,简称隐层。隐层可以是一层。也可以是多层。
网络结构:2维输入

1维输出

结构表达式:
正向传递:

(1)

用于表达随机变量

的值,

表示随机变量

的值,

是我们的神经网络模型,等号右侧是具体的表达。
损失函数:

该loss就是比较
和

中所有值的差别。
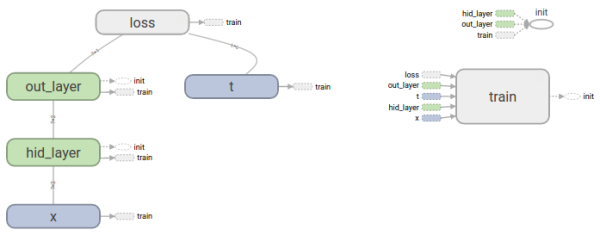
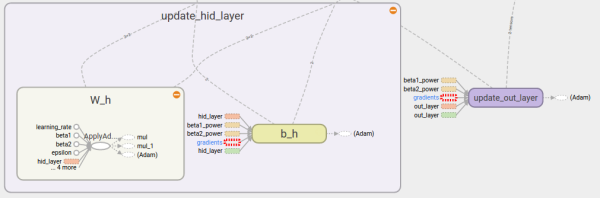
整体结构:左侧的图表示网络结构。绿色方框表示操作,也叫作层(layer)。该结构中,输入
经过hid_layer算出隐藏层的值

,再传递给out_layer,计算出预测值
,随后与真实值
进行比较,算出损失

,再从反向求导得出梯度后对每一层的
和

进行更新。
正向传递:如果放大hid_layer内部,从下向上,会看到

先用truncated_normal的方法进行了初始化,随后与输入
进行矩阵相乘,加上

,又经过了activation后,送给了用于计算
的out_layer中。而
的计算方式和
完全一致,但用的是不同的权重

和偏移

。最后将算出的预测值
与真实值
一同求出
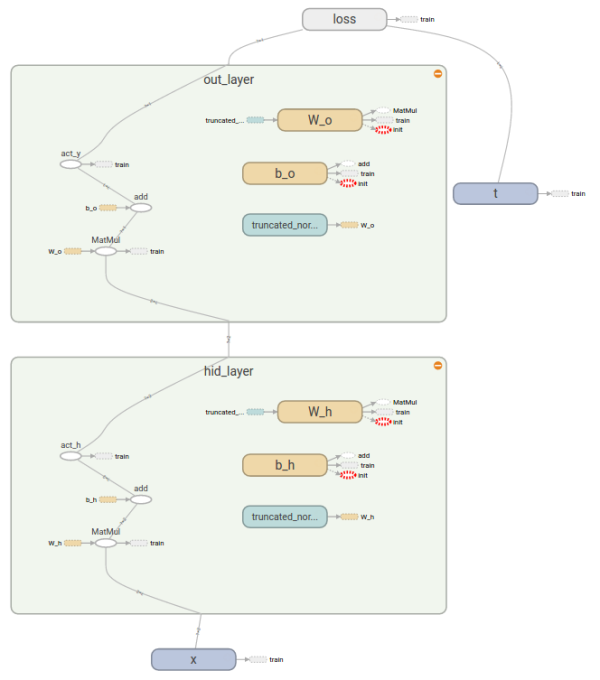
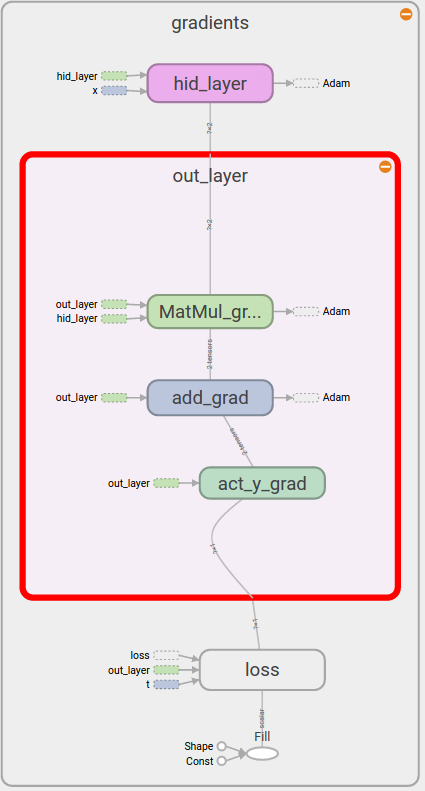
反向传递:如果放大train的内部,再放大内部中的gradients,就可以看到框架是从
开始一步步反向求得各个层中
和
的梯度的。
权重更新:求出的各个层
和
的梯度,将会被用于更新对应的
和
,并用learning
rate控制一次更新多大。(beta1_power和beta2_power是Adam更新方法中的参数,目前只需要知道权重更新的核心是各自对应的梯度。)
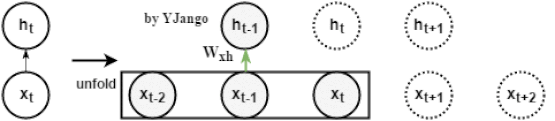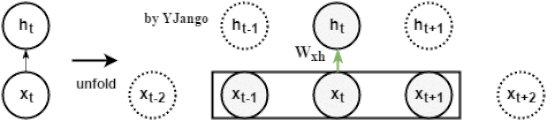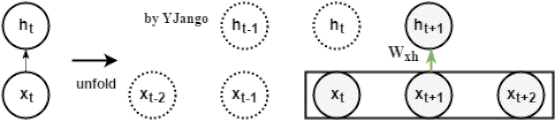
动态图:左侧是时间维度展开前,右侧是展开后(单位时刻实际工作的只有灰色部分。)。前馈网络的特点使不同时刻的预测完全是独立的。我们只能通过窗处理的方式让其照顾到前后相关性。
数学式子:

