当训练数据集很小的时候怎么办?
2017-09-27 18:00
211 查看
Many technology companies now have teams of smart data-scientists, versed in big-data infrastructure tools and machine learning algorithms, but every now and then, a data set with very few
data points turns up and none of these algorithms seem to be working properly anymore. What the hell is happening? What can you do about it?
documents, users, files, queries, songs, images, etc. Things that are in the thousands, hundreds of thousands, millions or even billions. The infrastructure, tools, and algorithms to deal with these kinds of data sets have been evolving very quickly and improving
continuously during the last decade or so. And most data scientists and machine learning practitioners have gained experience is such situations, have grown accustomed to the appropriate algorithms, and gained good intuitions about the usual trade-offs (bias-variance,
flexibility-stability, hand-crafted features vs. feature learning, etc.). But small data sets still arise in the wild every now and then, and often, they are trickier to handle, require a different set of algorithms and a different set of skills. Small data
sets arise is several situations:
Enterprise Solutions: when you try to make a solution for an enterprise of a relatively limited members instead
of a single solution for thousands of users, or if you are making a solution which companies instead of individuals are the focus of the experience
Time Series: Time is in short supply! Esp. in comparison with users, queries, sessions, documents, etc. This
obviously depends on the time unit or sampling rate, but it’s not always easy to increase the sampling rate effectively, and if your ground truth is a daily number, then you have one data point for each day.
Aggregate modeling of states, countries, sports teams, or any situation where the population itself is limited
(or sampling is really expensive).
Modeling of rare phenomena of any kind: Earthquakes, floods, etc.
Over-fitting becomes much harder to avoid
You don’t only over-fit to your training data, but sometimes you over-fit to your validation set as well.
Outliers become much more dangerous.
Noise in general becomes a real issue, be it in your target variable or in some of the features.
I’m not kidding! Statisticians are the original data scientists. The field of statistics was developed when data was much harder to come by, and as such was very aware of small-sample problems.
Statistical tests, parametric models, bootstrapping, and other useful mathematical tools are the domain of classical statistics, not modern machine learning. Lacking a good general-purpose statistician, get a marine-biologist, a zoologist, a psychologist,
or anyone who was trained in a domain that deals with small sample experiments. The closer to your domain the better. If you don’t want to hire a statistician full time on your team, make it a temporary consultation. But hiring a classically trained statistician
could be a very good investment.
2- Stick to simple models
More precisely: stick to a limited set of hypotheses. One way to look at predictive modeling is as a search problem. From an initial set of possible models, which is the most appropriate model
to fit our data? In a way, each data point we use for fitting down-votes all models that make it unlikely, or up-vote models that agree with it. When you have heaps of data, you can afford to explore huge sets of models/hypotheses effectively and end up with
one that is suitable. When you don’t have so many data points to begin with, you need to start from a fairly small set of possible hypotheses (e.g. the set of all linear models with 3 non-zero weights, the set of decision trees with depth <= 4, the set of
histograms with 10 equally-spaced bins). This means that you rule out complex hypotheses like those that deal with non-linearity or feature interactions. This also means that you can’t afford to fit models with too many degrees of freedom (too many weights
or parameters). Whenever appropriate, use strong assumptions (e.g. no negative weights, no interaction between features, specific distributions, etc.) to restrict the space of possible hypotheses.

Any crazy model can fit this single data point (drawn from distribution around yellow curve)

As we have more points, less and less models can reasonably explain them together.
