用最大似然估计求逻辑回归参数
2017-09-17 15:38
447 查看
一.最大似然估计
选择一个(一组)参数使得实验结果具有最大概率。
A. 如果分布是离散型的,其分布律
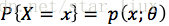
,
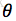
是待估计的参数,这里我们假设
为已知量,则:设X1,
X2, ... , Xn 是来自于X的样本,X1,X2,...Xn的联合分布律为:
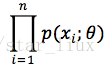
(1)
设x1,x2,...xn是X1,X2,..Xn的一个样本值,则可知X1,..Xn取x1,..,x2的概率,即事件{X1 = x1,...,Xn=xn}发生的概率为:
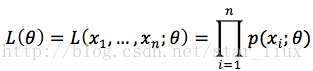
(2)
这里,因为样本值是已知的,所以(2)是
的函数,
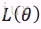
称为样本的似然函数。
最大似然估计:已知样本值x1,...xn,选取一组参数
,使概率
达到最大值,此时的
为最大估计值。即取
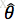
使得:
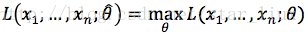
与x1,...,xn有关,记为
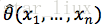
并称其为参数
的极大似然估计值。
B.如果分布X是连续型,其概率密度
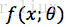
的形式已知,
为待估计参数,则事件X1,...Xn的联合密度为:
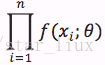
(3)
设x1,..xn为相应X1,...Xn的一个样本值,则随机点(X1,...,Xn)落在(x1,..xn)的领域内的概率近似为:
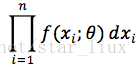
(4)
最大似然估计即为求
值,使得(4)的概率最大。由于
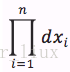
不随
而变,故似然函数为:
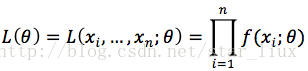
(5)
C. 求最大似然估计参数的步骤:
(1) 写出似然函数:
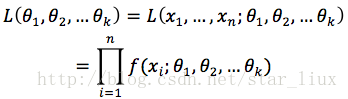
(6)
这里,n为样本数量,似然函数表示n个样本(事件)同时发生的概率。
(2) 对似然函数取对数:
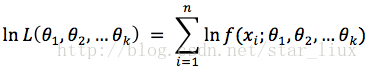
(3) 将对数似然函数对各参数求偏导数并令其为0,得到对数似然方程组。
(4) 从方程组中解出各个参数。
D. 举例:
设
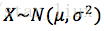
;
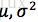
为未知参数,x1,...xn为来自X的一个样本值。求
的极大似然估计值。
解:X的概率密度为:
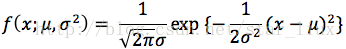
似然函数为:
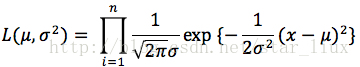
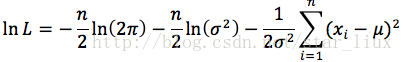
令

即:
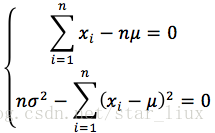
解得:
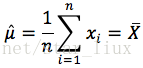
带入解得
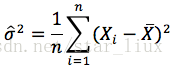
二.逻辑回归
逻辑回归不是回归,而是分类。是从线性回归中衍生出来的分类策略。当y值为只有两个值时(比如0,1),线性回归不能很好的拟合时,用逻辑回归来对其进行二值分类。
这里逻辑函数(S型函数)为:
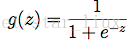
(7)
于是,可得估计函数:
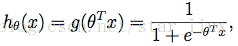
(8)
这里,我们的目的是求出一组
值,使得这组
可以很好的模拟出训练样本的类值。
由于二值分类很像二项分布,我们把单一样本的类值假设为发生概率,则:
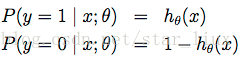
(9)
可以写成概率一般式:
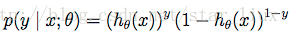
(10)
由最大似然估计原理,我们可以通过m个训练样本值,来估计出
值,使得似然函数值最大:
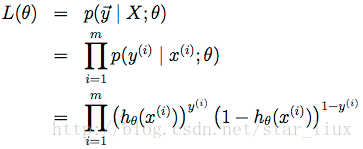
(11)
这里,
为m个训练样本同时发生的概率。对
求log,得:
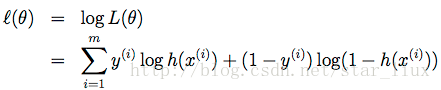
(12)
我们用随机梯度上升法,求使
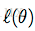