,concat表示将向量并接成一个更大维度的向量。
学习参数:需要从大量的数据中学习

和
。
要学习各个时刻(3个)下所有维度(39维)的关系(39*3个),就需要很多数据。
动态图:左侧是时间维度展开前,回路方式的表达方式,其中黑方框表示时间延迟。右侧展开后,可以看到当前时刻的

并不仅仅取决于当前时刻的输入

,同时与上一时刻的

也相关。
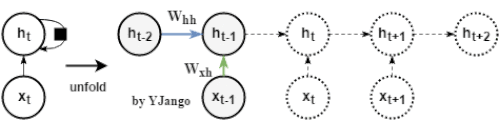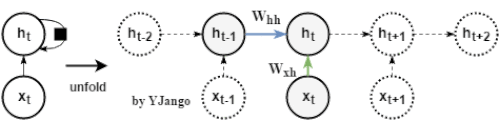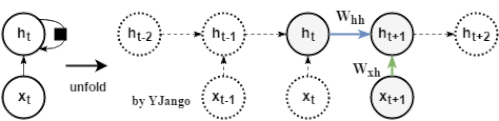
数学式子:

。
同样也由
经
的变化后的信息决定,
但这里多另一份信息:

,而该信息是从上一时刻的隐藏状态
经过一个不同的

变换后得出的。
注:
的形状是行为dim_input,列为dim_hidden_state,而
是一个行列都为dim_hidden_state的方阵。
学习参数:前馈网络需要3个时刻来帮助学习一次
,而递归网络可以用3个时刻来帮助学习3次
和
。换句话说:所有时刻的权重矩阵都是共享的。这是递归网络相对于前馈网络而言最为突出的优势。
递归神经网络是在时间结构上存在共享特性的神经网络变体。
时间结构共享是递归网络的核心中的核心。
下面就是对计算图的直观讲解。
结构:计算图所建立的只是一个网络框架。在编程时,并不会有任何实际值出现在框架中。所有权重和偏移都是框架中的一部分,初始时至少给定初始值才能形成框架。因此需要initialization初始化。
比喻:计算图就是一个管道。编写网络就是搭建一个管道结构。在投入实际使用前,不会有任何液体进入管道。而神经网络中的权重和偏移就是管道中的阀门,可以控制液体的流动强弱和方向。在神经网络的训练中,阀门会根据数据进行自我调节、更新。但是使用之前至少要给所有阀门一个初始的状态才能形成结构。用计算图的好处是它允许我们可以从任意一个节点处取出液体。
用法说明:
请类比管道构建来理解计算图的用法
计算图(graph):要组装的结构。由许多操作组成。
操作(ops):接受(流入)零个或多个输入(液体),返回(流出)零个或多个输出。
数据类型:主要分为张量(tensor)、变量(variable)和常量(constant)
张量:多维array或list(管道中的液体)
创建语句:
变量:在同一时刻对图中所有其他操作都保持静态的数据(管道中的阀门)
创建语句:
初始化语句:
更新语句:
常量:无需初始化的变量
创建语句:
会话:执行(launch)构建的计算图。可选择执行设备:单个电脑的CPU、GPU,或电脑分布式甚至手机。
创建语句:
执行操作:使用创建的会话执行操作
执行语句:
送值(feed):输入操作的输入值(输入液体)
语句:
取值(fetch):获取操作的输出值(得到液体)
语句:
更多内容参考官网文档
1.对车辆碰撞、驾驶行为分析方面论文汇总,并选择性的阅读了几篇。
2.学习深度学习相关知识,Python数据处理知识。
3.学习TensorFlow神经网络库,并搭建了开发环境。
一、深度学习简介
1.什么是深度学习
深度学习(Deep Learning)是机器学习的一种形式,概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
2.基本变换:层
神经网络是由一层一层构建的,那么每层究竟在做什么?数学式子:
,其中
是输入向量,
是输出向量,
是偏移向量,
是权重矩阵,
是激活函数。每一层仅仅是把输入
经过如此简单的操作得到
。
数学理解:通过如下5种对输入空间(输入向量的集合)的操作,完成 输入空间 —> 输出空间 的变换 (矩阵的行空间到列空间)。 注:用“空间”二字的原因是被分类的并不是单个事物,而是一类事物。空间是指这类事物所有个体的集合。
1. 升维/降维
2. 放大/缩小
3. 旋转
4. 平移
5. “弯曲” 这5种操作中,1,2,3的操作由
完成,4的操作是由
完成,5的操作则是由
来实现。
每层神经网络的数学理解:用线性变换跟随着非线性变化,将输入空间投向另一个空间。
线性可分视角:神经网络的学习就是学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投向线性可分/稀疏的空间去分类/回归。
增加节点数:增加维度,即增加线性转换能力。
增加层数:增加激活函数的次数,即增加非线性转换次数。
3.神经网络的训练
知道了神经网络的学习过程就是学习控制着空间变换方式(物质组成方式)的权重矩阵后,接下来的问题就是如何学习每一层的权重矩阵。
如何训练:
