软件工程---第二次作业(2)
2017-09-18 20:34
260 查看
Part One
PSP 在同一篇博客中,参照教材第35页表2-2和表2-3,为上述“项目”制作PSP阶段表格。 PSP阶段表格第1列分类,如功能1、功能2、测试功能1等。 要求1 估算你对每个功能 (或/和子功能)的预计花费时间,填入PSP阶段表格,时间颗粒度为分钟。 要求2 记录词频统计项目实际花费时间,填入PSP阶段表格,时间颗粒度要求分钟。 要求3 对比要求1和要求3中每项时间花费的差距,分析原因。
通过上面的PSP图可以看到,项目的实际花费时间,几乎是当时估计的两倍,分析原因如下:
(1)最开始,在完成这个项目时,如果没有一点思路,就要花费时间寻找解决问题的思路,才能知道这件事要怎么做。
(2)对某些函数的细节使用并不是很清楚,有的只知道有那么一个函数有这个功能,但是不知道,还有和它长得很像的函数,功能也相差不大,但是是针对不同情况的,这时,寻找合适的函数就需要花费一定时间。
(3)有些函数的使用,如文件的读入,对map中的数值进行排序,这类函数使用的少,熟悉程度不高,在编程过程中,就要时不时地停下来去寻找自己所需要用到的函数。
Part Two
发表博客,介绍上述“项目”中每个功能的重点/难点,展示重要代码片断,展示你感觉得意、突破、困难的地方。代码片断要求1. 凡不缩进的,此题目拒绝接收。代码片断要求2 .要求使用cnblogs代码控件。
(1)在这个“统计词汇数量”的项目中,我觉得重点是一种思维方式,最开始在刚刚听到这个题目时,要统计一篇很长很长的,是类似世界名著那样的英文文章,顿时没有了思路,心想,那么那么长,统计得多久啊。后来,便开始在网上查阅有关统计词汇的介绍,看了很多的博客、代码,慢慢学习到了解决这个问题的思路,那就是无论多长的文章,都把它看成一句话,是个字符串,这个字符串比较长,这个字符串中不仅有英文单词,还有一些标点符号,而这些标点符号,正好是分割函数中的分割标准,这样一来,在将这个长长的字符串进行分割后,剩余的就是一个又一个需要计数统计的单词了。
图示:将文章看成一个长长的字符串,以分解的方式计算其单词数量
(2)在知道了整体大概的思路后,实现的过程中,难点就是细节问题了,比如说在Java中以前我知道有个输入函数是scanner,在最开始用这个函数时,我使用的是“String s = scanner.next();”,测试的时候发现,我在输入一句话的时候,它只接收我的第一个单词,其余单词视而不见,刚开始还以为是自己输入错了,后来查阅资料时,知道了应该用“scanner.nextLine();”,它会读取一句话中的所有单词,而不只是第一个。
图示:以这样的输入方式就可以获得输入的全部内容,而不仅仅是第一个单词
(3)在查阅资料的过程中,我也在不断理解他人的代码,并进行学习,最终可以实现词汇数量的统计,在这个过程中,我认为自己做的比较好的地方就是对某个磁盘下文件的读取。我的想法是,首先某个磁盘下的文本文件的数量应该大于1,于是我采用循环的方式,在循环的过程中,我是将这些文件都看成了一个文件的数组,这样可以通过一些语句不仅可以获得文件的总数量,还可以像数组那样用下标的方式,获得其文件名,为我后续的用文件名的方式进行统计带来了方便。
