软件工程第二次作业
2017-09-18 23:20
453 查看
软件工程第二周作业
目录:
1.需求分析
2.基本设计
3.代码说明
4.测试运行
5.重难点知识
6.缺点与改进
7.词频统计psp
1.需求分析
作业链接:https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/922
作业中的老五有四种需求,应该分别对应四个功能。据分析,这四个功能分别对应了输入的三种情况,功能一输入了三个参数,对指定文本文件进行词频统计,功能二三输入了两个参数,对指定文本文件和文件夹中全部文本文件进行词频统计,功能四(只实现了作业需求中“或”字之后的内容)输入一个参数即可运行,对接下来的手写输入进行词频统计。
2.基本设计
由需求分析可以得到,可以通过对输入参数个数的判断来决定执行某一程序段。
对于功能一,输入三个参数如wf –s test.txt,获取最后一个参数作为文件名,直接为相对路径,进行打开文件读取文件操作,进行词频统计。
对于功能二,输入两个参数如wf war_and_peace,即为可执行文件名和文本名(无扩展名),我的想法是要用字符串拼接,把文本名补全,变为相对路径在当前目录下搜索文件、打开文件和对其进行词频统计。
对于功能三,输入两个参数wf folder,是可执行文件名和文件夹名,为了和功能二区分开来,我加入了第二个参数是否为”folder”字符串的判断,是则执行功能三的程序。功能三用到了文件夹的遍历;还有获取当前文件夹的路径,再利用字符串拼接制造出完整的文本文件路径,分别进行词频统计。
对于功能四,只有一个参数wf,回车之后在下一行手动输入文本,写入文件,再读取文件进行词频统计。
3.代码说明
地址:https://git.coding.net/immixiaomi/wf.git
首先定义了单词类和字符置换函数,其中置换函数会在路径获取的时候用到
主函数,argc记录参数个数,argv记录参数内容
首先判断参数个数,功能一为参数个数是3的情况,开始执行以下代码,利用在vs环境下用strncpy_s进行文件名串的获取,接下来是打开文件。其中用到了tolower()函数,在c语言中可以将大写转化成小写,头文件是ctype.h。
功能二和功能三都是两个参数,判断执行哪个功能要看第二个参数是啥,如果是“folder”则为功能三,否则是功能二。下面先说功能三。
功能三用到了字符串置换,把直接查找到的路径中的’\’转化为‘/’,并且需要把双斜线换成反向的双斜线,在此感谢高远博同学写的一篇随笔http://www.cnblogs.com/gaoyb348/p/7534845.html提到了遍历文件夹,我以前从来没接触过这个知识。然后进行字符串拼接补全路径。
然后输出每一个作品名,分别对每个作品名的作品进行词频统计。
功能二,第二个参数并没有要求输入扩展名,这就要求我们要将扩展名拼接在上边,从而得到相对路径。
功能四只有一个参数,所以判定argc==1,要进行手动输入文章,然后把其写入文件,再读取文件进行统计。
4.测试运行
功能一
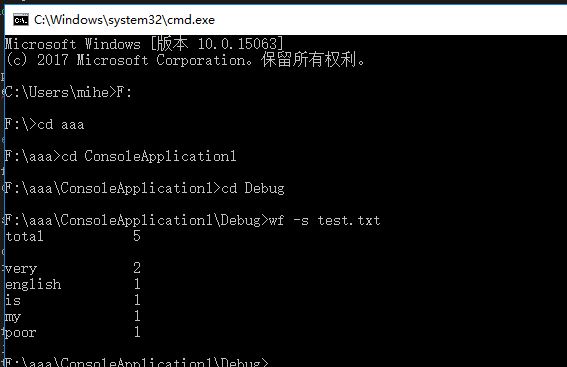
在功能二里我对数组的定义有问题,导致无法正确排序,大词汇量会溢出。因为我不会使用动态定义数组,正在学习中,需要另外的两天,无法赶上提交截止日期。但是词频和总词数是正确的。
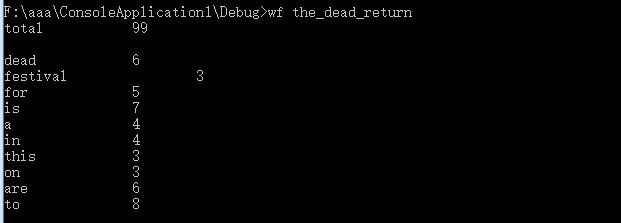
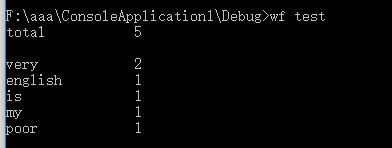
词汇量少的是正确的。
功能三可以遍历文件夹,可以正确输出文件名,但是无法排序,且经过几次测试之后无法复现,所以功能三并未实现。
功能四可以实现。
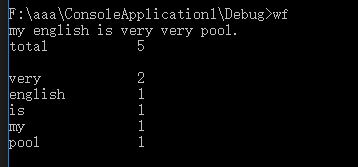
5.重难点知识
我觉得这次作业的重点难点大概有:遍历文件夹、查询当前路径、字符串的拼接和vs的安全检查导致的函数名称的转换。我参考了以下博客或网站:
查找当前工作路径http://blog.csdn.net/huhongfei/article/details/38470081
Fopen_s打开文件http://blog.csdn.net/aobo516/article/details/46387615
Strcpy_s的用法http://blog.csdn.net/geekvc/article/details/22578215
C语言下遍历文件夹https://zhidao.baidu.com/question/575084429.html
修改vs中强制进行安全检查的选项http://jingyan.baidu.com/article/359911f5427b6957fe03068f.html
6.缺点和改进
这次作业没理解动态定义数组,导致了功能二和功能三的失败。我想排序算法加入剪枝可以更快速度统计。我的程序模块化做的相当差,导致代码冗长。我将在接下来的一周里做这些改正。
7.词频统计psp
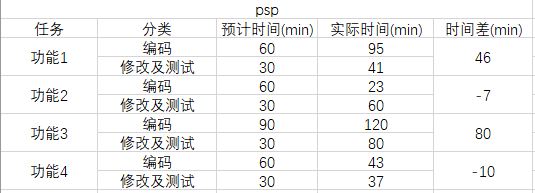
分析:功能1初次试水,对时间的估计不是很准,也有一些突发状况,但功能1的代码在2和4都可以借鉴甚至可以照搬过去其中的部分,为我节省了很多时间。在功能3遇到了大问题,遍历文件夹搜了好多资料又进行了改动,最后也没有成功运行,所以远远超出预期时间。
