使用Flink时遇到的问题(不断更新中)
2017-09-16 22:13
501 查看
1.启动不起来
查看JobManager日志:
解决方案:/etc/hosts中配置的主机名都是小写,但是在Flink配置文件(flink-config.yaml、masters、slaves)中配置的都是大写的hostname,将flink配置文件中的hostname都改为小写或者IP地址
2.运行一段时间退出
解决方案:
状态存储,默认是在内存中,改为存储到HDFS中:
3.长时间运行后,多次重启
解决方案:曾经两次格式化过Namenode,查询了网上的一些文章,虽然异常大致一样,但是每个datanode是正常启动并运行正常,此外namenode中有namespaceID,从节点Datanode中并没有namespaceID,查询到的资料有:
老外的建议:https://stackoverflow.com/questions/5293446/hdfs-error-could-only-be-replicated-to-0-nodes-instead-of-1
百度到的建议:http://blog.sina.com.cn/s/blog_4c248c5801014nd1.html
因为运行时间不长,为了能彻底解决问题,采用了方法一。
4.Unable to load native-hadoop library for your platform
Flink启动时,有时会有如下警告信息:
参考资料1:http://blog.csdn.net/jack85986370/article/details/51902871
解决方案:编辑/etc/profile文件,增加
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
未能解决该问题
5.hadoop checknative -a
参考资料:http://blog.csdn.net/zhangzhaokun/article/details/50951238
解决方案
6.TaskManager退出
Flink运行一段时间后,出现TaskManager退出情况,通过jvisualvm抓取TaskManager的Dump,使用MAT进行分析,结果如下:
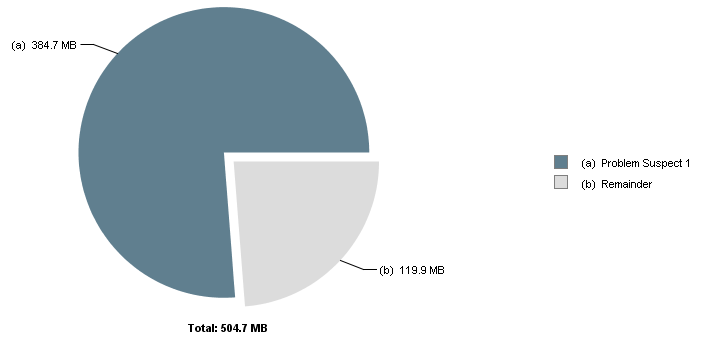
发现是网络缓冲池不足,查到一篇文章:
https://issues.apache.org/jira/browse/FLINK-4536
和我遇到的情况差不多,也是使用了InfluxDB作为Sink,最后在Close里进行关闭,问题解决。
另外,在$FLINK_HOME/conf/flink-conf.yaml中,也有关于TaskManager网络栈的配置,暂时未调整
7.Kafka partition leader切换导致Flink重启
现象:
7.1 Flink重启,查看日志,显示:
7.2 查看Kafka的Controller日志,显示:
7.3 设置retries参数
参考:http://colabug.com/122248.html 以及 Kafka官方文档(http://kafka.apache.org/082/documentation.html#producerconfigs),关于producer参数设置
设置了retries参数,可以在Kafka的Partition发生leader切换时,Flink不重启,而是做3次尝试:
查看JobManager日志:
WARN org.apache.flink.runtime.webmonitor.JobManagerRetriever - Failed to retrieve leader gateway and port. akka.actor.ActorNotFound: Actor not found for: ActorSelection[Anchor(akka.tcp://flink@t-sha1-flk-01:6123/), Path(/user/jobmanager)] at akka.actor.ActorSelection$$anonfun$resolveOne$1.apply(ActorSelection.scala:65) at akka.actor.ActorSelection$$anonfun$resolveOne$1.apply(ActorSelection.scala:63) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:55) at akka.dispatch.BatchingExecutor$Batch.run(BatchingExecutor.scala:73) at akka.dispatch.ExecutionContexts$sameThreadExecutionContext$.unbatchedExecute(Future.scala:74) at akka.dispatch.BatchingExecutor$class.execute(BatchingExecutor.scala:120) at akka.dispatch.ExecutionContexts$sameThreadExecutionContext$.execute(Future.scala:73) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) at akka.pattern.PromiseActorRef$$anonfun$1.apply$mcV$sp(AskSupport.scala:334) at akka.actor.Scheduler$$anon$7.run(Scheduler.scala:117) at scala.concurrent.Future$InternalCallbackExecutor$.unbatchedExecute(Future.scala:599) at scala.concurrent.BatchingExecutor$class.execute(BatchingExecutor.scala:109) at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:597) at akka.actor.LightArrayRevolverScheduler$TaskHolder.executeTask(Scheduler.scala:474) at akka.actor.LightArrayRevolverScheduler$$anon$8.executeBucket$1(Scheduler.scala:425) at akka.actor.LightArrayRevolverScheduler$$anon$8.nextTick(Scheduler.scala:429) at akka.actor.LightArrayRevolverScheduler$$anon$8.run(Scheduler.scala:381) at java.lang.Thread.run(Thread.java:748)
解决方案:/etc/hosts中配置的主机名都是小写,但是在Flink配置文件(flink-config.yaml、masters、slaves)中配置的都是大写的hostname,将flink配置文件中的hostname都改为小写或者IP地址
2.运行一段时间退出
AsynchronousException{java.lang.Exception: Could not materialize checkpoint 4 for operator Compute By Event Time (1/12).}