既然我们希望网络的输出尽可能的接近真正想要预测的值。那么就可以通过比较当前网络的预测值和我们真正想要的目标值,再根据两者的差异情况来更新每一层的权重矩阵(比如,如果网络的预测值高了,就调整权重让它预测低一些,不断调整,直到能够预测出目标值)。因此就需要先定义“如何比较预测值和目标值的差异”,这便是损失函数或目标函数(lossfunction or objective function),用于衡量预测值和目标值的差异的方程。loss function的输出值(loss)越高表示差异性越大。那神经网络的训练就变成了尽可能的缩小loss的过程。所用的方法是梯度下降(Gradient d
1322e
escent):通过使loss值向当前点对应梯度的反方向不断移动,来降低loss。一次移动多少是由学习速率(learning
rate)来控制的。
梯度下降的问题:
然而使用梯度下降训练神经网络拥有两个主要难题。
局部极小值
梯度下降寻找的是loss function的局部极小值,而我们想要全局最小值。如下图所示,我们希望loss值可以降低到右侧深蓝色的最低点,但loss有可能“卡”在左侧的局部极小值中。试图解决“卡在局部极小值”问题的方法分两大类:
调节步伐:调节学习速率,使每一次的更新“步伐”不同。常用方法有:
随机梯度下降(Stochastic Gradient Descent (SGD):每次只更新一个样本所计算的梯度
小批量梯度下降(Mini-batch gradient descent):每次更新若干样本所计算的梯度的平均值
动量(Momentum):不仅仅考虑当前样本所计算的梯度;Nesterov动量(Nesterov Momentum):Momentum的改进
Adagrad、RMSProp、Adadelta、Adam:这些方法都是训练过程中依照规则降低学习速率,部分也综合动量
优化起点:合理初始化权重(weights initialization)、预训练网络(pre-train),使网络获得一个较好的“起始点”,如最右侧的起始点就比最左侧的起始点要好。常用方法有:高斯分布初始权重(Gaussian distribution)、均匀分布初始权重(Uniform distribution)、Glorot 初始权重、He初始权、稀疏矩阵初始权重(sparse matrix)
梯度的计算
机器学习所处理的数据都是高维数据,该如何快速计算梯度、而不是以年来计算。 其次如何更新隐藏层的权重? 解决方法是:计算图:反向传播算法 这里的解释留给非常棒的ComputationalGraphs: Backpropagation 需要知道的是,反向传播算法是求梯度的一种方法。如同快速傅里叶变换(FFT)的贡献。 而计算图的概念又使梯度的计算更加合理方便。
基本流程图:
二、前馈神经网络
前馈神经网络(feedforward neural network),简称前馈网络,是人工神经网络的一种。在此种神经网络中,各神经元从输入层开始,接收前一级输入,并输出到下一级,直至输出层。整个网络中无反馈,可用一个有向无环图表示。前馈神经网络采用一种单向多层结构。其中每一层包含若干个神经元,同一层的神经元之间没有互相连接,层间信息的传送只沿一个方向进行。其中第一层称为输入层。最后一层为输出层.中间为隐含层,简称隐层。隐层可以是一层。也可以是多层。
网络结构:2维输入
1维输出
结构表达式:
正向传递:
(1)
用于表达随机变量
的值,
表示随机变量
的值,
是我们的神经网络模型,等号右侧是具体的表达。
损失函数:
该loss就是比较
和
中所有值的差别。
整体结构:左侧的图表示网络结构。绿色方框表示操作,也叫作层(layer)。该结构中,输入
经过hid_layer算出隐藏层的值
,再传递给out_layer,计算出预测值
,随后与真实值
进行比较,算出损失
,再从反向求导得出梯度后对每一层的
和
进行更新。
正向传递:如果放大hid_layer内部,从下向上,会看到
先用truncated_normal的方法进行了初始化,随后与输入
进行矩阵相乘,加上
,又经过了activation后,送给了用于计算
的out_layer中。而
的计算方式和
完全一致,但用的是不同的权重
和偏移
。最后将算出的预测值
与真实值
一同求出
反向传递:如果放大train的内部,再放大内部中的gradients,就可以看到框架是从
开始一步步反向求得各个层中
和
的梯度的。
权重更新:求出的各个层
和
的梯度,将会被用于更新对应的
和
,并用learning
rate控制一次更新多大。(beta1_power和beta2_power是Adam更新方法中的参数,目前只需要知道权重更新的核心是各自对应的梯度。)
