历程剖析:阿里云自研HTAP数据库的技术发展之路
2017-09-05 15:19
471 查看
点击查看全文
8月24日,阿里云数据库技术峰会到来,本次技术峰会邀请到了阿里集团和阿里云数据库老司机们,为大家分享了一线数据库实践经验和技术干货。阿里云高级数据库技术专家队皓庭分享了高度兼容MySQL,并且能免去传统数仓ETL过程实现数据分析,同时支持高并发、大吞吐量的在线事务处理的PB级数据存储数据库是如何实现的,帮助大家了解了同时支持海量数据在线事务(OLTP)和在线分析(OLAP)的HTAP关系型数据库是如何打造出来的。
本文将介绍HybridDB for MySQL的定位和现状,以及其技术演进路线和尚待解决的问题。
一、产品现状

HybridDB for MySQL在RDS MySQL的基础上做了很多拓展和改进,同时也保留了一些传统关系型数据库的特性。Hybrid是在2005年提出的HTAP数据库的概念,指混合的事务和分析处理。传统的数据库因为各方面的限制,偏向于OLTP或OLAP的场景,两者很难兼得,目前也只有Oracle勉强地解决了这个问题。但是在更大的数据场景下,因为Oracle产品价格高昂,一般用户往往难以承担。而MySQL在国内外拥有很高的知名度和用户量,从这个生态出发可以让阿里云研发团队收获更多的产品改进思路。HybridDB
for MySQL从个角度出发,提供一种高性价比、大数据库的产品,在解决OLTP和OLAP业务的同时,维持好MySQL的生态。
HybridDB for MySQL在SQL兼容性方面做了很多的扩展,包括支持了TPC-H和TPC-DS这两个OLAP领域的测试集。由于是阿里云的云数据库服务,HybridDB for MySQL继承了RDS的云服务特征,高可靠、高可用等特性一应俱全并支持在线的扩容。目前HybridDB for MySQL的线上服务规模遍及国内外十多个region,为阿里云及外部的用户提供了可靠服务,总数据量已经达到TB级,日新增数据达百T级。
二、产品定位
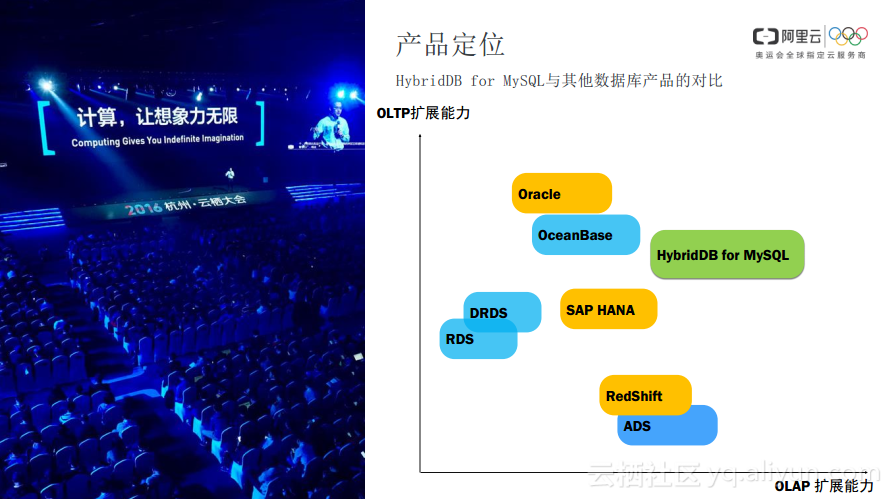
HybridDB for MySQL的定位是使用一份数据同时支持OLTP和OLAP。它的创新包括实现了share noting的架构,支持线性的信息扩展,以及使用了更新颖的高压缩比引擎,可以在大数据规模下有很好的表现。从定位上说,HybridDB
for MySQL与其他分布式数据库产品各有分工。与其他阿里云数据库产品有所偏向不同,HybridDB for MySQL在OLTP和OLAP方面均有不错的扩展能力。HybridDB for MySQL吸收各家所长,希望提供一个通用的数据库解决方案来帮助用户解决大数据场景下基于SQL的业务问题。
