Kafka+Storm+HBase项目Demo(4)--Kafka使用
2017-09-09 19:38
423 查看
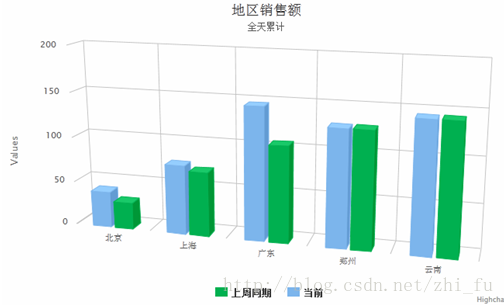
第一个需求是按地区实时计算销售额,并进行3D柱图实时展示结果,含周同比。图表的数据3s自动更新。
期望效果
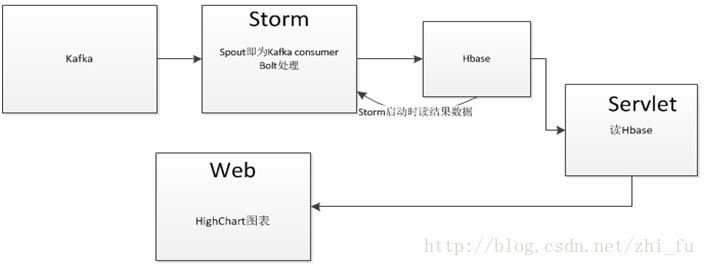
项目的架构:
从Kafka开始。这里介绍Kafka一些概念。
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
Topics/logs
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
Producers
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于”round-robin”方式或者通过其他的一些算法等.
Consumers
本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费.
如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡.
如果所有的consumer都具有不同的group,那这就是”发布-订阅”;消息将会广播给所有的消费者.
在kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个”订阅”者,一个Topic中的每个partions,只会被一个”订阅者”中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的.事实上,从Topic角度来说,消息仍不是有序的.
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息.
首先,我们建立一个Kafka 配置类,生产者消费者共用
现在需要生产者生成测试数据,就是一些关于各个地区销售额的随机数
这里需要测试数据能否生产出来,所以需要做一个消费者来test。
期望效果
项目的架构:
从Kafka开始。这里介绍Kafka一些概念。
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
Topics/logs
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
Producers
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于”round-robin”方式或者通过其他的一些算法等.
Consumers
本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费.
如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡.
如果所有的consumer都具有不同的group,那这就是”发布-订阅”;消息将会广播给所有的消费者.
在kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个”订阅”者,一个Topic中的每个partions,只会被一个”订阅者”中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的.事实上,从Topic角度来说,消息仍不是有序的.
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息.
首先,我们建立一个Kafka 配置类,生产者消费者共用
package kafka.productor;
public interface KafkaProperties
{
final static String zkConnect = "192.168.1.107:2181,192.168.1.108:2181";
final static String broker_list = "192.168.1.107:9092,192.168.1.108:9092" ;
final static String groupId = "group1";
final static String topic = "track";
final static String Order_topic = "track";
}现在需要生产者生成测试数据,就是一些关于各个地区销售额的随机数
package kafka.productor;
import java.util.Properties;
import java.util.Random;
import cloudy.tools.DateFmt;
import backtype.storm.utils.Utils;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class Producer extends Thread {
private final kafka.javaapi.producer.Producer<Integer, String> producer;
private final String topic;
private final Properties props = new Properties();
public Producer(String topic) {
props.put("serializer.class
c199
", "kafka.serializer.StringEncoder");// 字符串消息
props.put("metadata.broker.list",KafkaProperties.broker_list);
producer = new kafka.javaapi.producer.Producer<Integer, String>(
new ProducerConfig(props));
this.topic = topic;
}
public void run() {
// order_id,order_amt,create_time,area_id
Random random = new Random();
String[] order_amt = { "10.10", "20.10", "50.2","60.0", "80.1" };
String[] area_id = { "1","2","3","4","5" };
int i =0 ;
while(true) {
i ++ ;
String messageStr = i+"\t"+order_amt[random.nextInt(5)]+"\t"+DateFmt.getCountDate(null, DateFmt.date_long)+"\t"+area_id[random.nextInt(5)] ;
System.out.println("product:"+messageStr);
producer.send(new KeyedMessage<Integer, String>(topic, messageStr));
Utils.sleep(1000) ;
}
}
public static void main(String[] args) {
Producer producerThread = new Producer(KafkaProperties.Order_topic);
producerThread.start();
}
}这里需要测试数据能否生产出来,所以需要做一个消费者来test。
package kafka.consumers;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.productor.KafkaProperties;
public class OrderConsumer extends Thread {
private final ConsumerConnector consumer;
private final String topic;
private Queue<String> queue = new ConcurrentLinkedQueue<String>() ;
public OrderConsumer(String topic) {
consumer = kafka.consumer.Consumer
.createJavaConsumerConnector(createConsumerConfig());
this.topic = topic;
}
private static ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
props.put("zookeeper.connect", KafkaProperties.zkConnect);
props.put("group.id", KafkaProperties.groupId);
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "2000");
props.put("auto.commit.interval.ms", "1000");//
return new ConsumerConfig(props);
}
public void run() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer
.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext()){
//逻辑处理
System.out.println("consumer:"+new String(it.next().message()));
queue.add(new String(it.next().message())) ;
}
}
public Queue<String> getQueue()
{
return queue ;
}
public static void main(String[] args) {
OrderConsumer consumerThread = new OrderConsumer(KafkaProperties.Order_topic);
consumerThread.start();
}
}

相关文章推荐
- Kafka+Storm+HBase项目Demo(5)--topology,spout,bolt使用
- Kafka+Storm+HBase项目Demo(7)--Trident使用
- Kafka+Storm+HBase项目Demo(6)--前端HTTP长连接实现
- Kafka+Storm+HBase项目Demo(2)--Kafka环境搭建
- Kafka+Storm+HBase项目Demo(1)--CDH搭建hadoop集群
- Kafka+Storm+HBase项目Demo(3)--Storm安装配置
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
- JFinal使用笔记1-部署demo项目到本地tomcat
- kafka, storm,hdfs日志处理方法(附storm-kafka, storm-hdfs使用方法)
- Storm-Kafka模块之写入kafka-KafkaBolt的使用及实现
- 使用maven创建web项目demo
- HBase与WordCount的结合使用Demo
- 大数据处理 Hadoop、HBase、ElasticSearch、Storm、Kafka、Spark
- HDFS HA、YARN HA、Zookeeper、HBase HA、Mysql、Hive、Sqool、Flume-ng、storm、kafka、redis、mongodb、spark安装
- 105-storm 整合 kafka之保存HBase数据库
- hbase java api 使用demo
- GitHub项目Storm-HBase介绍
- httpclient 无信任证书直接使用https含项目demo