Hadoop2.7.4 MapReduce集群的Linux安装步骤
2017-09-06 19:30
405 查看
一、 目标
Hadoop2.X MapReduce集群搭建
操作系统:
CentOS Linux release 7.3.1611
服务器集群:
Node-0: 192.168.2.200
Node-1: 192.168.2.201
Node-2: 192.168.2.202
Node-3: 192.168.2.203
Node-4: 192.168.2.204
Node-5: 192.168.2.205
节点:
NN: NameNode
DN: DataNode
ZK: Zookeeper
ZKFC: Zookeeper Failover Controller
JN: JournalNoe
RM: YARN ResourceManager
DM: DataManager
部署规划:
二、 MapReduce配置
1. 修改etc/hadoop/mapred-site.xml,指定yarn为Hadoop的执行框架
2. 修改etc/hadoop/yarn-site.xml(设置RM主机,为MapReduce设置Shuffle服务)
3. 将之前HDFS服务停止
4. 将配置文件拷贝至集群其他节点
5. 启动集群(HDFS与MapReduce均启动)
实际上是start-dfs.sh和start-yarn.sh
jps与节点规划表中的节点进行对比
部署规划:
三、 测试
1. 浏览器访问RM节点http://node0:8088/
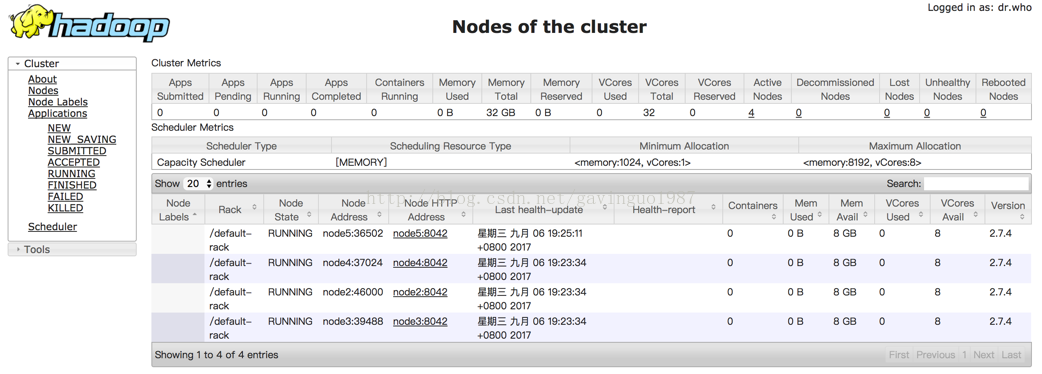
Hadoop2.X MapReduce集群搭建
操作系统:
CentOS Linux release 7.3.1611
服务器集群:
Node-0: 192.168.2.200
Node-1: 192.168.2.201
Node-2: 192.168.2.202
Node-3: 192.168.2.203
Node-4: 192.168.2.204
Node-5: 192.168.2.205
节点:
NN: NameNode
DN: DataNode
ZK: Zookeeper
ZKFC: Zookeeper Failover Controller
JN: JournalNoe
RM: YARN ResourceManager
DM: DataManager
部署规划:
| | NN | DN | ZK | ZKFC | JN | RM | DM |
| Node-0 | 1 | | 1 | 1 | | 1 | |
| Node-1 | 1 | | 1 | 1 | | | |
| Node-2 | | 1 | 1 | | 1 | | 1 |
| Node-3 | | 1 | 1 | | 1 | | 1 |
| Node-4 | | 1 | 1 | | 1 | | 1 |
| Node-5 | | 1 | | | | | 1 |
二、 MapReduce配置
1. 修改etc/hadoop/mapred-site.xml,指定yarn为Hadoop的执行框架
| /home/hadoop/hadoop2.7/etc/hadoop cp mapred-site.xml.template mapred-site.xml vi mapred-site.xml |
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
2. 修改etc/hadoop/yarn-site.xml(设置RM主机,为MapReduce设置Shuffle服务)
| cd /home/hadoop/hadoop2.7/etc/hadoop vi yarn-site.xml |
| <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>node0</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration> |
3. 将之前HDFS服务停止
| ssh node0 cd /home/hadoop/hadoop2.7/sbin/ ./stop-dfs.sh exit |
4. 将配置文件拷贝至集群其他节点
| cd /home/hadoop/hadoop2.7/etc/hadoop/ scp ./* root@node1:/home/hadoop/hadoop2.7/etc/hadoop/ scp ./* root@node2:/home/hadoop/hadoop2.7/etc/hadoop/ scp ./* root@node3:/home/hadoop/hadoop2.7/etc/hadoop/ scp ./* root@node4:/home/hadoop/hadoop2.7/etc/hadoop/ scp ./* root@node5:/home/hadoop/hadoop2.7/etc/hadoop/ |
5. 启动集群(HDFS与MapReduce均启动)
实际上是start-dfs.sh和start-yarn.sh
| ssh node0 cd /home/hadoop/hadoop2.7/sbin/ ./start-all.sh exit |