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:970)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.Exception: Could not materialize checkpoint 4 for operator Compute By Event Time (1/12).
... 6 more
Caused by: java.util.concurrent.ExecutionException: java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size=7061809 , maxSize=5242880 . Consider using a different state backend, like the File System State backend.
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at org.apache.flink.util.FutureUtil.runIfNotDoneAndGet(FutureUtil.java:43)
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:897)
... 5 more
Suppressed: java.lang.Exception: Could not properly cancel managed keyed state future.
at org.apache.flink.streaming.api.operators.OperatorSnapshotResult.cancel(OperatorSnapshotResult.java:90)
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.cleanup(StreamTask.java:1023)
at org.apache.flink.streaming.runtime.tasks.StreamTask$AsyncCheckpointRunnable.run(StreamTask.java:961)
... 5 more
Caused by: java.util.concurrent.ExecutionException: java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size=7061809 , maxSize=5242880 . Consider using a different state backend, like the File System State backend.
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at org.apache.flink.util.FutureUtil.runIfNotDoneAndGet(FutureUtil.java:43)
at org.apache.flink.runtime.state.StateUtil.discardStateFuture(StateUtil.java:85)
at org.apache.flink.streaming.api.operators.OperatorSnapshotResult.cancel(OperatorSnapshotResult.java:88)
... 7 more
Caused by: java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size=7061809 , maxSize=5242880 . Consider using a different state backend, like the File System State backend.
at org.apache.flink.runtime.state.memory.MemCheckpointStreamFactory.checkSize(MemCheckpointStreamFactory.java:64)
at org.apache.flink.runtime.state.memory.MemCheckpointStreamFactory$MemoryCheckpointOutputStream.closeAndGetBytes(MemCheckpointStreamFactory.java:144)
at org.apache.flink.runtime.state.memory.MemCheckpointStreamFactory$MemoryCheckpointOutputStream.closeAndGetHandle(MemCheckpointStreamFactory.java:125)
at org.apache.flink.runtime.checkpoint.AbstractAsyncSnapshotIOCallable.closeStreamAndGetStateHandle(AbstractAsyncSnapshotIOCallable.java:100)
at org.apache.flink.runtime.state.heap.HeapKeyedStateBackend$1.performOperation(HeapKeyedStateBackend.java:351)
at org.apache.flink.runtime.state.heap.HeapKeyedStateBackend$1.performOperation(HeapKeyedStateBackend.java:329)
at org.apache.flink.runtime.io.async.AbstractAsyncIOCallable.call(AbstractAsyncIOCallable.java:72)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.flink.runtime.state.heap.HeapKeyedStateBackend.snapshot(HeapKeyedStateBackend.java:372)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.snapshotState(AbstractStreamOperator.java:397)
at org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.checkpointStreamOperator(StreamTask.java:1162)
at org.apache.flink.streaming.runtime.tasks.StreamTask$CheckpointingOperation.executeCheckpointing(StreamTask.java:1094)
at org.apache.flink.streaming.runtime.tasks.StreamTask.checkpointState(StreamTask.java:654)
at org.apache.flink.streaming.runtime.tasks.StreamTask.performCheckpoint(StreamTask.java:590)
at org.apache.flink.streaming.runtime.tasks.StreamTask.triggerCheckpointOnBarrier(StreamTask.java:543)