目录:
1.需求分析
2.基本设计
3.代码说明
4.测试运行
5.重难点知识
6.缺点与改进
7.词频统计psp
1.需求分析
作业链接:https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/922
作业中的老五有四种需求,应该分别对应四个功能。据分析,这四个功能分别对应了输入的三种情况,功能一输入了三个参数,对指定文本文件进行词频统计,功能二三输入了两个参数,对指定文本文件和文件夹中全部文本文件进行词频统计,功能四(只实现了作业需求中“或”字之后的内容)输入一个参数即可运行,对接下来的手写输入进行词频统计。
2.基本设计
由需求分析可以得到,可以通过对输入参数个数的判断来决定执行某一程序段。
对于功能一,输入三个参数如wf –s test.txt,获取最后一个参数作为文件名,直接为相对路径,进行打开文件读取文件操作,进行词频统计。
对于功能二,输入两个参数如wf war_and_peace,即为可执行文件名和文本名(无扩展名),我的想法是要用字符串拼接,把文本名补全,变为相对路径在当前目录下搜索文件、打开文件和对其进行词频统计。
对于功能三,输入两个参数wf folder,是可执行文件名和文件夹名,为了和功能二区分开来,我加入了第二个参数是否为”folder”字符串的判断,是则执行功能三的程序。功能三用到了文件夹的遍历;还有获取当前文件夹的路径,再利用字符串拼接制造出完整的文本文件路径,分别进行词频统计。
对于功能四,只有一个参数wf,回车之后在下一行手动输入文本,写入文件,再读取文件进行词频统计。
3.代码说明
地址:https://git.coding.net/immixiaomi/wf.git
首先定义了单词类和字符置换函数,其中置换函数会在路径获取的时候用到
class Seword //定义单词类,字符型数组a[15]记录单词,整形变量num记录出现次数
{
public:
int num;
char a[15];
};
Seword W
; //把文章存在W
里
void replaceChar(char *string, char oldChar, char newChar) //字符置换函数
{
int len = strlen(string);
int i;
for (i = 0; i < len; i++) {
if (string[i] == oldChar)
{
string[i] = newChar;
}
}
return;
}主函数,argc记录参数个数,argv记录参数内容
/*******主函数,利用argc记录输入参数个数,利用数组argv[]记录参数内容*******/ int main(int argc, char *argv[])
首先判断参数个数,功能一为参数个数是3的情况,开始执行以下代码,利用在vs环境下用strncpy_s进行文件名串的获取,接下来是打开文件。其中用到了tolower()函数,在c语言中可以将大写转化成小写,头文件是ctype.h。
/*******功能一:当输入参数为三个的时候,即对应可输入>wf -s test.txt的需求*******/
if (argc==3)
{
int count = 1; //定义一个类
int i, k, m, n, temp, j = 0;
char b[15]; //和a交换的数组
FILE *fp1 = NULL;
char chh; //从文件中读取字符
int flag = 0; //是否有单词的标志位
char filename1[20];
for (i = 0; i < N; i++) //将出现次数设置为1
{
W[i].num = 1;
}
i = 0;
strncpy_s(filename1, argv[2], 20);
errno_t errr;
if ((errr = fopen_s(&fp1, filename1, "r")) != 0)//打开文件
{
printf("error opening!");
exit(0);
}
while (!feof(fp1))//读取文件
{
chh = fgetc(fp1);
W[i].a[j] = '\0';
if (chh >= 65 && chh <= 90 || chh >= 97 && chh <= 122) //识别单词
{
W[i].a[j] = tolower(chh); //小写转换大写
j++;
flag = 1;
}
else if (chh == ' '&&flag == 1)
{
flag = 0;
j = 0;
n = i;
i++;
count++;
if (n >= 1) //单词跟之前比较,如果相同就使次数+1
{
for (m = 0; m < n; m++)
{
if (strcmp(W
.a, W[m].a) == 0)//单词查重复
{
W[m].num++;
i = i - 1;
count--;
}
}
}
}
}
//根据单词出现次数进行排序
for (n = 0; n < i - 1; n++)
{
k = n;
