微博爬虫“免登录”技巧详解及 Java 实现(业余草的博客)
2017-09-27 10:21
1006 查看
一、微博一定要登录才能抓取?
目前,对于微博的爬虫,大部分是基于模拟微博账号登录的方式实现的,这种方式如果真的运营起来,实际上是一件非常头疼痛苦的事,你可能每天都过得提心吊胆,生怕新浪爸爸把你的那些账号给封了,而且现在随着实名制的落地,获得账号的渠道估计也会变得越来越少。但是日子还得继续,在如此艰难的条件下,为了生存爬虫们必须寻求进化。好在上帝关门的同时会随手开窗,微博在其他诸如头条,一点等这类新媒体平台的冲击之下,逐步放开了信息流的查看权限。现在的微博即便在不登录的状态下,依然可以看到很多微博信息流,而我们的落脚点就在这里。
本文详细介绍如何获取相关的Cookie并重新封装Httpclient达到免登录的目的,以支持微博上的各项数据抓取任务。下面就从微博首页http://weibo.com开始。
二、准备工作
准备工作很简单,一个现代浏览器(你知道我为什么会写”现代”两个字),以及httpclient(我用的版本是4.5.3)跟登录爬虫一样,免登录爬虫也是需要装载Cookie。这里的Cookie是用来标明游客身份,利用这个Cookie就可以在微博平台中访问那些允许访问的内容了。
这里我们可以使用浏览器的network工具来看一下,请求http://weibo.com之后服务器都返回哪些东西,当然事先清空一下浏览器的缓存。
我的博客:CODE大全:www.codedq.net;业余草:www.xttblog.com;爱分享:www.ndislwf.com或ifxvn.com。
不出意外,应该可以看到下图中的内容
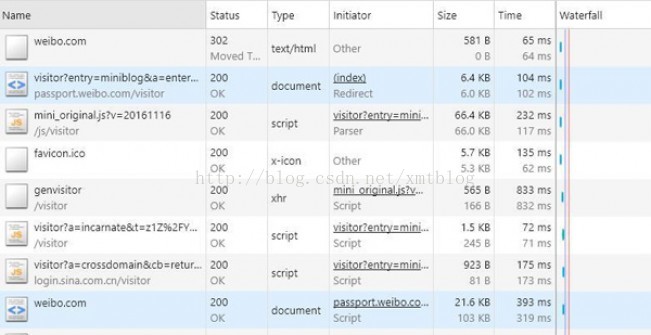
第1次请求weibo.com的时候,其状态为302重定向,也就是说这时并没有真正地开始加载页面,而最后一个请求weibo.com的状态为200,表示了请求成功,对比两次请求的header:
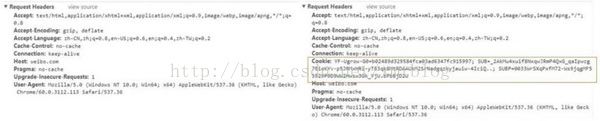
明显地,中间的这些过程给客户端加载了各种Cookie,从而使得可以顺利访问页面,接下来我们逐个进行分析。
三、抽丝剥茧
第2个请求是https://passport.weibo.com/vi...……,各位可以把这个url复制出来,用httpclient单独访问一下这个url,可以看到返回的是一个html页面,里面有一大段Javascript脚本,另外头部还引用一个JS文件mini_original.js,也就是第3个请求。脚本的功能比较多,就不一一叙述了,简单来说就是微博访问的入口控制,而值得我们注意的是其中的一个function:// 为用户赋予访客身份 。
var incarnate = function (tid, where, conficence) {
var gen_conf = "";
var from = "weibo";
var incarnate_intr = window.location.protocol
+ "//" + window.location.host + "/visitor/visitor?a=incarnate&t="
+ encodeURIComponent(tid) + "&w=" + encodeURIComponent(where)
+ "&c=" + encodeURIComponent(conficence) + "&gc="
+ encodeURIComponent(gen_conf) + "&cb=cross_domain&from="
+ from + "&_rand=" + Math.random();
url.l(incarnate_intr);
}; 我的博客:CODE大全:www.codedq.net;业余草:www.xttblog.com;爱分享:www.ndislwf.com或ifxvn.com。
这里是为请求者赋予一个访客身份,而控制跳转的链接也是由一些参数拼接起来的,也就是上图中第6个请求。所以下面的工作就是获得这3个参数:tid,w(where),c(conficence,从下文来看应为confidence,大概是新浪工程师的手误)。继续阅读源码,可以看到该function是tid.get方法的回调函数,而这个tid则是定义在那个mini_original.js中的一个对象,其部分源码为:
var tid = {
key: 'tid',
value: '',
recover: 0,
confidence: '',
postInterface: postUrl,
fpCollectInterface: sendUrl,
callbackStack: [],
init: function () {
tid.get();
},
runstack: function () {
var f;
while (f = tid.callbackStack.pop()) {
f(tid.value, tid.recover, tid.confidence);//注意这里,对应上述的3个参数
}
},
get: function (callback) {
