spark2.x由浅入深深到底系列六之RDD java api详解四
2017-09-19 21:30
603 查看
学习spark任何的知识点之前,先对spark要有一个正确的理解,可以参考:正确理解spark
本文对join相关的api做了一个解释
从上可以看出,最基本的操作是cogroup这个操作,下面是cougroup的原理图:
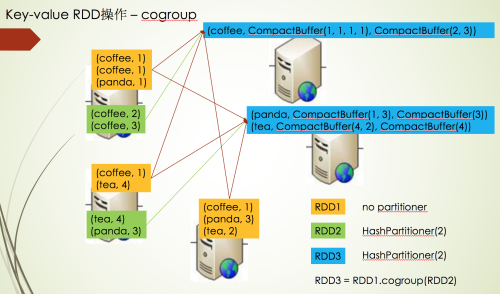
如果想对cogroup原理更彻底的理解,可以参考:spark core RDD api原理详解
本文对join相关的api做了一个解释
SparkConf conf = new SparkConf().setAppName("appName").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaPairRDD<Integer, Integer> javaPairRDD =
sc.parallelizePairs(Arrays.asList(new Tuple2<>(1, 2),
new Tuple2<>(3, 4), new Tuple2<>(3, 6), new Tuple2<>(5, 6)));
JavaPairRDD<Integer, Integer> otherJavaPairRDD =
sc.parallelizePairs(Arrays.asList(new Tuple2<>(3, 9),
new Tuple2<>(4, 5)));
//结果: [(4,([],[5])), (1,([2],[])), (3,([4, 6],[9])), (5,([6],[]))]
System.out.println(javaPairRDD.cogroup(otherJavaPairRDD).collect());
//结果: [(4,([],[5])), (1,([2],[])), (3,([4, 6],[9])), (5,([6],[]))]
// groupWith和cogroup效果是一模一样的
System.out.println(javaPairRDD.groupWith(otherJavaPairRDD).collect());
//结果: [(3,(4,9)), (3,(6,9))]
//基于cogroup实现的,就是取cogroup结果中相同key在两个RDD都有value的数据
System.out.println(javaPairRDD.join(otherJavaPairRDD).collect());
//结果: [(1,(2,Optional.empty)), (3,(4,Optional[9])), (3,(6,Optional[9])), (5,(6,Optional.empty))]
//基于cogroup实现的,结果需要出现的key以左边的RDD为准
System.out.println(javaPairRDD.leftOuterJoin(otherJavaPairRDD).collect());
//结果: [(4,(Optional.empty,5)), (3,(Optional[4],9)), (3,(Optional[6],9))]
//基于cogroup实现的,结果需要出现的key以右边的RDD为准
System.out.println(javaPairRDD.rightOuterJoin(otherJavaPairRDD).collect());
//结果: [(4,(Optional.empty,Optional[5])), (1,(Optional[2],Optional.empty)), (3,(Optional[4],Optional[9])), (3,(Optional[6],Optional[9])), (5,(Optional[6],Optional.empty))]
//基于cogroup实现的,结果需要出现的key是两个RDD中所有的key
System.out.println(javaPairRDD.fullOuterJoin(otherJavaPairRDD).collect());从上可以看出,最基本的操作是cogroup这个操作,下面是cougroup的原理图:
如果想对cogroup原理更彻底的理解,可以参考:spark core RDD api原理详解

相关文章推荐
- spark2.x由浅入深深到底系列六之RDD java api详解三
- spark2.x由浅入深深到底系列六之RDD java api用JdbcRDD读取关系型数据库
- spark2.x由浅入深深到底系列七之RDD python api详解一
- spark2.x由浅入深深到底系列六之RDD java api调用scala api的原理
- spark2.x由浅入深深到底系列六之RDD java api详解二
- spark2.x由浅入深深到底系列六之RDD 支持java8 lambda表达式
- spark2.x由浅入深深到底系列六之RDD java api详解一
- spark2.x由浅入深深到底系列六之RDD api reduceByKey与foldByKey对比
- spark2.x由浅入深深到底系列七之RDD python api详解二
- spark2.x由浅入深深到底系列七之py4j在spark中python api的使用
- spark2.x由浅入深深到底系列七之python开发spark环境配置
- Spark RDD API详解(一) Map和Reduce
- Spark RDD API详解(一) Map和Reduce
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
- Spark RDD/Core 编程 API入门系列之简单移动互联网数据(五)
- Spark RDD/Core 编程 API入门系列 之rdd实战(rdd基本操作实战及transformation和action流程图)(源码)(三)
- Spark JAVA RDD API 最全合集整理,持续更新中~
- Spark RDD API详解(一) Map和Reduce
- Spark RDD API详解 Map和Reduce
- Spark RDD API详解 Map和Reduce