图示:获取磁盘下的文件时要先向内存要缓冲区,并且在获取文件时还要有抓异常的处理,判断文件是否存在或是否可读
(4)觉得有所突破的地方就是对map这个集合函数的使用,利用它的一些特性,健值不重复,可以统计有多少不重复的单词;将它的两个属性一个设置为字符串类型,来记录单词,另一个设计成整型,来记录其个数。在向其中添加值时,利用map.containsKey(word)语句进行判断,如果map中已有,则其数量值加1,若匹配不上,则将数量值记为1,在记录为1时,又设置另一个变量pairNumber,每次这种情况时,它都自加1,记录不重复的单词数。
图示:利用map函数的特点,来统计单词的数量
(5)觉得比较困难的地方,就是在读入文件时,既要考虑文件的路径问题,还要通过一些函数将这个文件读进来,要考虑输入的格式,是否可以确定位置,觉得这部分有点难。
图示:明确怎样获取文章的路径,获取到的路径是什么样的路径,比如绝对路径,还是基于当前工作文档的
Part Three
运行截图
1.输入一句话
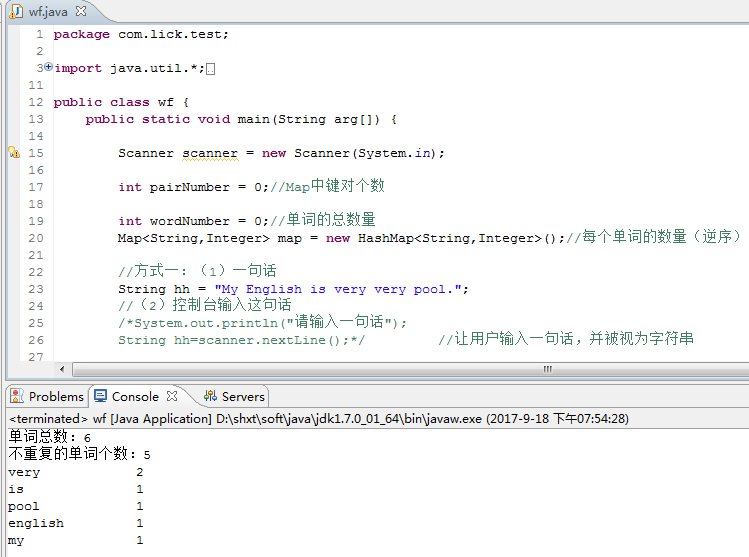
2.控制台输入一句话
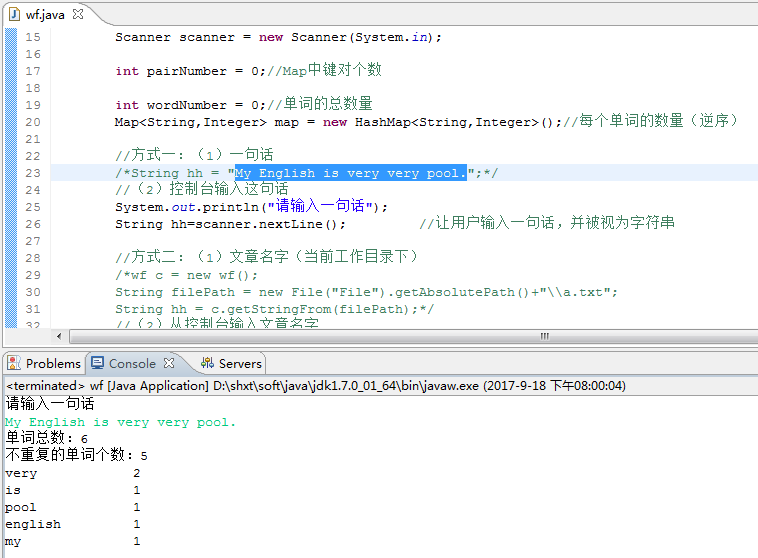
3.某篇文章
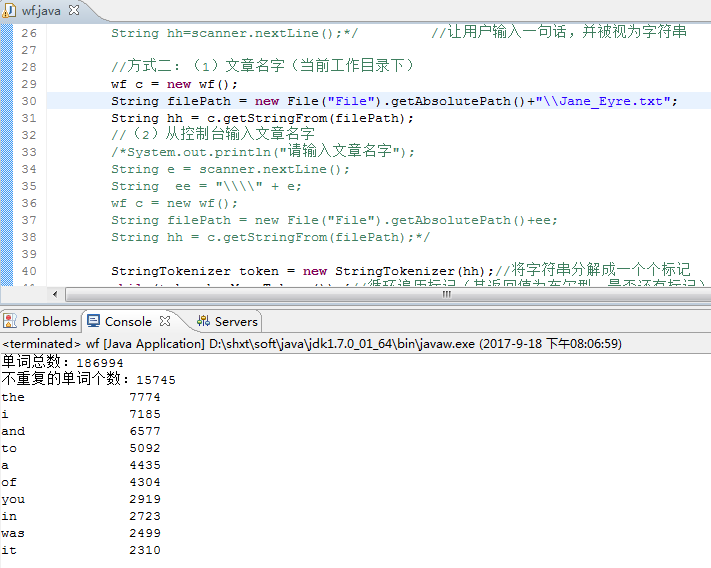
4.控制台输入文章名
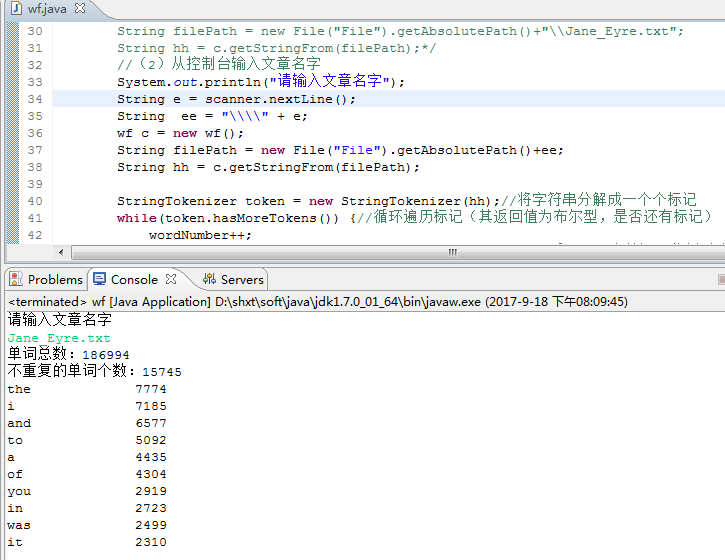
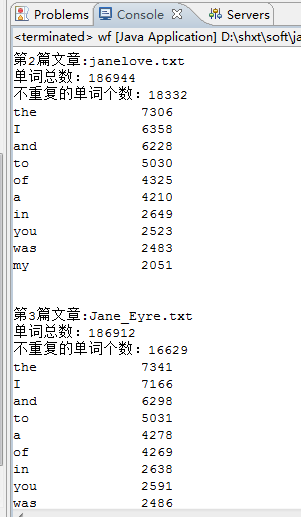
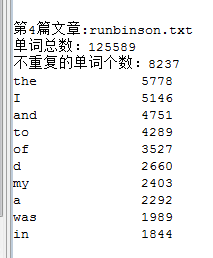
5.某磁盘下的全部文章

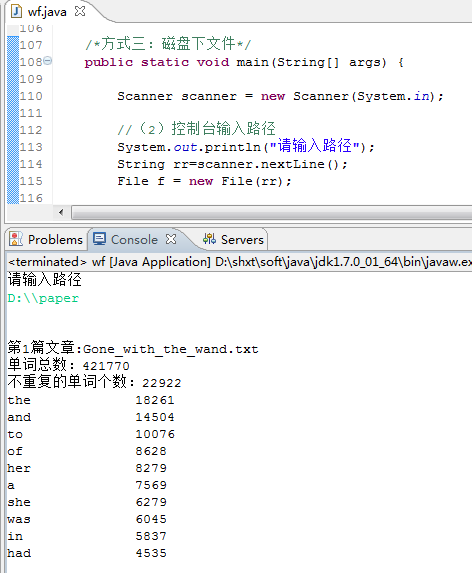
6.输入文章的磁盘路径
代码链接:(wf.java)
git地址:https://git.coding.net/wangh013/wordNumber.git
PSP 在同一篇博客中,参照教材第35页表2-2和表2-3,为上述“项目”制作PSP阶段表格。 PSP阶段表格第1列分类,如功能1、功能2、测试功能1等。 要求1 估算你对每个功能 (或/和子功能)的预计花费时间,填入PSP阶段表格,时间颗粒度为分钟。 要求2 记录词频统计项目实际花费时间,填入PSP阶段表格,时间颗粒度要求分钟。 要求3 对比要求1和要求3中每项时间花费的差距,分析原因。
| 分 类 | 预计花费时间 | 实际花费时间 |
| 功能一:统计一句话中的词汇数量 | 5min | 10min |
| 功能二:控制台输入一句话并统计词汇数量 | 10min | 20min |
| 测试一:对一句话的词汇数量统计进行功能测试 | 10min | 10min |
| 功能三:统计指定文章中的词汇数量 | 25min | 40min |
| 功能四:输入文章名并统计其词汇数量 | 40min | 60min |
| 测试二:对某篇文章中的词汇数量统计功能进行测试 | 10min | 12min |
| 功能五:指定文件所在的文件夹路径,并逐一文件进行词汇数量的统计 | 68min | 130min |
| 功能六:从控制台输入文件的文件夹路径,并逐一文件进行词汇数量的统计 | 80min | 268 |