callback = callback || function () {
};
tid.callbackStack.push(callback);
if (tid.value) {
return tid.runstack();
}
Store.DB.get(tid.key, function (v) {
if (!v) {
tid.getTidFromServer();
} else {
……
}
});
},
……
}
……
getTidFromServer: function () {
tid.getTidFromServer = function () {
};
if (window.use_fp) {
getFp(function (data) {
util.postData(window.location.protocol + '//'
+ window.location.host + '/' + tid.postInterface, "cb=gen_callback&fp="
+ encodeURIComponent(data), function (res) {
if (res) {
eval(res);
}
});
});
} else {
util.postData(window.location.protocol + '//'
+ window.location.host + '/'
+ tid.postInterface, "cb=gen_callback", function (res) {
if (res) {
eval(res);
}
});
}
},
……
//获得参数
window.gen_callback = function (fp) {
var value = false, confidence;
if (fp) {
if (fp.retcode == 20000000) {
confidence = typeof(fp.data.confidence) != 'undefined' ? '000'
+ fp.data.confidence : '100';
tid.recover = fp.data.new_tid ? 3 : 2;
tid.confidence = confidence = confidence.substring(confidence.length - 3);
value = fp.data.tid;
Store.DB.set(tid.key, value + '__' + confidence);
}
}
tid.value = value;
tid.runstack();
}; 我的博客:CODE大全:www.codedq.net;业余草:www.xttblog.com;爱分享:www.ndislwf.com或ifxvn.com。
显然,tid.runstack()是真正执行回调函数的地方,这里就能看到传入的3个参数。在get方法中,当cookie为空时,tid会调用getTidFromServer,这时就产生了第5个请求https://passport.weibo.com/vi...,它需要两个参数cb和fp,其参数值可以作为常量:

该请求的结果返回一串json
{
"msg": "succ",
"data": {
"new_tid": false,
"confidence": 95,
"tid": "kIRvLolhrCR5iSCc80tWqDYmwBvlRVlnY2+yvCQ1VVA="
},
"retcode": 20000000
}我的博客:CODE大全:www.codedq.net;业余草:www.xttblog.com;爱分享:www.ndislwf.com或ifxvn.com。
其中就包含了tid和confidence,这个confidence,我猜大概是推测客户端是否真实的一个置信度,不一定出现,根据window.gen_callback方法,不出现时默认为100,另外当new_tid为真时参数where等于3,否则等于2。
此时3个参数已经全部获得,现在就可以用httpclient发起上面第6个请求,返回得到另一串json:
{
"msg": "succ",
"data": {
"sub": "_2AkMu428tf8NxqwJRmPAcxWzmZYh_zQjEieKYv572JRMxHRl-yT83qnMGtRCnhyR4ezQQZQrBRO3gVMwM5ZB2hQ..",
"subp": "0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWU2MgYnITksS2awP.AX-DQ"
},
"retcode": 20000000
}我的博客:CODE大全:www.codedq.net;业余草:www.xttblog.com;爱分享:www.ndislwf.com或ifxvn.com。参考最后请求weibo.com的header,这里的sub和subp就是最终要获取的cookie值。大家或许有一个小疑问,第一个Cookie怎么来的,没用吗?是的,这个Cookie是第一次访问weibo.com产生的,经过测试可以不用装载。