三、循环神经网络(RNN)
前馈网络:window size为3帧的窗处理后的前馈网络
动态图:左侧是时间维度展开前,右侧是展开后(单位时刻实际工作的只有灰色部分。)。前馈网络的特点使不同时刻的预测完全是独立的。我们只能通过窗处理的方式让其照顾到前后相关性。数学式子:
,concat表示将向量并接成一个更大维度的向量。
学习参数:需要从大量的数据中学习
和
。
要学习各个时刻(3个)下所有维度(39维)的关系(39*3个),就需要很多数据。
递归网络:不再有window size的概念,而是time step
动态图:左侧是时间维度展开前,回路方式的表达方式,其中黑方框表示时间延迟。右侧展开后,可以看到当前时刻的并不仅仅取决于当前时刻的输入
,同时与上一时刻的
也相关。
数学式子:
。
同样也由
经
的变化后的信息决定,
但这里多另一份信息:
,而该信息是从上一时刻的隐藏状态
经过一个不同的
变换后得出的。
注:
的形状是行为dim_input,列为dim_hidden_state,而
是一个行列都为dim_hidden_state的方阵。
学习参数:前馈网络需要3个时刻来帮助学习一次
,而递归网络可以用3个时刻来帮助学习3次
和
。换句话说:所有时刻的权重矩阵都是共享的。这是递归网络相对于前馈网络而言最为突出的优势。
递归神经网络是在时间结构上存在共享特性的神经网络变体。
时间结构共享是递归网络的核心中的核心。
四、TensorFlow简介
目前主流的TensorFlow,用tensorflow这样工具的原因是:它允许我们用计算图(Computational Graphs)的方式建立网络。同时又可以非常方便的对网络进行操作。下面就是对计算图的直观讲解。
比喻说明:
结构:计算图所建立的只是一个网络框架。在编程时,并不会有任何实际值出现在框架中。所有权重和偏移都是框架中的一部分,初始时至少给定初始值才能形成框架。因此需要initialization初始化。比喻:计算图就是一个管道。编写网络就是搭建一个管道结构。在投入实际使用前,不会有任何液体进入管道。而神经网络中的权重和偏移就是管道中的阀门,可以控制液体的流动强弱和方向。在神经网络的训练中,阀门会根据数据进行自我调节、更新。但是使用之前至少要给所有阀门一个初始的状态才能形成结构。用计算图的好处是它允许我们可以从任意一个节点处取出液体。
用法说明:
请类比管道构建来理解计算图的用法
构造阶段(construction phase):组装计算图(管道)
计算图(graph):要组装的结构。由许多操作组成。操作(ops):接受(流入)零个或多个输入(液体),返回(流出)零个或多个输出。
数据类型:主要分为张量(tensor)、变量(variable)和常量(constant)
张量:多维array或list(管道中的液体)
创建语句:
tensor_name=tf.placeholder(type, shape, name)
变量:在同一时刻对图中所有其他操作都保持静态的数据(管道中的阀门)
创建语句:
name_variable = tf.Variable(value, name)
初始化语句:
#个别变量 init_op=variable.initializer() #所有变量 init_op=tf.initialize_all_variables() #注意:init_op的类型是操作(ops),加载之前并不执行
更新语句:
update_op=tf.assign(variable to be updated, new_value)
常量:无需初始化的变量
创建语句:
name_constant=tf.constant(value)
执行阶段(execution phase):使用计算图(获取液体)
会话:执行(launch)构建的计算图。可选择执行设备:单个电脑的CPU、GPU,或电脑分布式甚至手机。创建语句:
#常规 sess = tf.Session() #交互 sess = tf.InteractiveSession() #交互方式可用tensor.eval()获取值,ops.run()执行操作 #关闭 sess.close()
执行操作:使用创建的会话执行操作
执行语句:
sess.run(op)
送值(feed):输入操作的输入值(输入液体)
语句:
sess.run([output], feed_dict={input1:value1, input2:value1})取值(fetch):获取操作的输出值(得到液体)
语句:
#单值获取 sess.run(one op) #多值获取 sess.run([a list of ops])
更多内容参考官网文档