| 测试三:对某个文件夹中的所有文件的统计词汇数量功能进行测试 | 15min | 13min |
| 完成 | 263min | 563min |
(1)最开始,在完成这个项目时,如果没有一点思路,就要花费时间寻找解决问题的思路,才能知道这件事要怎么做。
(2)对某些函数的细节使用并不是很清楚,有的只知道有那么一个函数有这个功能,但是不知道,还有和它长得很像的函数,功能也相差不大,但是是针对不同情况的,这时,寻找合适的函数就需要花费一定时间。
(3)有些函数的使用,如文件的读入,对map中的数值进行排序,这类函数使用的少,熟悉程度不高,在编程过程中,就要时不时地停下来去寻找自己所需要用到的函数。
Part Two
发表博客,介绍上述“项目”中每个功能的重点/难点,展示重要代码片断,展示你感觉得意、突破、困难的地方。代码片断要求1. 凡不缩进的,此题目拒绝接收。代码片断要求2 .要求使用cnblogs代码控件。
(1)在这个“统计词汇数量”的项目中,我觉得重点是一种思维方式,最开始在刚刚听到这个题目时,要统计一篇很长很长的,是类似世界名著那样的英文文章,顿时没有了思路,心想,那么那么长,统计得多久啊。后来,便开始在网上查阅有关统计词汇的介绍,看了很多的博客、代码,慢慢学习到了解决这个问题的思路,那就是无论多长的文章,都把它看成一句话,是个字符串,这个字符串比较长,这个字符串中不仅有英文单词,还有一些标点符号,而这些标点符号,正好是分割函数中的分割标准,这样一来,在将这个长长的字符串进行分割后,剩余的就是一个又一个需要计数统计的单词了。
//从控制台输入文章名字
System.out.println("请输入文章名字");
String e = scanner.nextLine();
String ee = "\\\\" + e;
wf c = new wf();
String filePath = new File("File").getAbsolutePath()+ee;
String hh = c.getStringFrom(filePath);
StringTokenizer token = new StringTokenizer(hh);//将字符串分解成一个个标记图示:将文章看成一个长长的字符串,以分解的方式计算其单词数量
(2)在知道了整体大概的思路后,实现的过程中,难点就是细节问题了,比如说在Java中以前我知道有个输入函数是scanner,在最开始用这个函数时,我使用的是“String s = scanner.next();”,测试的时候发现,我在输入一句话的时候,它只接收我的第一个单词,其余单词视而不见,刚开始还以为是自己输入错了,后来查阅资料时,知道了应该用“scanner.nextLine();”,它会读取一句话中的所有单词,而不只是第一个。
Scanner scanner = new Scanner(System.in);
//(2)控制台输入路径
System.out.println("请输入路径");
String rr=scanner.nextLine();
File f = new File(rr);图示:以这样的输入方式就可以获得输入的全部内容,而不仅仅是第一个单词