最后我们用上面两个Cookie装载到HttpClient中请求一次weibo.com,就可以获得完整的html页面了,下面就是见证奇迹的时刻:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="initial-scale=1,minimum-scale=1" />
<meta content="随时随地发现新鲜事!微博带你欣赏世界上每一个精彩瞬间,了解每一个幕后故事。
分享你想表达的,让全世界都能听到你的心声!" name="description" />
<link rel="mask-icon" sizes="any" href="//img.t.sinajs.cn/t6/style/images/apple/wbfont.svg" color="black" />
<link rel="shortcut icon" type="image/x-icon" href="/favicon.ico" />
<script type="text/javascript">
try{document.execCommand("BackgroundImageCache", false, true);}catch(e){}
</script>
<title>微博-随时随地发现新鲜事</title>
<link href="//img.t.sinajs.cn/t6/style/css/module/base/frame.css?version=6c9bf6ab3b33391f"
type="text/css" rel="stylesheet" charset="utf-8" />
<link href="//img.t.sinajs.cn/t6/style/css/pages/growth/login_v5.css?version=6c9bf6ab3b33391f"
type="text/css" rel="stylesheet" charset="utf-8">
<link href="//img.t.sinajs.cn/t6/skin/default/skin.css?version=6c9bf6ab3b33391f" type="text/css"
rel="stylesheet" id="skin_style" />
<script type="text/javascript">
var $CONFIG = {};
$CONFIG['islogin'] = '0';
$CONFIG['version'] = '6c9bf6ab3b33391f';
$CONFIG['timeDiff'] = (new Date() - 1505746970000);
$CONFIG['lang'] = 'zh-cn';
$CONFIG['jsPath'] = '//js.t.sinajs.cn/t5/';
$CONFIG['cssPath'] = '//img.t.sinajs.cn/t5/';
$CONFIG['imgPath'] = '//img.t.sinajs.cn/t5/';
$CONFIG['servertime'] = 1505746970;
$CONFIG['location']='login';
$CONFIG['bigpipe']='false';
$CONFIG['bpType']='login';
$CONFIG['mJsPath'] = ['//js{n}.t.sinajs.cn/t5/', 1, 2];
$CONFIG['mCssPath'] = ['//img{n}.t.sinajs.cn/t5/', 1, 2];
$CONFIG['redirect'] = '';
$CONFIG['vid']='1008997495870';
</script>
<style>#js_style_css_module_global_WB_outframe{height:42px;}</style>
</head>
…… 我的博客:CODE大全:www.codedq.net;业余草:www.xttblog.com;爱分享:www.ndislwf.com或ifxvn.com。
如果之前有微博爬虫开发经验的小伙伴,看到这里,一定能想出来很多玩法了吧。
四、代码实现
下面附上我的源码,通过上面的详细介绍,应该已经比较好理解,因此这里就简单地说明一下:我把Cookie获取的过程做成了一个静态内部类,其中需要发起2次请求,一次是genvisitor获得3个参数,另一次是incarnate获得Cookie值;
如果Cookie获取失败,会调用HttpClientInstance.changeProxy来改变代理IP,然后重新获取,直到获取成功为止;
在使用时,出现了IP被封或无法正常获取页面等异常情况,外部可以通过调用cookieReset方法,重新获取一个新的Cookie。这里还是要声明一下,科学地使用爬虫,维护世界和平是程序员的基本素养;
虽然加了一些锁的控制,但是还未在高并发场景实测过,不能保证百分百线程安全,如使用下面的代码,请根据需要自行修改,如有问题也请大神们及时指出,拜谢!