| This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [node0 node1] node0: starting namenode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-namenode-gyrr-centos-node-0.out node1: starting namenode, 4000 logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-namenode-gyrr-centos-node-1.out node2: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-datanode-gyrr-centos-node-2.out node4: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-datanode-gyrr-centos-node-4.out node3: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-datanode-gyrr-centos-node-3.out node5: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-datanode-GYRR-CentOS-Node-5.out Starting journal nodes [node2 node3 node4] node3: starting journalnode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-journalnode-gyrr-centos-node-3.out node4: starting journalnode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-journalnode-gyrr-centos-node-4.out node2: starting journalnode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-journalnode-gyrr-centos-node-2.out Starting ZK Failover Controllers on NN hosts [node0 node1] node0: starting zkfc, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-zkfc-gyrr-centos-node-0.out node1: starting zkfc, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-zkfc-gyrr-centos-node-1.out starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop-2.7.4/logs/yarn-root-resourcemanager-gyrr-centos-node-0.out node4: starting nodemanager, logging to /usr/local/hadoop-2.7.4/logs/yarn-root-nodemanager-gyrr-centos-node-4.out node2: starting nodemanager, logging to /usr/local/hadoop-2.7.4/logs/yarn-root-nodemanager-gyrr-centos-node-2.out node5: starting nodemanager, logging to /usr/local/hadoop-2.7.4/logs/yarn-root-nodemanager-GYRR-CentOS-Node-5.out node3: starting nodemanager, logging to /usr/local/hadoop-2.7.4/logs/yarn-root-nodemanager-gyrr-centos-node-3.out |
部署规划:
| | NN | DN | ZK | ZKFC | JN | RM | DM |
| Node-0 | 1 | | 1 | 1 | | 1 | |
| Node-1 | 1 | | 1 | 1 | | | |
| Node-2 | | 1 | 1 | | 1 | | 1 |
| Node-3 | | 1 | 1 | | 1 | | 1 |
| Node-4 | | 1 | 1 | | 1 | | 1 |
| Node-5 | | 1 | | | | | 1 |
三、 测试
1. 浏览器访问RM节点http://node0:8088/

相关文章推荐
- Hadoop2.7.4集群的Linux安装步骤
- linux hadoop 集群安装步骤
- Linux下Hadoop集群安装详细步骤
- Linux下Hadoop集群安装详细步骤
- Linux下Hadoop集群安装详细步骤 .
- Linux中安装配置hadoop集群详细步骤
- CDH5 Hadoop集群完全离线安装步骤总结
- hadoop2.7.4在ubuntu16桌面版上的集群安装
- Linux下Hadoop集群环境的安装配置
- Hive之 hive-1.2.1 + hadoop 2.7.4 集群安装
- 32位LINUX下hadoop2.2.0重新编译及安装步骤
- Hadoop的安装---在真实的linux集群上安装
- hadoop集群详细安装步骤(hadoop.2.7.3)
- Hadoop化繁为简-从安装Linux到搭建集群环境
- 集群分布式 Hadoop安装详细步骤
- Linux上安装Hadoop集群(CentOS7+hadoop-2.8.0)
- Hadoop2.7.4集群安装
- Linux平台下安装和配置Hadoop集群
- Linux安装hadoop步骤
- hadoop集群的安装步骤和配置