for (j = n + 1; j < i; j++)
if (W[j].num > W[k].num)
{
k = j;
temp = W[k].num;
W[k].num = W
.num;
W
.num = temp;
strcpy_s(b, 15, W[k].a);
strcpy_s(W[k].a, 15, W
.a);
strcpy_s(W
.a, 15, b);
}
}
//输出部分
printf("total\t\t%d\n\n", count);
if (count < 10) //判断是否总次数小于十个,分情况输出
{
for (n = 0; n < count; n++)
{
printf("%s", W
.a);
printf("\t\t%d\n", W
.num);
}
}
else {
for (n = 0; n <= 9; n++) //大于十个的情况
{
printf("%s", W
.a);
printf("\t\t%d\n", W
.num);
}
}
}功能二和功能三都是两个参数,判断执行哪个功能要看第二个参数是啥,如果是“folder”则为功能三,否则是功能二。下面先说功能三。
功能三用到了字符串置换,把直接查找到的路径中的’\’转化为‘/’,并且需要把双斜线换成反向的双斜线,在此感谢高远博同学写的一篇随笔http://www.cnblogs.com/gaoyb348/p/7534845.html提到了遍历文件夹,我以前从来没接触过这个知识。然后进行字符串拼接补全路径。
然后输出每一个作品名,分别对每个作品名的作品进行词频统计。
/*******当输入参数为两个的时候,对应两种需求*******/
else if (argc == 2)
{
/************功能三:如果第二个参数为folder则执行以下,对应>wf folder的需求**********/
if (!strcmp(argv[1], "folder"))
{
char oldChar = '\\';
char newChar = '//'; //确定当前目录路径时,需要进行置换,写成两个反斜线是因为是转义字符
char *buffer;
if ((buffer = _getcwd(NULL, 0)) == NULL) //确定当前路径
{
perror("getcwd error");
}
else
{
struct _finddata_t files;
int File_Handle;
int i = 0;
replaceChar(buffer, oldChar, newChar); //在这将'\'替换为'/ '
buffer = strcat(buffer, "/folder/*.txt"); //拼接为真正的路径
File_Handle = _findfirst(buffer, &files);
if (File_Handle == -1)
{
printf("error\n");
return 0;
}
do
{
printf("%s \n", files.name);//每个作品先输出作品,再输出统计结果
int count = 1;
int i, k, m, n, j = 0;
char b[15]; //和a交换的数组
FILE *fp1;
char chh; //从文件中读取字符
int flag = 0; //标志空格后面是否有单词
int temp; //排序时交换用
//首先将出现次数均设置为1
for (i = 0; i < N; i++)
{
W[i].num = 1;
}
i = 0;
//打开文件
errno_t errr;
if ((errr = fopen_s(&fp1, files.name, "r")) != 0)
{
printf("error opening!");
exit(0);
}
//读取文件
while (!feof(fp1))
{
chh = fgetc(fp1);
W[i].a[j] = '\0';
if (chh >= 65 && chh <= 90 || chh >= 97 && chh <= 122)
{
W[i].a[j] = tolower(chh); //大小写转换
j++;
flag = 1;
}
else if (chh == ' '&&flag == 1)
{
flag = 0;
j = 0;
n = i;
i++;
count++;
if (n >= 1) //单词跟之前比较,如果相同就使次数+1
{
for (m = 0; m < n; m++)
{
if (strcmp(W
.a, W[m].a) == 0)
{
W[m].num++;
i = i - 1; //单词查重复的判断
count--;
}
}
}
}
}
//根据单词出现次数进行排序
for (n = 0; n < i - 1; n++)
{
k = n;
for (j = n + 1; j < i; j++)
if (W[j].num > W[k].num)
{
k = j;
temp = W[k].num;
W[k].num = W
.num;
W
.num = temp;
strcpy_s(b, 15, W[k].a);
strcpy_s(W[k].a, 15, W
.a);