at org.apache.flink.streaming.runtime.io.BarrierBuffer.notifyCheckpoint(BarrierBuffer.java:378)
at org.apache.flink.streaming.runtime.io.BarrierBuffer.processBarrier(BarrierBuffer.java:281)
at org.apache.flink.streaming.runtime.io.BarrierBuffer.getNextNonBlocked(BarrierBuffer.java:183)
at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:213)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:263)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:702)
... 1 more
[CIRCULAR REFERENCE:java.io.IOException: Size of the state is larger than the maximum permitted memory-backed state. Size=7061809 , maxSize=5242880 . Consider using a different state backend, like the File System State backend.]解决方案:
状态存储,默认是在内存中,改为存储到HDFS中:
state.backend.fs.checkpointdir: hdfs://t-sha1-flk-01:9000/flink-checkpoints
3.长时间运行后,多次重启
WARN org.apache.hadoop.hdfs.DFSClient - DataStreamer Exception org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /flink-checkpoints/8c7bff5382a5158b7279bbe5de075c77/chk-238/30357bf3-807b-4458-9e19-e86fa101dbd1 could only be replicated to 0 nodes instead of minReplication (=1). There are 3 datanode(s) running and no node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1571) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getNewBlockTargets(FSNamesystem.java:3107) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3031) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:725) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:492) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2049) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2045) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2043) at org.apache.hadoop.ipc.Client.call(Client.java:1475) at org.apache.hadoop.ipc.Client.call(Client.java:1412) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229) at com.sun.proxy.$Proxy12.addBlock(Unknown Source) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:418) at sun.reflect.GeneratedMethodAccessor22.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102) at com.sun.proxy.$Proxy13.addBlock(Unknown Source) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1459) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1255) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:449)
解决方案:曾经两次格式化过Namenode,查询了网上的一些文章,虽然异常大致一样,但是每个datanode是正常启动并运行正常,此外namenode中有namespaceID,从节点Datanode中并没有namespaceID,查询到的资料有:
老外的建议:https://stackoverflow.com/questions/5293446/hdfs-error-could-only-be-replicated-to-0-nodes-instead-of-1
stop all hadoop services delete dfs/name and dfs/data directories hadoop namenode -format # Answer with a capital Y start hadoop services
百度到的建议:http://blog.sina.com.cn/s/blog_4c248c5801014nd1.html
第一种方法是删除DataNode的所有资料(及将集群中每个datanode的/hdfs/data/current中的VERSION删掉,然后执行hadoop namenode -format重启集群,错误消失。<推荐>); 第二种方法是修改每个DataNode的namespaceID(位于/hdfs/data/current/VERSION文件中)<优先>或修改NameNode的namespaceID(位于/hdfs/name/current/VERSION文件中),使其一致。
因为运行时间不长,为了能彻底解决问题,采用了方法一。
4.Unable to load native-hadoop library for your platform
Flink启动时,有时会有如下警告信息:
WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
参考资料1:http://blog.csdn.net/jack85986370/article/details/51902871
解决方案:编辑/etc/profile文件,增加
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
未能解决该问题
5.hadoop checknative -a