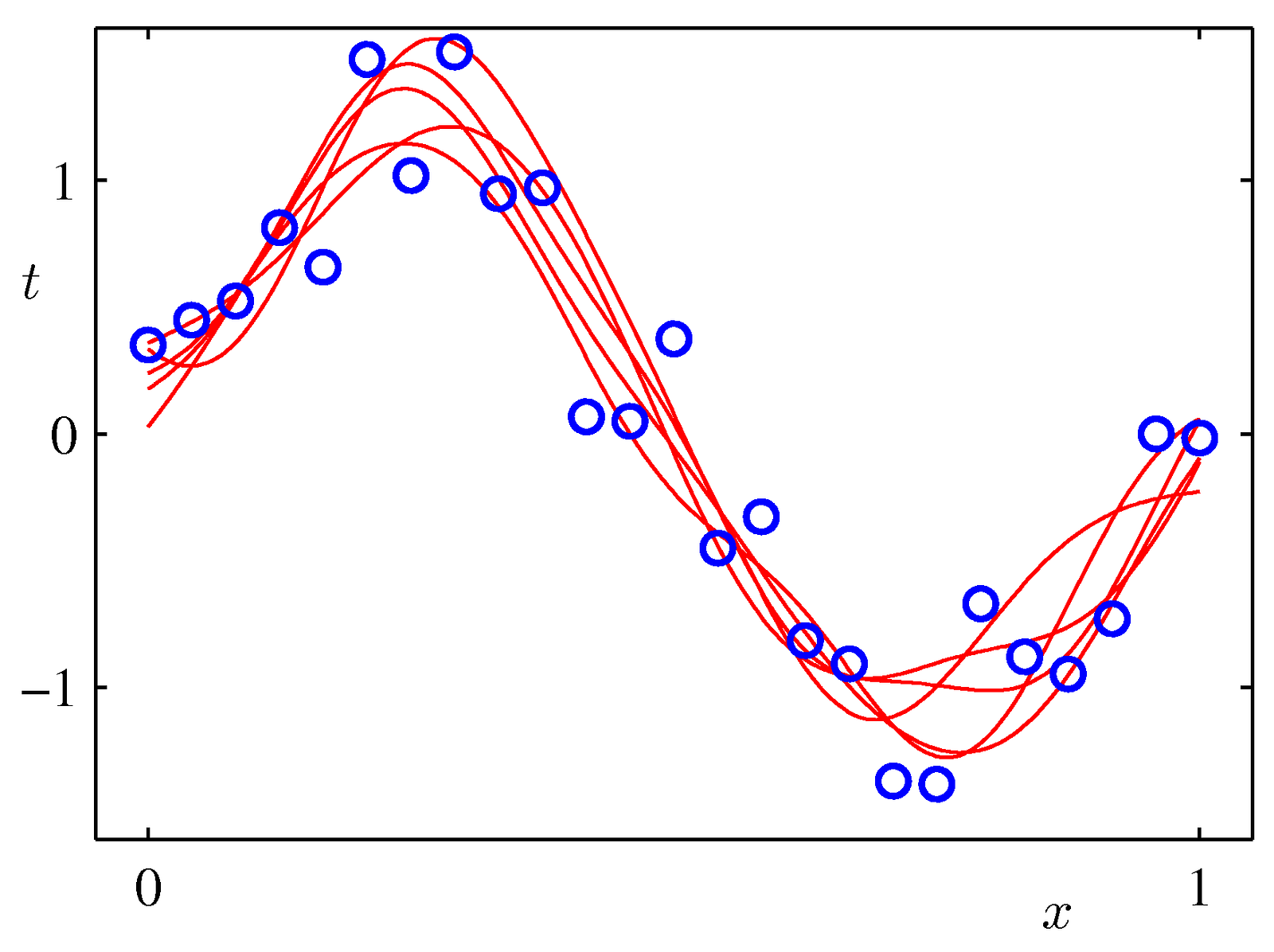
The figures were taken from Chris Bishop’s book Pattern Recognition
and Machine Learning
3- Pool data when possible
Are you building a personalized spam filter? Try building it on top of a universal model trained for all users. Are you modeling GDP for a specific country? Try fitting your models on GDP
for all countries for which you can get data, maybe using importance sampling to emphasize the country you’re interested in. Are you trying to predict the eruptions of a specific volcano? … you get the idea.
4- Limit Experimentation
Don’t over-use your validation set. If you try too many different techniques, and use a hold-out set to compare between them, be aware of the statistical power of the results you are getting,
and be aware that the performance you are getting on this set is not a good estimator for out of sample performance.