strcpy_s(W
.a, 15, b);
}
}
//输出部分
printf("total\t\t%d\n\n", count);
if (count < 10)
{
for (n = 0; n < count; n++)
{
printf("%s", W
.a);
printf("\t\t%d\n", W
.num);
}
}
else {
for (n = 0; n <= 9; n++)
{
printf("%s", W
.a);
printf("\t\t%d\n", W
.num);
}
}
i++;
} while (0 == _findnext(File_Handle, &files));
_findclose(File_Handle);
free(buffer); //清空路径申请的buffer空间
}
return 0;
}功能二,第二个参数并没有要求输入扩展名,这就要求我们要将扩展名拼接在上边,从而得到相对路径。
/*********功能二:在两个参数的情况下,直接输入文件名打开当前目录下文件,对应输入>wf test的情况***********/
else
{
int count = 1;
int i, k, m, n;
char b[15]; //用来和a交换的数组
FILE *fp1 = NULL; //定义文件
char chh; //从文件中读取字
int flag = 0; //标志位
int j = 0;
int temp; //排序时交换变量
char filename1[30];
//将出现次数均设置为1
for (i = 0; i < N; i++)
{
W[i].num = 1;
}
i = 0;
//打开文件
strncpy_s(filename1, argv[1], 30); //字符串拼接,把.txt拼接为路径
strcat_s(filename1, 30, ".txt");
errno_t errr;
if ((errr = fopen_s(&fp1, filename1, "r")) != 0)
{
printf("error opening!");
exit(0);
}
//读取文件
while (!feof(fp1))
{
chh = fgetc(fp1);
W[i].a[j] = '\0';
if (chh >= 65 && chh <= 90 || chh >= 97 && chh <= 122)
{
W[i].a[j] = tolower(chh); //转成小写
j++;
flag = 1;
}
else if (chh == ' '&&flag == 1)
{
flag = 0;
j = 0;
n = i;
i++;
count++;
if (n >= 1) //单词跟之前比较,如果相同就使次数+1
{
for (m = 0; m < n; m++)
{
if (strcmp(W
.a, W[m].a) == 0)
{
W[m].num++;
i = i - 1; //单词查重复的判断
count--;
}
}
}
}
}
//根据单词出现次数进行排序
for (n = 0; n < i - 1; n++)
{
k = n;
// for (j = 0; j < i; j++)
for (j = n + 1; j < i; j++)
if (W[j].num > W[k].num)
{
k = j;
temp = W[k].num;
W[k].num = W
.num;
W
.num = temp;
strcpy_s(b, 15, W[k].a);
strcpy_s(W[k].a, 15, W
.a);
strcpy_s(W
.a, 15, b);
}
}
//输出部分
printf("total\t\t%d\n\n", count);
if (count < 10)
{
for (n = 0; n < count; n++)
{
printf("%s", W
.a);
printf("\t\t%d\n", W
.num);
}
}
else {
for (n = 0; n <= 9; n++)
{
printf("%s", W
.a);
printf("\t\t%d\n", W
.num);
}
}
}
}功能四只有一个参数,所以判定argc==1,要进行手动输入文章,然后把其写入文件,再读取文件进行统计。
/********功能四:一个参数,直接手动输入写入文件并读取统计,对应第四个功能第二种情况************/
else if (argc == 1)
{
FILE *fp;
errno_t err;
char ch;
if ((err = fopen_s(&fp, "test.txt", "w")) != 0)
{
printf("无法打开此文件\n");
exit(0);
}
ch = getchar(); //用来接收最后输入的回车符
while (ch != '\n') //以回车标志输入结束
{
fputc(ch, fp);
ch = getchar();
}
fclose(fp); //关闭文件
int count = 1;
int i, k, m, n;
char b[15]; // 用来和a交换的数组
FILE *fp1;