(3)在查阅资料的过程中,我也在不断理解他人的代码,并进行学习,最终可以实现词汇数量的统计,在这个过程中,我认为自己做的比较好的地方就是对某个磁盘下文件的读取。我的想法是,首先某个磁盘下的文本文件的数量应该大于1,于是我采用循环的方式,在循环的过程中,我是将这些文件都看成了一个文件的数组,这样可以通过一些语句不仅可以获得文件的总数量,还可以像数组那样用下标的方式,获得其文件名,为我后续的用文件名的方式进行统计带来了方便。
try{
//BufferedReader br = new BufferedReader(new FileReader("D:\\paper\\" + fs[i].toString().substring(9)));//新建缓存区,读取文件
BufferedReader br = new BufferedReader(new FileReader(rr + "\\\\" + fs[i].toString().substring(9)));
StringBuffer mp= new StringBuffer();//更新缓存
String s;
while (( s=br.readLine())!= null) {
mp.append(s);
}
Map<String,Integer> map = new HashMap<String, Integer>();//哈希排序
StringTokenizer token = new StringTokenizer(mp.toString());//分割字符串
while(token.hasMoreTokens()) {//循环遍历标记(其返回值为布尔型,是否还有标记)
wordNumber++;
String word = token.nextToken(", ?.!:\"\"''\n");//返回下一个单词,分割形式是以,空格。?!:‘’“”换行
word = word.toLowerCase();
if(map.containsKey(word)) {//已存在直接加1
int singleNumber = map.get(word);
map.put(word, singleNumber+1);
}else {//若不存在,则新添加,并且新置为1
map.put(word, 1);
pairNumber++;
}
}
System.out.println("\n");
//第几篇文章
int j = i + 1;
System.out.println("第" + j + "篇文章");
//总的单词数量
System.out.println("单词总数:" + wordNumber);
//多少个不重复的单词
System.out.println("不重复的单词个数:" + pairNumber);
sort(map);//map键对排序
} catch (FileNotFoundException e) {
System.out.println("文件未找到~!");//异常处理
} catch (IOException e) {
System.out.println("文件读异常~!");//异常处理
}图示:获取磁盘下的文件时要先向内存要缓冲区,并且在获取文件时还要有抓异常的处理,判断文件是否存在或是否可读