5- Do clean up your data
With small data sets, noise and outliers are especially troublesome. Cleaning up your data could be crucial here to get sensible models. Alternatively you can restrict your modeling to techniques
especially designed to be robust to outliers. (e.g. Quantile Regression)
6- Do perform feature selection
I am not a big fan of explicit feature selection. I typically go for regularization and model averaging (next two points) to avoid over-fitting. But if the data is truly limiting, sometimes
explicit feature selection is essential. Wherever possible, use domain expertise to do feature selection or elimination, as brute force approaches (e.g. all subsets or greedy forward selection) are as likely to cause over-fitting as including all features.
7- Do use Regularization
Regularization is an almost-magical solution that constraints model fitting and reduces the effective degrees of freedom without reducing the actual number of parameters in the model. L1
regularization produces models with fewer non-zero parameters, effectively performing implicit feature selection, which could be desirable for explainability of performance in production, while L2
regularization produces models with more conservative (closer to zero) parameters and is effectively similar to having strong zero-centered priors for the parameters (in the Bayesian world). L2 is usually better for prediction accuracy than L1.
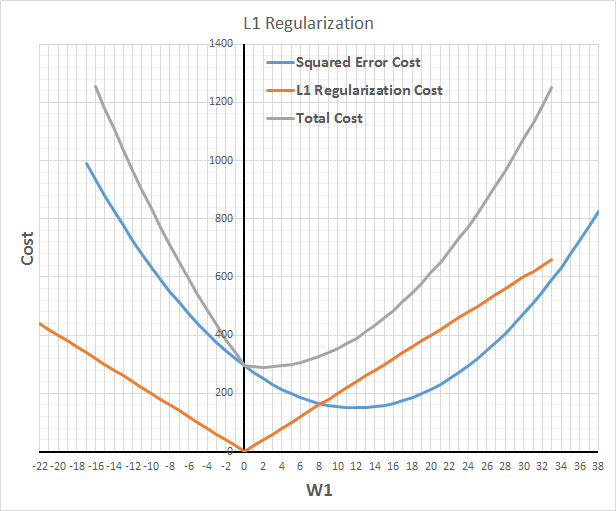
L1 Regularization can push most model parameters to zero
8- Do use Model Averaging
Model averaging has similar effects to regularization is that it reduces variance and enhances generalization, but it is a generic technique that can be used with any type of models or even
with heterogeneous sets of models. The downside here is that you end up with huge collections of models, which could be slow to evaluate or awkward to deploy to a production system. Two very reasonable forms of model averaging are Bagging and Bayesian model