char chh; //从文件中读取字符
int flag = 0; //空格后面是否有单词
int j = 0;
int temp;
//将出现次数均设置为1
for (i = 0; i < N; i++)
{
W[i].num = 1;
}
i = 0;
//打开文件
errno_t errr;
if ((errr = fopen_s(&fp1, "test.txt", "r")) != 0)
{
printf("error opening!");
exit(0);
}
//读取文件内容
while (!feof(fp1))
{
chh = fgetc(fp1);
W[i].a[j] = '\0';
if (chh >= 65 && chh <= 90 || chh >= 97 && chh <= 122)
{
W[i].a[j] = tolower(chh); //识别单词
j++;
flag = 1;
}
else if (chh == ' '&&flag == 1)
{
flag = 0;
j = 0;
n = i;
i++;
count++;
if (n >= 1) //单词跟前面的比较,如果相同就使次数+1
{
for (m = 0; m < n; m++)
{
if (strcmp(W
.a, W[m].a) == 0)
{
W[m].num++;
i = i - 1; //相同则认为是一个单词
count--;
}
}
}
}
}
//根据单词出现次数进行排序
for (n = 0; n < i - 1; n++)
{
k = n;
for (j = n + 1; j < i; j++)
if (W[j].num > W[k].num)
{
k = j;
temp = W[k].num;
W[k].num = W
.num;
W
.num = temp;
strcpy_s(b, 15, W[k].a);
strcpy_s(W[k].a, 15, W
.a);
strcpy_s(W
.a, 15, b);
}
}
//输出部分
printf("total\t\t%d\n\n", count);
if (count < 10)
{
for (n = 0; n < count; n++)
{
printf("%s", W
.a);
printf("\t\t%d\n", W
.num);
}
}
else {
for (n = 0; n <= 9; n++)
{
printf("%s", W
.a);
printf("\t\t%d\n", W
.num);
}
}
}4.测试运行
功能一
在功能二里我对数组的定义有问题,导致无法正确排序,大词汇量会溢出。因为我不会使用动态定义数组,正在学习中,需要另外的两天,无法赶上提交截止日期。但是词频和总词数是正确的。
词汇量少的是正确的。
功能三可以遍历文件夹,可以正确输出文件名,但是无法排序,且经过几次测试之后无法复现,所以功能三并未实现。
功能四可以实现。
5.重难点知识
我觉得这次作业的重点难点大概有:遍历文件夹、查询当前路径、字符串的拼接和vs的安全检查导致的函数名称的转换。我参考了以下博客或网站:
查找当前工作路径http://blog.csdn.net/huhongfei/article/details/38470081
Fopen_s打开文件http://blog.csdn.net/aobo516/article/details/46387615
Strcpy_s的用法http://blog.csdn.net/geekvc/article/details/22578215
C语言下遍历文件夹https://zhidao.baidu.com/question/575084429.html
修改vs中强制进行安全检查的选项http://jingyan.baidu.com/article/359911f5427b6957fe03068f.html
6.缺点和改进
这次作业没理解动态定义数组,导致了功能二和功能三的失败。我想排序算法加入剪枝可以更快速度统计。我的程序模块化做的相当差,导致代码冗长。我将在接下来的一周里做这些改正。
7.词频统计psp
分析:功能1初次试水,对时间的估计不是很准,也有一些突发状况,但功能1的代码在2和4都可以借鉴甚至可以照搬过去其中的部分,为我节省了很多时间。在功能3遇到了大问题,遍历文件夹搜了好多资料又进行了改动,最后也没有成功运行,所以远远超出预期时间。

相关文章推荐
- 软件工程第二次作业
- 软件工程第二次作业
- 软件工程第二次作业----
- 软件工程第二次作业
- 软件工程第二次作业
- 14软件工程第二次作业
- 软件工程第二次作业
- 软件工程第二次作业(2)
- 软件工程实践 2017 第二次结对作业
- 软件工程第二次作业-3D游戏开发(3D版俄罗斯方块)
- 软件工程第二次作业
- 软件工程第二次作业 - 每周例行报告
- 软件工程-东北师大站-第二次作业psp
- 软件工程第二次作业
- 软件工程第二次作业
- 软件工程第二次作业
- 软件工程网络15个人阅读作业1(201521123052 蓝锦明)
- 软件工程网络15结对编程作业
- 软件工程第二次二人协作项目 3D俄罗斯方块
- 软件工程作业三:微软小娜APP的案例分析