memcached做数据库缓存的原理
2017-09-17 22:52
169 查看
安装篇请参考http://my.oschina.net/flynewton/blog/9694
最近研究memcache小有成果,把经验分享出来。
白话:很早就听说memcache了,一直没搞懂,后来又看到redis很火,可以用来做缓存,研究了半天也没搞懂咋个做缓存,后来也不纠结了,继续学习python,当对python基础有一定掌握后,渐渐明白如何用redis或memcache做数据库的缓存。原理很简单,memcache和redis都是在内存开辟一堆空间,用键-》值来保存数据,在python称作字典,具体流程如此图
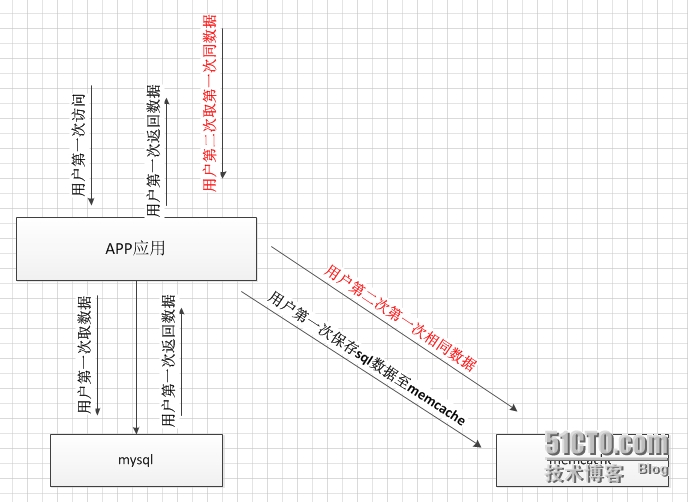
当用户第一次通过web应用程序,去读取数据库,返回数据值的时候,web应用服务器会做两个动作,第一个动作,返回给用户,第二个动作会写入memcache,当第二个用户去访问相同的数据时,程序代码前添加if判断语句,如果memcache有需要的数据,直接从memcache取。
可能表达的还不够清楚,我们通过代码来测试下。我用的环境是python+django
----查询代码
{常规做法有两种:
1.数据有改变则在更新数据库的同时更新memcache
2.数据有改变则数据库有一个字段来标识更新时间,例如update_time。当有查询时候,把memcache里的update_time与数据库的update_time比较。如果发生变化则更新memcache
超期时间设置,应根据数据访问的频繁度和内存大小来权衡一下。
memcache内存申请后,映像中不会被释放。它是通过 如果有一部分数据超时,则新写入的数据覆盖超时数据来完成重复使用的。那么理论上来讲,内存使用情况是数据被memcache占用最多的那一刻!}
---实验用的第一种。
Python-memcached的基本使用参考http://my.oschina.net/flynewton/blog/10660
白话:很早就听说memcache了,一直没搞懂,后来又看到redis很火,可以用来做缓存,研究了半天也没搞懂咋个做缓存,后来也不纠结了,继续学习python,当对python基础有一定掌握后,渐渐明白如何用redis或memcache做数据库的缓存。原理很简单,memcache和redis都是在内存开辟一堆空间,用键-》值来保存数据,在python称作字典,具体流程如此图
当用户第一次通过web应用程序,去读取数据库,返回数据值的时候,web应用服务器会做两个动作,第一个动作,返回给用户,第二个动作会写入memcache,当第二个用户去访问相同的数据时,程序代码前添加if判断语句,如果memcache有需要的数据,直接从memcache取。
可能表达的还不够清楚,我们通过代码来测试下。我用的环境是python+django
----查询代码
def sql(request):
#连接memcache
mc = memcache.Client(['127.0.0.1:1111'])
#用sql查询语句作为memcahe的键
key2 = 'select * from zuoze'
key2 = md5(key2)
#数据库查询zuoze表的数据
sql1 = "select * from zuoze"
#判断sql键有没有在memcache,就从mysql取数据,并写入memcache
if not mc.get(key2):
#import MySQLdb
#连接mysql数据库
db = MySQLdb.connect('127.0.0.1','admin','wanwan','T')
cursor = db.cursor()
cursor.execute(sql1)
#绑定sql数据到变量results
results = cursor.fetchall()
#同时把sql查询数据,写入memcache
mc.set(key2,results)
print "go mysql!!"
db.close()
return render_to_response("sql.html",{'results':results})
#直接从memcache取数据
else:
results = mc.get(key2)
print "go memcache!!!"
return render_to_response("sql.html",{'results':results})--更新缓存的两种办法,转至论坛高手的回答:{常规做法有两种:
1.数据有改变则在更新数据库的同时更新memcache
2.数据有改变则数据库有一个字段来标识更新时间,例如update_time。当有查询时候,把memcache里的update_time与数据库的update_time比较。如果发生变化则更新memcache
超期时间设置,应根据数据访问的频繁度和内存大小来权衡一下。
memcache内存申请后,映像中不会被释放。它是通过 如果有一部分数据超时,则新写入的数据覆盖超时数据来完成重复使用的。那么理论上来讲,内存使用情况是数据被memcache占用最多的那一刻!}
---实验用的第一种。
def upsql(request):
if request.method == 'POST':
xing = request.POST.get('xing',None)
name = request.POST.get('name',None)
mail = request.POST.get('email',None)
shuji_id = request.POST.get('mail',None)
db = MySQLdb.connect('127.0.0.1','admin','wanwan','T')
cursor = db.cursor()
sql = "insert into zuoze(id,xing,name,email,shuji_id) values ('','%s','%s','%s','%s')" % (xing,name,mail,shuji_id)
cursor.execute(sql)
db.commit()
#插入数据或更新数据后,重新更新memcache数据
mc = memcache.Client(['127.0.0.1:1111'])
key2 = 'select * from zuoze'
key3 = md5(key2)
cursor.execute(key2)
results = cursor.fetchall()
mc.set(key3,results)
db.close()
return HttpResponse('ok!')
return render_to_response("upsql.html")本文出自 “自动运维” 博客,请务必保留此出处http://whf191.blog.51cto.com/5763502/1657032

相关文章推荐
- memcached&redis等分布式缓存的实现原理
- memcached 缓存数据库应用实践
- 使用Memcached、Spring AOP构建数据库前端缓存框架
- memcached数据库缓存
- 数据库缓存技术——Memcached入门
- 使用Memcached、Spring AOP构建数据库前端缓存框架
- 缓存数据库redis、memcached。 MongoDB 资源集锦
- 使用Memcached、Spring AOP构建数据库前端缓存框架
- memcached 缓存数据库应用实践
- iOS数据库离线缓存思路和网络层封装——原理
- LRU算法的解释——android数据库缓存中用到的原理
- 使用Memcached、Spring AOP构建数据库前端缓存框架
- 使用Memcached、Spring AOP构建数据库前端缓存框架
- memcached做数据库缓存
- memcached多个服务器间分享缓存实现缓存负载均衡(一. 原理)
- memcached和redis两大数据库缓存系统实现对比
- 使用Memcached、Spring AOP构建数据库前端缓存框架
- PHP那些事:数据库缓存原理
- C#中缓存数据库Memcached的基本使用方法
- TimesTen 应用层数据库缓存学习:15. TimesTen 缓存组autorefresh的原理