averaging.

Each of the red curves is a model fitted on a few data points
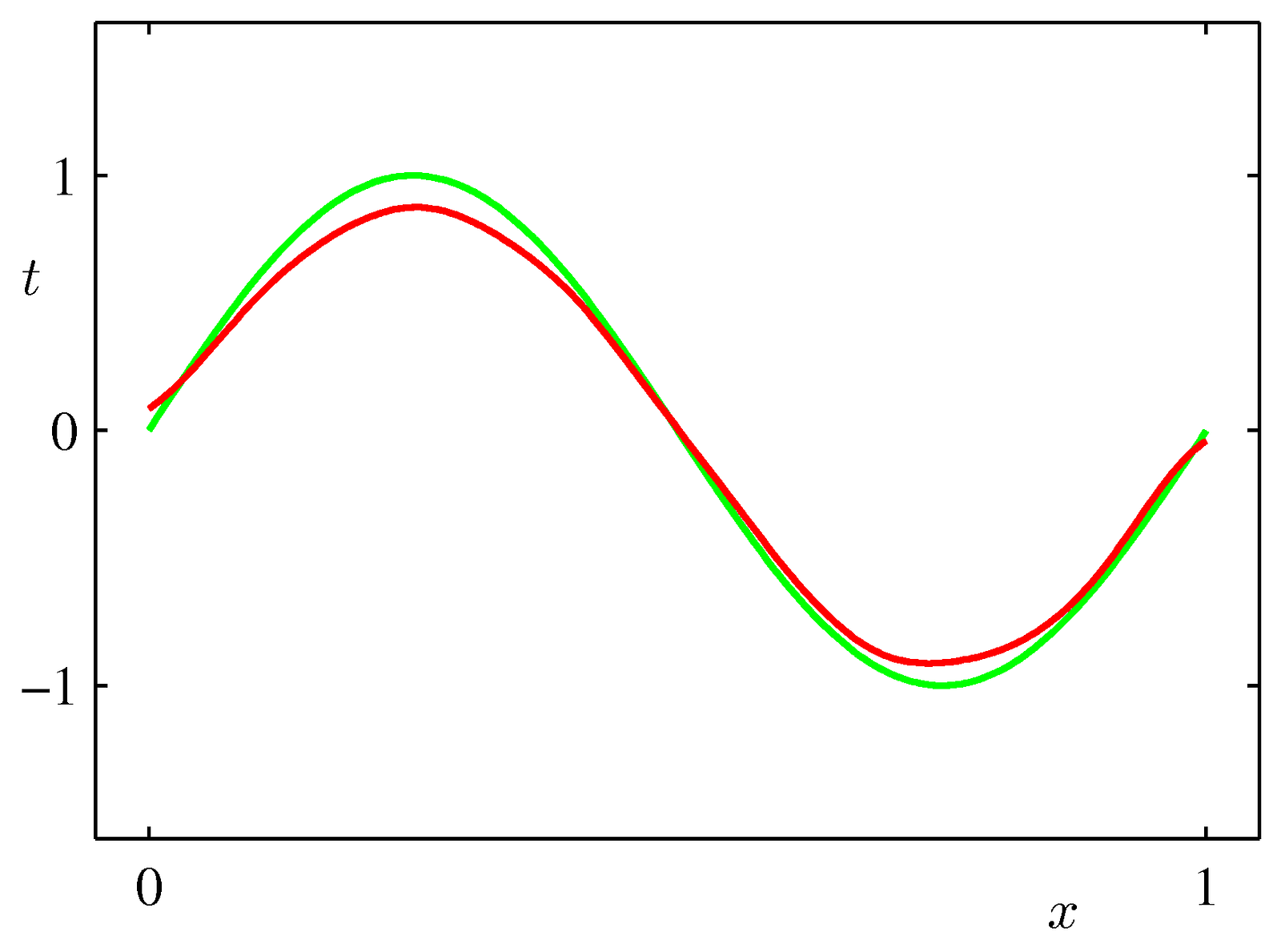
But averaging all these high variance models gets us a smooth output that is remarkably close to the original distribution Pattern
Recognition and Machine Learning
9- Try Bayesian Modeling and Model Averaging
Again, not a favorite technique of mine, but Bayesian inference may be well suited for dealing with smaller data sets, especially if you can use domain expertise to construct sensible priors.
10- Prefer Confidence Intervals to Point Estimates
It is usually a good idea to get an estimate of confidence in your prediction in addition to producing the prediction itself. For regression analysis this usually takes the form of predicting
a range of values that is calibrated to cover the true value 95% of the time or in the case of classification it could be just a matter of producing class probabilities. This becomes more crucial with small data sets as it becomes more likely that certain
regions in your feature space are less represented than others. Model averaging as referred to in the previous two points allows us to do that pretty easily in a generic way for regression, classification and density estimation. It is also useful to do that
when evaluating your models. Producing confidence intervals on the metrics you are using to compare model performance is likely to save you from jumping to many wrong conclusions.

Parts of the feature space are likely to be less covered by your data and prediction confidence within these regions should reflect that

Bootstrapped performance charts from ROCR
Most figures used in this post were taken from the book “Pattern Recognition and
Machine Learning” by Christopher Bishop.
data points turns up and none of these algorithms seem to be working properly anymore. What the hell is happening? What can you do about it?
Where do small data come from?
