正则表达式 [后向引用]
2017-09-19 11:21
204 查看
后向引用
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。分组0对应整个正则表达式
实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号
你可以使用(?:exp)这样的语法来剥夺一个分组对组号分配的参与权.
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。难以理解?
请看示例:
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, 或者kitty kitty。这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\1)。
你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:
(?<Word>\w+) #或者把尖括号换成'也行: (?'Word'\w+))#这样就把\w+的组名指定为Word了 #要反向引用这个分组捕获的内容,你可以使用\k<Word> #所以上一个例子也可以写成这样: \b(?<Word>\w+)\b\s+\k<Word>\b
使用小括号的时候,还有很多特定用途的语法。下面列出了最常用的一些:
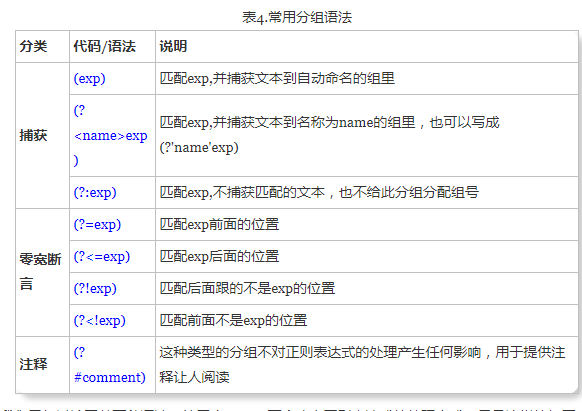
第三个(?:exp)不会改变正则表达式的处理方式,只是这样的组匹配的内容不会像前两种那样被捕获到某个组里面,也不会拥有组号。“我为什么会想要这样做?”——好问题,你觉得为什么呢?
本文参考:
[]http://www.cnblogs.com/hustskyking/archive/2013/06/04/RegExp.html]

相关文章推荐
- 正则表达式高级用法---五(反向引用 /1, /2...)
- 正则表达式之后向引用
- 正则表达式笔记 5 捕获组与逆向引用 [Capturing Group and Back Reference]
- 正则表达式——反向引用
- 正则表达式(四)--- 反向引用、断言
- 《叩响C#之门》正则表达式(五) 分组、后向引用、替换
- 正则表达式的反向引用
- python正则表达式系列(4)——分组和后向引用
- 正则表达式(后向引用和断言)
- 正则表达式简介(微软)--14.后向引用
- 正则表达式——反向引用
- 正则表达式分组的反向引用、断言详解
- 正则表达式中的反向引用
- 正则表达式:后向引用
- 正则表达式中的反向引用
- 引用RegexKitLite时使用正则表达式报错解决方法
- 正则表达式后向引用详解
- (10)javascript 引用类型 正则表达式
- 正则表达式的分组和反向引用
- codepush3之Android原生引用集成codepush