相关文章推荐
- Deep Learning(深度学习)学习笔记整理系列
- Deep Learning(深度学习)学习笔记整理系列
- Deep Learning(深度学习)学习笔记整理系列之(三)
- 深度学习笔记 目标函数的总结与整理
- Deep Learning(深度学习)学习笔记整理系列之(四)
- Deep Learning(深度学习)学习笔记整理系列之(三)
- Deep Learning(深度学习)学习笔记整理系列之LeNet-5卷积参数个人理解
- Deep Learning(深度学习)学习笔记整理系列之(二)
- Deep Learning(深度学习)学习笔记整理系列之(七)
- Deep Learning(深度学习)学习笔记整理系列之(八)
- Deep Learning(深度学习)学习笔记整理系列之(八)
- Deep Learning(深度学习)学习笔记整理系列
- Deep Learning(深度学习)学习笔记整理系列之(三)
- 深度学习数学基础笔记整理(二)
- Deep Learning(深度学习)学习笔记整理
- Deep Learning(深度学习)学习笔记整理系列之(八)
- 【转】Deep Learning(深度学习)学习笔记整理系列之(一)
- Deep Learning(深度学习)学习笔记整理系列之(八)
- Deep Learning(深度学习)学习笔记整理系列之(七)
- Deep Learning(深度学习)学习笔记整理系列之(六)