WARN bzip2.Bzip2Factory: Failed to load/initialize native-bzip2 library system-native, will use pure-Java version INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library Native library checking: hadoop: true /usr/hadoop-2.7.3/lib/native/libhadoop.so.1.0.0 zlib: true /lib64/libz.so.1 snappy: false lz4: true revision:99 bzip2: false openssl: false Cannot load libcrypto.so (libcrypto.so: cannot open shared object file: No such file or directory)! INFO util.ExitUtil: Exiting with status 1
参考资料:http://blog.csdn.net/zhangzhaokun/article/details/50951238
解决方案
cd /usr/lib64/ ln -s libcrypto.so.1.0.1e libcrypto.so
6.TaskManager退出
Flink运行一段时间后,出现TaskManager退出情况,通过jvisualvm抓取TaskManager的Dump,使用MAT进行分析,结果如下:
One instance of "org.apache.flink.runtime.io.network.buffer.NetworkBufferPool" loaded by "sun.misc.Launcher$AppClassLoader @ 0x6c01de310" occupies 403,429,704 (76.24%) bytes. The memory is accumulated in one instance of "java.lang.Object[]" loaded by "<system class loader>". Keywords sun.misc.Launcher$AppClassLoader @ 0x6c01de310 java.lang.Object[] org.apache.flink.runtime.io.network.buffer.NetworkBufferPool
发现是网络缓冲池不足,查到一篇文章:
https://issues.apache.org/jira/browse/FLINK-4536
和我遇到的情况差不多,也是使用了InfluxDB作为Sink,最后在Close里进行关闭,问题解决。
另外,在$FLINK_HOME/conf/flink-conf.yaml中,也有关于TaskManager网络栈的配置,暂时未调整
# The number of buffers for the network stack. # # taskmanager.network.numberOfBuffers: 2048
7.Kafka partition leader切换导致Flink重启
现象:
7.1 Flink重启,查看日志,显示:
java.lang.Exception: Failed to send data to Kafka: This server is not the leader for that topic-partition. at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase.checkErroneous(FlinkKafkaProducerBase.java:373) at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducerBase.invoke(FlinkKafkaProducerBase.java:280) at org.apache.flink.streaming.api.operators.StreamSink.processElement(StreamSink.java:41) at org.apache.flink.streaming.runtime.io.StreamInputProcessor.processInput(StreamInputProcessor.java:206) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.run(OneInputStreamTask.java:69) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:263) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:702) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
7.2 查看Kafka的Controller日志,显示:
INFO [SessionExpirationListener on 10], ZK expired; shut down all controller components and try to re-elect (kafka.controller.KafkaController$SessionExpirationListener)
7.3 设置retries参数
参考:http://colabug.com/122248.html 以及 Kafka官方文档(http://kafka.apache.org/082/documentation.html#producerconfigs),关于producer参数设置
设置了retries参数,可以在Kafka的Partition发生leader切换时,Flink不重启,而是做3次尝试:
kafkaProducerConfig
{
"bootstrap.servers": "192.169.2.20:9093,192.169.2.21:9093,192.169.2.22:9093"
"retries":3
}

相关文章推荐
- linux使用过程中遇到的问题记录(不断更新)
- 使用elasticsearch遇到的一些问题以及解决方法(不断更新)
- 使用elasticsearch遇到的一些问题以及解决方法(不断更新)
- 使用用户控件遇到的小问题,不断更新
- 生产环境使用elasticsearch遇到的一些问题以及解决方法(不断更新)
- SQLSERVER2000使用中遇到的一些小问题,不断更新中。。。
- 生产环境使用elasticsearch遇到的一些问题以及解决方法(不断更新)
- 生产环境使用elasticsearch遇到的一些问题以及解决方法(不断更新)
- Loadrunner使用遇到的问题总汇,不断更新~
- 生产环境使用elasticsearch遇到的一些问题以及解决方法(不断更新)
- android中遇到的一些问题整理--不断更新中
- 使用VS2010时遇到的一些小问题的解决方案(从各处搜罗总结的,不定期更新,向原作者致敬)
- linux中遇到的问题和解决(不断更新)
- 遇到的一些问题及解决方法(不断更新)
- 使用Linq 更新数据库时遇到的一些问题及解决办法
- linux中遇到的问题和解决(不断更新)
- Jpa项目使用中遇到的问题总汇——更新中
- ubuntu11.0.4下编译Android2.3源码过程遇到问题解决【不断更新】
- 使用oracle中遇到的各种问题【持续更新】
- 使用mssql2008新特性(存储过程参数类型使用"用户自定义表"来实现批量DML更新多表)解决项目里遇到的性能问题