Python开发简单爬虫
2017-09-07 00:00
381 查看
本文在学习慕课网 疯狂的蚂蚁crazyant 的课程后写作,文中截图部分来自于视频,感谢视频作者。大家也可以通过点击这里观看视频学习,老师讲得贼棒!
URL管理器记录爬取过的URL和未爬取的URL
从URL管理器中获取一个未爬取的URL下载网页内容
解析爬取到的内容,将价值数据存储起来,将爬到的新URL传递给URL管理器存储为未爬取的URL,并从2开始循环执行
防止循环抓取。如果A网页包含B网页的链接,B网页包含A网页的链接,可能导致无限循环。每次添加URL时,判断未爬取URL集合、已爬取URL集合可以避免
判断是否还有未爬取的URL
获取一个待爬取的URL,该功能需要从未爬取的URL集合中删除该URL,并添加到已爬取的URL集合中
使用Mysql等数据库存储
使用Redis等,也可以使用两个Set分别表示
添加data、http header

添加特殊情景的处理器(HTTPCookieProcessor、ProxyHandler、HTTPSHandler、HTTPRedirectHandler)
以添加HTTPCookieProcessor为例:
html.parser:Python自带的解析器
lxml:第三方插件,可以解析html和xml
Beautiful:第三方插件,它既可以使用html.parser作为解析器,也可以使用lxml作为解析器,功能比较强大,推荐使用
其中,正则表达式是基于文本的模糊匹配;其他3种方式将网页文档解析为DOM树解析。
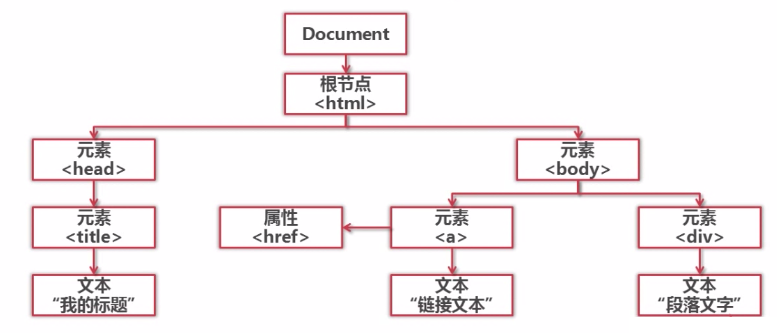
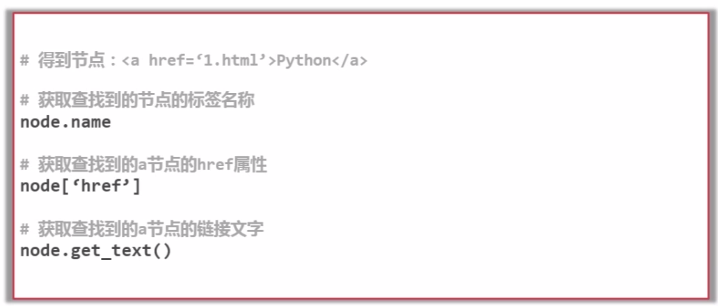
获取节点,可以通过节点名称、属性值、文字搜索节点。
访问节点,获取节点的名称、属性、文字的值。

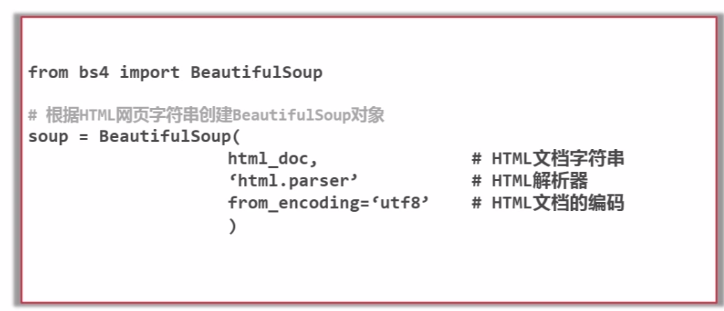
搜索节点(find_all,find)
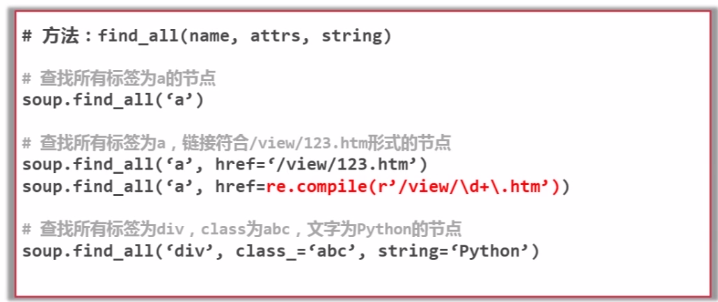
访问节点信息
也就是说:我们需要扒取哪个网站和哪些数据。
本实例我们确定要抓取百度百科“python”词条这个页面和它相关的页面,数据包括页面内的关键词、简介。
分析目标
URL格式,用来限定抓取页面的范围
本实例抓取的URL是页面中的其他词条的超链接,格式类似于
抓取的数据格式,用于存储数据
本实例都是字符串格式的数据
确定编码,确保程序中的编码格式
百度百科网页使用
编写代码
执行爬虫
URL管理器
网页下载器
网页解析器
数据输出器
文章除注明转载外,均为原创。欢迎任何形式的转载,但请务必注明出处:
文章转载自 OSchina 开源中国
本文作者:dotleo
作者主页:https://my.oschina.net/u/2930289/blog
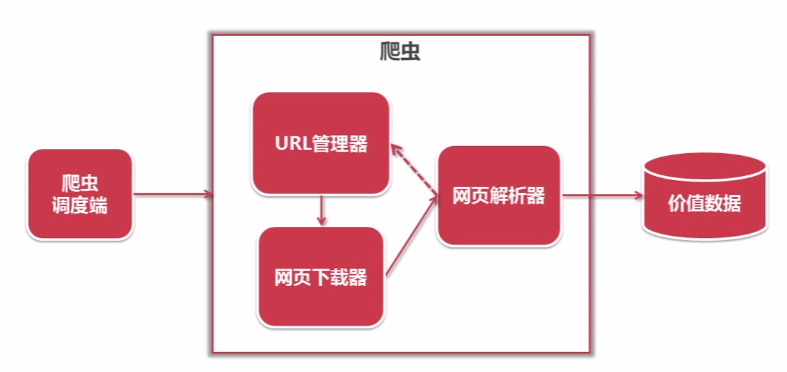
What's 爬虫
通俗的讲,爬虫就是通过一个URL开始,自动获取数据的“网络机器人”。简单的爬虫架构
URL管理器记录爬取过的URL和未爬取的URL
从URL管理器中获取一个未爬取的URL下载网页内容
解析爬取到的内容,将价值数据存储起来,将爬到的新URL传递给URL管理器存储为未爬取的URL,并从2开始循环执行
URL管理器
存储未爬取的URL和爬取过的URL作用
防止重复抓取。爬取过后的URL存在已爬取URL集合中,不再去访问防止循环抓取。如果A网页包含B网页的链接,B网页包含A网页的链接,可能导致无限循环。每次添加URL时,判断未爬取URL集合、已爬取URL集合可以避免
需要实现的功能
可以添加新的URL到未爬取集合中,该功能需要判断新的URL是否在URL管理器容器中判断是否还有未爬取的URL
获取一个待爬取的URL,该功能需要从未爬取的URL集合中删除该URL,并添加到已爬取的URL集合中
实现方式
使用Python,用两个Set分别表示使用Mysql等数据库存储
使用Redis等,也可以使用两个Set分别表示