(4)觉得有所突破的地方就是对map这个集合函数的使用,利用它的一些特性,健值不重复,可以统计有多少不重复的单词;将它的两个属性一个设置为字符串类型,来记录单词,另一个设计成整型,来记录其个数。在向其中添加值时,利用map.containsKey(word)语句进行判断,如果map中已有,则其数量值加1,若匹配不上,则将数量值记为1,在记录为1时,又设置另一个变量pairNumber,每次这种情况时,它都自加1,记录不重复的单词数。
while(token.hasMoreTokens()) {//循环遍历标记(其返回值为布尔型,是否还有标记)
wordNumber++;
String word = token.nextToken(", ?.!:\"\"''\n");//返回下一个单词,分割形式是以,空格。?!:‘’“”换行
word = word.toLowerCase();
if(map.containsKey(word)) {//已存在直接加1
int singleNumber = map.get(word);
map.put(word, singleNumber+1);
}else {//若不存在,则新添加,并且新置为1
map.put(word, 1);
pairNumber++;
}
}图示:利用map函数的特点,来统计单词的数量
(5)觉得比较困难的地方,就是在读入文件时,既要考虑文件的路径问题,还要通过一些函数将这个文件读进来,要考虑输入的格式,是否可以确定位置,觉得这部分有点难。
System.out.println("请输入文章名字");
String e = scanner.nextLine();
String ee = "\\\\" + e;
wf c = new wf();
String filePath = new File("File").getAbsolutePath()+ee;
String hh = c.getStringFrom(filePath);图示:明确怎样获取文章的路径,获取到的路径是什么样的路径,比如绝对路径,还是基于当前工作文档的
Part Three
运行截图
1.输入一句话
2.控制台输入一句话
3.某篇文章
4.控制台输入文章名
5.某磁盘下的全部文章
6.输入文章的磁盘路径
代码链接:(wf.java)
git地址:https://git.coding.net/wangh013/wordNumber.git

相关文章推荐
- 现代软件工程第二次作业
- 软件工程第二次作业
- 软件工程第二次作业(最大子数组和)
- 软件工程第二次作业
- 集大1513 & 1514班 软件工程第二次作业评分与点评
- 软件工程-东北师大站-第二次作业
- 软件工程第二次作业
- 软件工程第二次作业(王伟东)
- 2017202110104-高级软件工程第二次作业个人项目之-四则运算生成程序
- 第二次软件工程作业:第一次组队编程
- 软件工程第二次作业(3)
- 软件工程第二次作业 软件评价
- 软件工程第二次作业 软件评价
- 软件工程第二次作业
- 高级软件工程第二次作业
- 软件工程结对项目第二次作业
- 软件工程实践2017 结队项目——第二次作业
- 软件工程实践 · 团队项目(第二次作业)
- 软件工程实践 2017 第二次作业(部分)
- 软件工程第二次作业(完整版)