Most data science, relevance, and machine learning activities in technology companies have been focused around “Big Data” and scenarios with huge data sets. Sets where the rows representdocuments, users, files, queries, songs, images, etc. Things that are in the thousands, hundreds of thousands, millions or even billions. The infrastructure, tools, and algorithms to deal with these kinds of data sets have been evolving very quickly and improving
continuously during the last decade or so. And most data scientists and machine learning practitioners have gained experience is such situations, have grown accustomed to the appropriate algorithms, and gained good intuitions about the usual trade-offs (bias-variance,
flexibility-stability, hand-crafted features vs. feature learning, etc.). But small data sets still arise in the wild every now and then, and often, they are trickier to handle, require a different set of algorithms and a different set of skills. Small data
sets arise is several situations:
Enterprise Solutions: when you try to make a solution for an enterprise of a relatively limited members instead
of a single solution for thousands of users, or if you are making a solution which companies instead of individuals are the focus of the experience
Time Series: Time is in short supply! Esp. in comparison with users, queries, sessions, documents, etc. This
obviously depends on the time unit or sampling rate, but it’s not always easy to increase the sampling rate effectively, and if your ground truth is a daily number, then you have one data point for each day.
Aggregate modeling of states, countries, sports teams, or any situation where the population itself is limited
(or sampling is really expensive).
Modeling of rare phenomena of any kind: Earthquakes, floods, etc.
Small Data problems
Problems of small-data are numerous, but mainly revolve around high variance:Over-fitting becomes much harder to avoid
You don’t only over-fit to your training data, but sometimes you over-fit to your validation set as well.
Outliers become much more dangerous.
Noise in general becomes a real issue, be it in your target variable or in some of the features.
So what to do in these situation?
1- Hire a statisticianI’m not kidding! Statisticians are the original data scientists. The field of statistics was developed when data was much harder to come by, and as such was very aware of small-sample problems.
Statistical tests, parametric models, bootstrapping, and other useful mathematical tools are the domain of classical statistics, not modern machine learning. Lacking a good general-purpose statistician, get a marine-biologist, a zoologist, a psychologist,
or anyone who was trained in a domain that deals with small sample experiments. The closer to your domain the better. If you don’t want to hire a statistician full time on your team, make it a temporary consultation. But hiring a classically trained statistician
could be a very good investment.
2- Stick to simple models
More precisely: stick to a limited set of hypotheses. One way to look at predictive modeling is as a search problem. From an initial set of possible models, which is the most appropriate model
to fit our data? In a way, each data point we use for fitting down-votes all models that make it unlikely, or up-vote models that agree with it. When you have heaps of data, you can afford to explore huge sets of models/hypotheses effectively and end up with
one that is suitable. When you don’t have so many data points to begin with, you need to start from a fairly small set of possible hypotheses (e.g. the set of all linear models with 3 non-zero weights, the set of decision trees with depth <= 4, the set of
histograms with 10 equally-spaced bins). This means that you rule out complex hypotheses like those that deal with non-linearity or feature interactions. This also means that you can’t afford to fit models with too many degrees of freedom (too many weights
or parameters). Whenever appropriate, use strong assumptions (e.g. no negative weights, no interaction between features, specific distributions, etc.) to restrict the space of possible hypotheses.
Any crazy model can fit this single data point (drawn from distribution around yellow curve)
As we have more points, less and less models can reasonably explain them together.
The figures were taken from Chris Bishop’s book Pattern Recognition
and Machine Learning
3- Pool data when possible
Are you building a personalized spam filter? Try building it on top of a universal model trained for all users. Are you modeling GDP for a specific country? Try fitting your models on GDP
for all countries for which you can get data, maybe using importance sampling to emphasize the country you’re interested in. Are you trying to predict the eruptions of a specific volcano? … you get the idea.
4- Limit Experimentation
Don’t over-use your validation set. If you try too many different techniques, and use a hold-out set to compare between them, be aware of the statistical power of the results you are getting,
and be aware that the performance you are getting on this set is not a good estimator for out of sample performance.
5- Do clean up your data
With small data sets, noise and outliers are especially troublesome. Cleaning up your data could be crucial here to get sensible models. Alternatively you can restrict your modeling to techniques
especially designed to be robust to outliers. (e.g. Quantile Regression)
6- Do perform feature selection
I am not a big fan of explicit feature selection. I typically go for regularization and model averaging (next two points) to avoid over-fitting. But if the data is truly limiting, sometimes
explicit feature selection is essential. Wherever possible, use domain expertise to do feature selection or elimination, as brute force approaches (e.g. all subsets or greedy forward selection) are as likely to cause over-fitting as including all features.