网页下载器
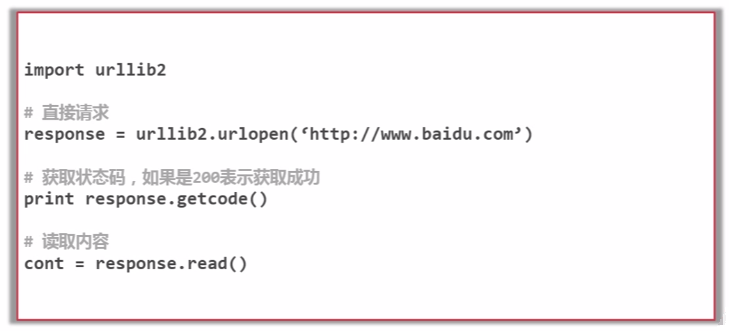
将互联网上URL对应的网页下载到本地的工具,本文介绍Python自带库“urllib2”"urllib2"使用方法
最简单的使用方法添加data、http header
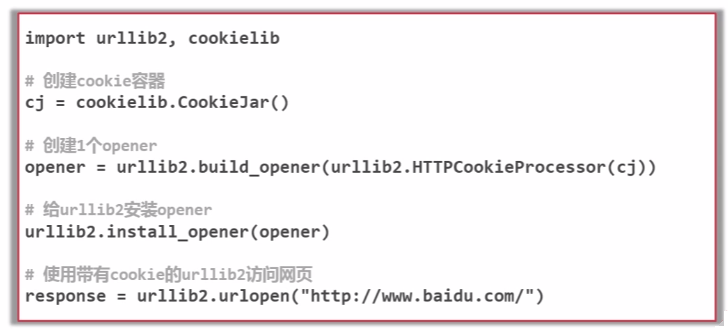
添加特殊情景的处理器(HTTPCookieProcessor、ProxyHandler、HTTPSHandler、HTTPRedirectHandler)
以添加HTTPCookieProcessor为例:
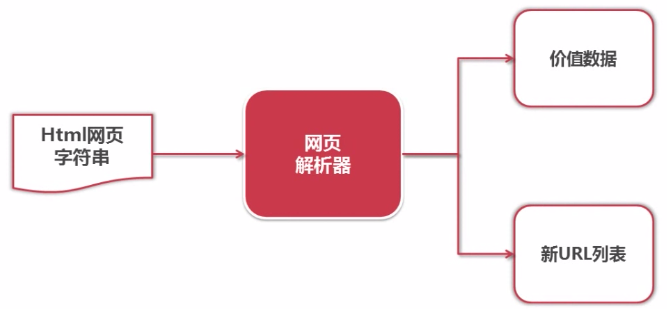
网页解析器
网页解析器是从网页中提取有价值数据的工具。常见的几种网页解析器
正则表达式:可以模糊匹配网页字符串里中的内容,在比较复杂的数据中非常麻烦html.parser:Python自带的解析器
lxml:第三方插件,可以解析html和xml
Beautiful:第三方插件,它既可以使用html.parser作为解析器,也可以使用lxml作为解析器,功能比较强大,推荐使用
其中,正则表达式是基于文本的模糊匹配;其他3种方式将网页文档解析为DOM树解析。
Beautiful Soup介绍
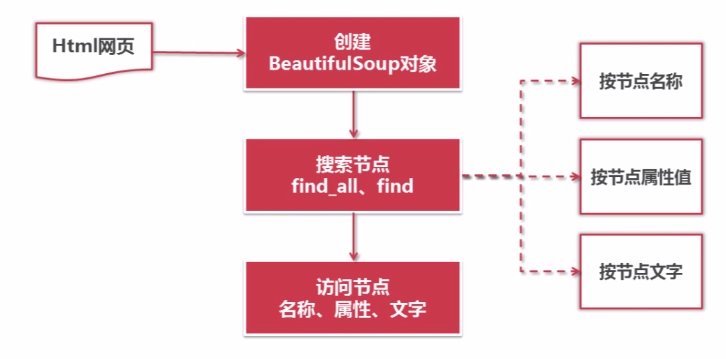
官网:https://www.crummy.com/software/BeautifulSoup/对Beautiful Soup进行操作的一般步骤
先根据HTML网页字符串创建Beautiful Soup对象。获取节点,可以通过节点名称、属性值、文字搜索节点。
find_all会搜索所有满足要求的节点,
find搜索出满足要求的第一个节点。
访问节点,获取节点的名称、属性、文字的值。
函数介绍
创建Beautiful Soup对象搜索节点(find_all,find)
访问节点信息
爬虫实例
分析
确定目标也就是说:我们需要扒取哪个网站和哪些数据。
本实例我们确定要抓取百度百科“python”词条这个页面和它相关的页面,数据包括页面内的关键词、简介。
分析目标
URL格式,用来限定抓取页面的范围
本实例抓取的URL是页面中的其他词条的超链接,格式类似于
<a href="/item/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1%E8%AF%AD%E8%A8%80">计算机程序设计语言</a>
抓取的数据格式,用于存储数据
本实例都是字符串格式的数据
确定编码,确保程序中的编码格式
百度百科网页使用
utf-8编码,所以在编写代码中注意转码
编写代码
执行爬虫
编码
主模块# -*- coding:utf-8 -*- import url_manager import html_downloader import html_parser import html_outputer class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() # 初始化URL管理器 self.downloader = html_downloader.HtmlDownloader() # 初始化网页下载器 self.parser = html_parser.HtmlParser() # 初始化网页解析器 self.outputer = html_outputer.HtmlOutputer() # 初始化数据输出器 def craw(self,root_url): count = 1 # 记录成功条数 self.urls.add_new_url(root_url) # 添加url到url管理器 while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() # 获取未爬过的url print 'craw %d : %s' %(count, new_url) html_cont = self.downloader.download(new_url) # 根据url下载网页 new_urls, new_data = self.parser.parse(new_url, html_cont) # 解析网页内容 self.urls.add_new_urls(new_urls) # 将爬到的新网址添加到url管理器 self.outputer.collect_data(new_data) # 将内容添加到数据输出器 if count == 1000: break count = count + 1 except: print 'craw failed' self.outputer.output_html() # 输出内容 # main函数 if __name__ == '__main__': root_url = 'https://baike.baidu.com/item/Python' # 最开始的url obj_spider = SpiderMain() obj_spider.craw(root_url)
URL管理器
# -*- coding:utf-8 -*- # URL管理器 class UrlManager(object): def __init__(self): self.new_urls = set() # 存放未读取url self.old_urls = set() # 存放已读取url # 添加一个url到未读url列表 def add_new_url(self, url): if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) # 添加多个url到未读url列表 def add_new_urls(self, urls): if urls is None or len(urls) == 0: return for url in urls: self.add_new_url(url) # 返回是否有未读url def has_new_url(self): return len(self.new_urls) != 0 # 随机获取一个未读url def get_new_url(self): new_url = self.new_urls.pop() # 获取未读url并删除 self.old_urls.add(new_url) # 添加这个url到已读url列表中 return new_url
网页下载器
# -*- coding:utf-8 -*- import urllib2 # 网页下载器 class HtmlDownloader(object): # 获取服务器响应内容 def download(self,url): if url is None: return None response = urllib2.urlopen(url) if response.getcode() != 200: # 获取成功标识 return None return response.read()
网页解析器
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import re
# 网页解析器
class HtmlParser(object):
# 获取其中的url
def __get_new_urls(self,page_url, soup):
new_urls = set()
links = soup.find_all('a', href=re.compile(r'/item/[a-zA-Z0-9%]+')) # 匹配url,可能会发生变化
for link in links:
new_url = link['href'].encode('utf-8') # 获取url
new_full_url = 'https://baike.baidu.com'+new_url # 拼接url
new_urls.add(new_full_url)
return new_urls