最大化时的
值,迭代函数为:
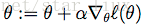
(13)
这里
对每个
分量进行求导,得:
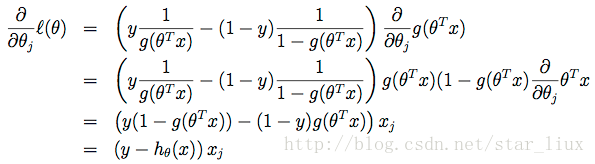
(14)
于是,随机梯度上升法迭代算法为:
repeat until convergence{
for i = 1 to m{
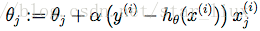
(15)
}
}
思考:
我们求最大似然函数参数的立足点是步骤C,即求出每个参数方向上的偏导数,并让偏导数为0,最后求解此方程组。由于
中参数数量的不确定,考虑到可能参数数量很大,此时直接求解方程组的解变的很困难。于是,我们用随机梯度上升法,求解方程组的值。
备注:
(a) 公式(14)的化简基于g(z)导函数,如下:
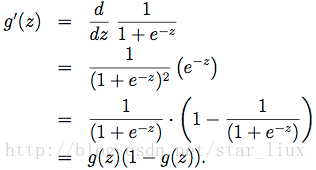
(16)
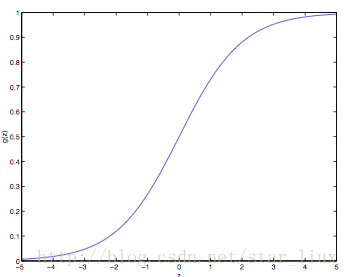
(b) 下图为逻辑函数g(z)的分布图:
选择一个(一组)参数使得实验结果具有最大概率。
A. 如果分布是离散型的,其分布律
,
是待估计的参数,这里我们假设
为已知量,则:设X1,
X2, ... , Xn 是来自于X的样本,X1,X2,...Xn的联合分布律为:
(1)
设x1,x2,...xn是X1,X2,..Xn的一个样本值,则可知X1,..Xn取x1,..,x2的概率,即事件{X1 = x1,...,Xn=xn}发生的概率为:
(2)
这里,因为样本值是已知的,所以(2)是
的函数,
称为样本的似然函数。
最大似然估计:已知样本值x1,...xn,选取一组参数
,使概率
达到最大值,此时的
为最大估计值。即取
使得:
与x1,...,xn有关,记为
并称其为参数
的极大似然估计值。
B.如果分布X是连续型,其概率密度
的形式已知,
为待估计参数,则事件X1,...Xn的联合密度为:
(3)
设x1,..xn为相应X1,...Xn的一个样本值,则随机点(X1,...,Xn)落在(x1,..xn)的领域内的概率近似为:
(4)
最大似然估计即为求
值,使得(4)的概率最大。由于
不随
而变,故似然函数为:
(5)
C. 求最大似然估计参数的步骤:
(1) 写出似然函数:
(6)
这里,n为样本数量,似然函数表示n个样本(事件)同时发生的概率。
(2) 对似然函数取对数:
(3) 将对数似然函数对各参数求偏导数并令其为0,得到对数似然方程组。
(4) 从方程组中解出各个参数。
D. 举例:
设
;
为未知参数,x1,...xn为来自X的一个样本值。求
的极大似然估计值。
解:X的概率密度为:
似然函数为:
令
即:
解得:
带入解得
二.逻辑回归
逻辑回归不是回归,而是分类。是从线性回归中衍生出来的分类策略。当y值为只有两个值时(比如0,1),线性回归不能很好的拟合时,用逻辑回归来对其进行二值分类。
这里逻辑函数(S型函数)为:
(7)
于是,可得估计函数:
(8)
这里,我们的目的是求出一组
值,使得这组
可以很好的模拟出训练样本的类值。
由于二值分类很像二项分布,我们把单一样本的类值假设为发生概率,则:
(9)
可以写成概率一般式:
(10)
由最大似然估计原理,我们可以通过m个训练样本值,来估计出
值,使得似然函数值最大:
(11)
这里,
为m个训练样本同时发生的概率。对
求log,得:
(12)
我们用随机梯度上升法,求使
最大化时的
值,迭代函数为:
(13)
这里
对每个
分量进行求导,得:
(14)
于是,随机梯度上升法迭代算法为:
repeat until convergence{
for i = 1 to m{
(15)
}
}
思考:
我们求最大似然函数参数的立足点是步骤C,即求出每个参数方向上的偏导数,并让偏导数为0,最后求解此方程组。由于
中参数数量的不确定,考虑到可能参数数量很大,此时直接求解方程组的解变的很困难。于是,我们用随机梯度上升法,求解方程组的值。
备注:
(a) 公式(14)的化简基于g(z)导函数,如下:
(16)
(b) 下图为逻辑函数g(z)的分布图:

相关文章推荐
- 用最大似然估计求逻辑回归参数
- 用最大似然估计求逻辑回归参数
- 最大似然估计与逻辑回归
- 最大似然参数估计与贝叶斯参数估计
- 最大似然估计与贝叶斯参数估计
- 模式识别学习笔记(5)——最大似然和贝叶斯参数估计
- 参数估计-最大似然估计和贝叶斯参数估计
- 数学篇----参数估计之最大似然估计法[概率论]
- 最大似然参数估计
- 参数估计之最大似然估计法和贝叶斯估计法(点估计)
- 多元正态分布参数最大似然估计
- 第三章 模式识别 - 最大似然估计和贝叶斯参数估计
- 最大似然参数估计
- 朴素贝叶斯算法的参数的最大似然估计
- 参数估计之最大似然估计
- 模式分类对于最大似然参数估计与贝叶斯参数估计的一些理解
- 玻尔兹曼分布,模拟退火,逻辑回归,最大似然关系
- 参数估计法——最大似然估计和贝叶斯参数估计
- 最大似然估计、贝叶斯估计 两类参数估计的对比
- 最大似然估计学习总结------MadTurtle 1. 作用 在已知试验结果(即是样本)的情况下,用来估计满足这些样本分布的参数,把可能性最大的那个参数clip_image002作为真实cl