7- Do use Regularization
Regularization is an almost-magical solution that constraints model fitting and reduces the effective degrees of freedom without reducing the actual number of parameters in the model. L1
regularization produces models with fewer non-zero parameters, effectively performing implicit feature selection, which could be desirable for explainability of performance in production, while L2
regularization produces models with more conservative (closer to zero) parameters and is effectively similar to having strong zero-centered priors for the parameters (in the Bayesian world). L2 is usually better for prediction accuracy than L1.
L1 Regularization can push most model parameters to zero
8- Do use Model Averaging
Model averaging has similar effects to regularization is that it reduces variance and enhances generalization, but it is a generic technique that can be used with any type of models or even
with heterogeneous sets of models. The downside here is that you end up with huge collections of models, which could be slow to evaluate or awkward to deploy to a production system. Two very reasonable forms of model averaging are Bagging and Bayesian model
averaging.
Each of the red curves is a model fitted on a few data points
But averaging all these high variance models gets us a smooth output that is remarkably close to the original distribution Pattern
Recognition and Machine Learning
9- Try Bayesian Modeling and Model Averaging
Again, not a favorite technique of mine, but Bayesian inference may be well suited for dealing with smaller data sets, especially if you can use domain expertise to construct sensible priors.
10- Prefer Confidence Intervals to Point Estimates
It is usually a good idea to get an estimate of confidence in your prediction in addition to producing the prediction itself. For regression analysis this usually takes the form of predicting
a range of values that is calibrated to cover the true value 95% of the time or in the case of classification it could be just a matter of producing class probabilities. This becomes more crucial with small data sets as it becomes more likely that certain
regions in your feature space are less represented than others. Model averaging as referred to in the previous two points allows us to do that pretty easily in a generic way for regression, classification and density estimation. It is also useful to do that
when evaluating your models. Producing confidence intervals on the metrics you are using to compare model performance is likely to save you from jumping to many wrong conclusions.
Parts of the feature space are likely to be less covered by your data and prediction confidence within these regions should reflect that
Bootstrapped performance charts from ROCR
Summary
This could be a somewhat long list of things to do or try, but they all revolve around three main themes: constrained modeling, smoothing and quantification of uncertainty.Most figures used in this post were taken from the book “Pattern Recognition and
Machine Learning” by Christopher Bishop.

相关文章推荐
- ubuntu下caffe清理空间&caffe在训练的时候loss不继续下降了应该怎么做
- 训练深度学习网络时候,出现Nan是什么原因,怎么才能避免?
- [置顶] SVM训练时候样本不均衡怎么设置惩罚项
- Java练笔:一个类作为另一个类的参数调用。顺带训练数据在栈和堆的走向。思考若用C++写,delete应该怎么写
- IOS调试技巧:当程序崩溃的时候怎么办 iphone IOS
- Fast RCNN 训练自己的数据集(3训练和检测)
- 分类中的训练数据集不均衡问题处理
- Tomcat启用80/443端口的时候提示“java.net.BindException: Permission denied:80”,怎么解决?
- faster rcnn训练自己的数据集demo和训练过程error总结
- iar 新安装环境的时候找不到仿真器怎么办?
- 当程序崩溃的时候怎么办 Part-2
- 神经网络中训练数据集、验证数据集和测试数据集的区别
- 当程序崩溃的时候怎么办 part-1
- yolo v2 训练自己数据集遇到的问题
- 在制图的时候,怎么修改图纸的背景颜色?
- ListView 数据为空的时候提示怎么写?
- 深度学习(十四):详解Matconvnet使用imagenet模型训练自己的数据集
- IOS调试技巧:当程序崩溃的时候怎么办 iphone IOS
- eclipse Dug 的时候,出现Source not found.怎么处理
- UITableView的性能优化? 滑动的时候有种卡的感觉是为什么?怎么解决?