HttpClientInstance是我用单例模式重新封装的httpclient,对于每个传进来的请求重新包装了一层RequestConfig,并且使用了代理IP;
不是所有的微博页面都可以抓取得到,但是博文,评论,转发等基本的数据还是没有问题的;
后续我也会把代码push到github上,请大家支持,谢谢!
import com.fullstackyang.httpclient.HttpClientInstance;
import com.fullstackyang.httpclient.HttpRequestUtils;
import com.google.common.base.Strings;
import com.google.common.collect.Maps;
import com.google.common.net.HttpHeaders;
import lombok.NoArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.json.JSONObject;
import java.io.UnsupportedEncodingException;
import java.math.BigDecimal;
import java.net.URLEncoder;
import java.util.Map;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* 微博免登陆请求客户端
*
* @author fullstackyang
*/
@Slf4j
public class WeiboClient {
private static CookieFetcher cookieFetcher = new CookieFetcher();
private volatile String cookie;
public WeiboClient() {
this.cookie = cookieFetcher.getCookie();
}
private static Lock lock = new ReentrantLock();
public void cookieReset() {
if (lock.tryLock()) {
try {
HttpClientInstance.instance().changeProxy();
this.cookie = cookieFetcher.getCookie();
log.info("cookie :" + cookie);
} finally {
lock.unlock();
}
}
}
/**
* get方法,获取微博平台的其他页面
* @param url
* @return
*/
public String get(String url) {
if (Strings.isNullOrEmpty(url))
return "";
while (true) {
HttpGet httpGet = new HttpGet(url);
httpGet.addHeader(HttpHeaders.COOKIE, cookie);
httpGet.addHeader(HttpHeaders.HOST, "weibo.com");
httpGet.addHeader("Upgrade-Insecure-Requests", "1");
httpGet.setConfig(RequestConfig.custom().setSocketTimeout(3000)
.setConnectTimeout(3000).setConnectionRequestTimeout(3000).build());
String html = HttpClientInstance.instance().tryExecute(httpGet, null, null);
if (html == null)
cookieReset();
else return html;
}
}
/**
* 获取访问微博时必需的Cookie
*/
@NoArgsConstructor
static class CookieFetcher {
static final String PASSPORT_URL = "https://passport.weibo.com/visitor/visitor?entry="
+"miniblog&a=enter&url=http://weibo.com/?category=2"
+ "&domain=.weibo.com&ua=php-sso_sdk_client-0.6.23";
static final String GEN_VISITOR_URL = "https://passport.weibo.com/visitor/genvisitor";
static final String VISITOR_URL = "https://passport.weibo.com/visitor/visitor?a=incarnate";
private String getCookie() {
Map<String, String> map;
while (true) {
map = getCookieParam();
if (map.containsKey("SUB") && map.containsKey("SUBP") &&
StringUtils.isNoneEmpty(map.get("SUB"), map.get("SUBP")))
break;
HttpClientInstance.instance().changeProxy();
}
return " YF-Page-G0=" + "; _s_tentry=-; SUB=" + map.get("SUB") + "; SUBP=" + map.get("SUBP");
}
private Map<String, String> getCookieParam() {
String time = System.currentTimeMillis() + "";
time = time.substring(0, 9) + "." + time.substring(9, 13);
String passporturl = PASSPORT_URL + "&_rand=" + time;
String tid = "";
String c = "";
String w = "";
{
String str = postGenvisitor(passporturl);
if (str.contains("\"retcode\":20000000")) {
JSONObject jsonObject = new JSONObject(str).getJSONObject("data");
tid = jsonObject.optString("tid");
try {
tid = URLEncoder.encode(tid, "utf-8");
} catch (UnsupportedEncodingException e) {
}
c = jsonObject.has("confidence") ? "000" + jsonObject.getInt("confidence") : "100";
w = jsonObject.optBoolean("new_tid") ? "3" : "2";