# 获取其中的内容(关键词,简介)
def __get_new_data(self,page_url,soup):
res_data = {}
res_data['url'] = page_url
# 获取关键词
title_node = soup.find('dd', class_ = 'lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
# 获取简介
summary_node = soup.find('div', class_ = 'lemma-summary')
res_data['summary'] = summary_node.get_text()
return res_data
# 解析htnl字符串
def parse(self,page_url,html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8')
new_urls = self.__get_new_urls(page_url, soup)
new_data = self.__get_new_data(page_url, soup)
return new_urls, new_data数据输出器
# -*- coding:utf-8 -*-
# 数据输出器
class HtmlOutputer(object):
def __init__(self):
self.datas = list()
# 添加数据到列表中
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
# 输出到html文件中
def output_html(self):
fout = open(r'output.html','w')
fout.write('<html>')
fout.write('<body>')
fout.write('<table>')
for data in self.datas:
fout.write('<tr>')
fout.write('<td>%s</td>' % data['url'])
fout.write('<td>%s</td>' % data['title'].encode('utf-8'))
fout.write('<td>%s</td>' % data['summary'].encode('utf-8'))
fout.write('</tr>')
fout.write('</table>')
fout.write('</body>')
fout.write('</html>')
fout.close()文章除注明转载外,均为原创。欢迎任何形式的转载,但请务必注明出处:
文章转载自 OSchina 开源中国
本文作者:dotleo
作者主页:https://my.oschina.net/u/2930289/blog

相关文章推荐
- python 开发简单爬虫 by CL(一)
- Python 开发简单爬虫 - 实战演练
- Python开发简单爬虫(一)
- python开发简单爬虫
- Python 开发简单爬虫 学习笔记1
- Python开发简单爬虫--学习笔记
- Python开发简单爬虫学习笔记(1)
- python简单爬虫开发(urllib2、requests + BeautifulSoup)
- 【Python开发】【神经网络与深度学习】如何利用Python写简单网络爬虫
- python_慕课\Python开发简单爬虫\5-3 Python爬虫urlib2实例代码.py
- python_慕课\Python开发简单爬虫\7-7 开始运行爬虫和爬取结果展.py
- Python开发简单爬虫
- python 开发简单爬虫
- Python开发简单爬虫 - 慕课网
- python3 开发简单爬虫
- Python简单爬虫开发的学习笔记整理(爬取百度百科词条)
- Python开发简单爬虫
- Python开发简单爬虫之爬虫介绍(一)
- Python开发简单爬虫之实战演练
- Python开发简单爬虫(二)