三、技术演进路线

2013年从单机数据库加中间件的思路出发,阿里云利用分库分表中间件形成分库分表数据库。之后,阿里云对存储和计算方面进行了大幅度的优化,支持大数据存储的同时大幅降低成本,改进了SQL兼容性。今年开始做行列混合存储引擎,期望在更高的分析领域场景提供更好的服务。明年期望把RDS的PolarDB当作存储引擎,使整套数据能够运行在共享存储上,解决棘手的运维问题。
1、发展起点
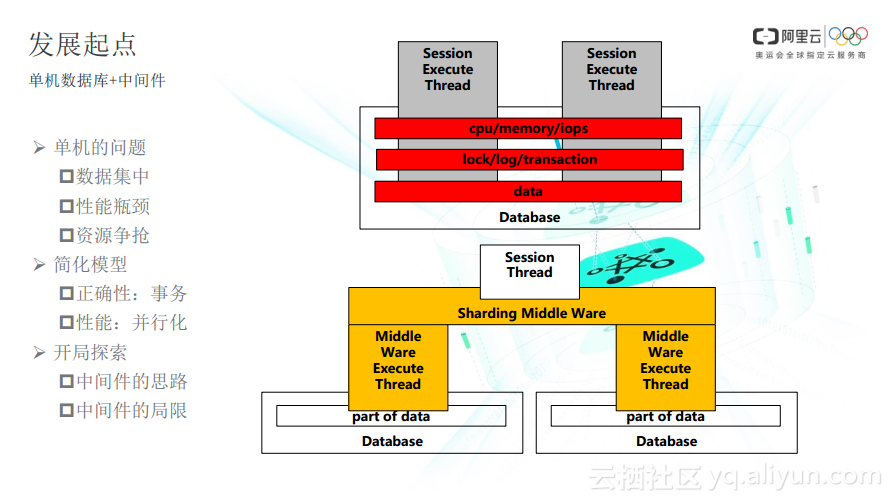
单机数据库在遇到大数据场景下有很多瓶颈,以MySQL为例,它对SQL的执行只有一个Session线程,最多只能利用一个CPU的核。当单表数据量超过千万时,它的检索显得力不从心。这时候主流搜索引擎像innoDB被加数层级会变得比较高,致使单次OLTP的查询或更新的代价更大,相应时间变高。
单机数据库几乎无法解决这种问题,因为它所有的数据(数据结构和磁盘存储)都落在一台机器上,没有办法进行线性扩展。在并发密度高的环境下,不同并发线程间会资源争抢。从硬件的CPU、内存,再到软件的锁、日志和事务,都是线程密集争抢的对象。因此并发越高,数据库的整体存储下降地愈发明显。从这个角度出发,阿里云思考如何将单机数据库的性能扩展起来?
2、合久必分
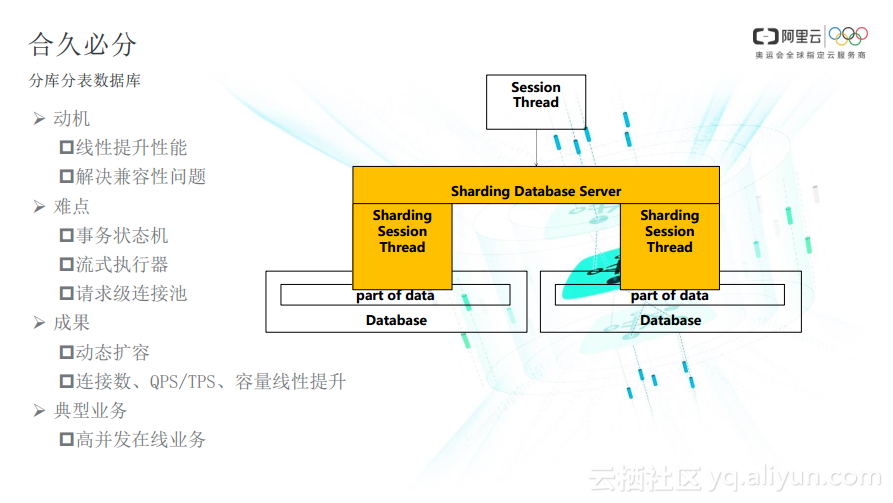
传统解决方案利用中间件把一个大数据库的数据切成多个分片,集成到用户的业务代码中提高并行能力,中间件把用户的大查询拆成多个小查询,并行的计算并行的合并。这个思路让用户的代码背上了沉重的中间件,不同的用户想使用这套体系的时候还需要重复地编码。
从这个角度出发,阿里云研发团队把中间件抽取出来加入到数据库服务器中,对外呈现同一套的数据库访问协议,让用户使用SQL连接数据库进行查询和更新。在这个过程中,中间件代理用户完成并行计算。
整个设计思路偏向于MPP数据库。MPP数据库将用户的语句通过查询解析器、优化器翻译成一个并行控制的执行计划。这样一个执行计划可以最大程度地利用多级计算资源,将数据分而治之,所有用户都可以使用MySQL的协议去访问HybridDB
for MySQL而不再关心额外的业务代码。
在这个设计架构下,阿里云研发团队遇到的问题及解决策略如下:
事务状态机。研发团队需要解决的问题是如何维护多级间数据一致性,尤其是要与原先用户的事务特性保证兼容?研发人员引入两阶段提交来解决分布式事务的问题。用户的跨区更新可以通过两阶段提交协议来保证强一致性。