}
}
String s = "";
String sp = "";
{
if (StringUtils.isNoneEmpty(tid, w, c)) {
String str = getVisitor(tid, w, c, passporturl);
str = str.substring(str.indexOf("(") + 1, str.indexOf(")"));
if (str.contains("\"retcode\":20000000")) {
System.out.println(new JSONObject(str).toString(2));
JSONObject jsonObject = new JSONObject(str).getJSONObject("data");
s = jsonObject.getString("sub");
sp = jsonObject.getString("subp");
}
}
}
Map<String, String> map = Maps.newHashMap();
map.put("SUB", s);
map.put("SUBP", sp);
return map;
}
private String postGenvisitor(String passporturl) {
Map<String, String> headers = Maps.newHashMap();
headers.put(HttpHeaders.ACCEPT, "*/*");
headers.put(HttpHeaders.ORIGIN, "https://passport.weibo.com");
headers.put(HttpHeaders.REFERER, passporturl);
Map<String, String> params = Maps.newHashMap();
params.put("cb", "gen_callback");
params.put("fp", fp());
HttpPost httpPost = HttpRequestUtils.createHttpPost(GEN_VISITOR_URL, headers, params);
String str = HttpClientInstance.instance().execute(httpPost, null);
return str.substring(str.indexOf("(") + 1, str.lastIndexOf(""));
}
private String getVisitor(String tid, String w, String c, String passporturl) {
String url = VISITOR_URL + "&t=" + tid + "&w=" + "&c=" + c.substring(c.length() - 3)
+ "&gc=&cb=cross_domain&from=weibo&_rand=0." + rand();
Map<String, String> headers = Maps.newHashMap();
headers.put(HttpHeaders.ACCEPT, "*/*");
headers.put(HttpHeaders.HOST, "passport.weibo.com");
headers.put(HttpHeaders.COOKIE, "tid=" + tid + "__0" + c);
headers.put(HttpHeaders.REFERER, passporturl);
HttpGet httpGet = HttpRequestUtils.createHttpGet(url, headers);
httpGet.setConfig(RequestConfig.custom().setCookieSpec(CookieSpecs.STANDARD).build());
return HttpClientInstance.instance().execute(httpGet, null);
}
private static String rand() {
return new BigDecimal(Math.floor(Math.random() * 10000000000000000L)).toString();
}
private static String fp() {
JSONObject jsonObject = new JSONObject();
jsonObject.put("os", "1");
jsonObject.put("browser", "Chrome59,0,3071,115");
jsonObject.put("fonts", "undefined");
jsonObject.put("screenInfo", "1680*1050*24");
jsonObject.put("plugins",
"Enables Widevine licenses for playback of HTML audio/video content. "
+"(version: 1.4.8.984)::widevinecdmadapter.dll::Widevine Content "
+"Decryption Module|Shockwave Flash 26.0 r0::pepflashplayer.dll::Shockwave"
+" Flash|::mhjfbmdgcfjbbpaeojofohoefgiehjai::Chrome PDF "
+"Viewer|::internal-nacl-plugin::Native Client|Portable Document"
+" Format::internal-pdf-viewer::Chrome PDF Viewer");
return jsonObject.toString();
}
}
}我的博客:CODE大全:www.codedq.net;业余草:www.xttblog.com;爱分享:www.ndislwf.com或ifxvn.com。

相关文章推荐
- 微博爬虫“免登录”技巧详解及 Java 实现
- http编程系列(二)——java爬虫实现刷个人博客的访问量
- java 验证用户是否已经登录与实现自动登录方法详解
- 爬虫 博客 增加访问量 Jsoup Java 正则 实现
- 微博爬虫防止被墙的技巧总结[Java]
- java实现CSDN博客迁移到WordPress爬虫工具
- java实现微博,QQ登录
- java实现 微博登录、微信登录、qq登录实现代码
- java实现微博后台登录发送微博
- Java模拟web微x登录发送文字和图片消息简单实现爬虫
- 【网络爬虫】【java】微博爬虫(五):防止爬虫被墙的几个技巧(总结篇)
- java+chromeDriver实现微博爬虫
- 微博登录、微信登录、qq登录java技术实现
- JSP+Servlet+JavaBean实现登录网页实例详解
- java+chromeDriver实现微博爬虫(二)
- java实现 微博登录、微信登录、qq登录实现代码
- JAVA爬虫实现自动登录淘宝
- java实现微博后台登录后台发送微博
- java 实现微博,QQ联合登录
- JSP+Servlet+JavaBean实现登录网页实例详解