流式执行器。数据库服务器的内存和磁盘空间都是有限的,不能解决超大规模的查询。例如一个表做一个全局的join in,需要把数据从各个表取出来做本地join in,如果此时再需要按不同维度排序,很可能产生临时表,而临时表往往扛不住这种压力。所以本阶段只考虑可以流式执行的SQL,包括count、sum等聚合函数以及一个维度的order by。
请求级连接池。连接到数据库的用户session很可能超过了单机上限。目前采取的措施是支持一个用户的请求级连接池。数据库从每一个连接请求中提取出执行计划,分析它后端引用的分区,不同的会话可以共享后端的分区连接。这样某些业务的前端并发连接高达数十万,而后端仅需要几千个连接。
最终,研发团队完成了一个连接数、QPS/TPS、容量线性提升,支持动态扩容的一个通用的数据库服务器。用户可以使用MySQL协议顺利接入而不需要繁琐的代码改造。目前线上服务的典型用户包括RDS的新闻数据,日均TPS达到20000多,前端并发连接日常达到8000多,每秒入库量在50000行的级别。
3、存储优化
点击查看全文

8月24日,阿里云数据库技术峰会到来,本次技术峰会邀请到了阿里集团和阿里云数据库老司机们,为大家分享了一线数据库实践经验和技术干货。阿里云高级数据库技术专家队皓庭分享了高度兼容MySQL,并且能免去传统数仓ETL过程实现数据分析,同时支持高并发、大吞吐量的在线事务处理的PB级数据存储数据库是如何实现的,帮助大家了解了同时支持海量数据在线事务(OLTP)和在线分析(OLAP)的HTAP关系型数据库是如何打造出来的。
本文将介绍HybridDB for MySQL的定位和现状,以及其技术演进路线和尚待解决的问题。
一、产品现状
HybridDB for MySQL在RDS MySQL的基础上做了很多拓展和改进,同时也保留了一些传统关系型数据库的特性。Hybrid是在2005年提出的HTAP数据库的概念,指混合的事务和分析处理。传统的数据库因为各方面的限制,偏向于OLTP或OLAP的场景,两者很难兼得,目前也只有Oracle勉强地解决了这个问题。但是在更大的数据场景下,因为Oracle产品价格高昂,一般用户往往难以承担。而MySQL在国内外拥有很高的知名度和用户量,从这个生态出发可以让阿里云研发团队收获更多的产品改进思路。HybridDB
for MySQL从个角度出发,提供一种高性价比、大数据库的产品,在解决OLTP和OLAP业务的同时,维持好MySQL的生态。
HybridDB for MySQL在SQL兼容性方面做了很多的扩展,包括支持了TPC-H和TPC-DS这两个OLAP领域的测试集。由于是阿里云的云数据库服务,HybridDB for MySQL继承了RDS的云服务特征,高可靠、高可用等特性一应俱全并支持在线的扩容。目前HybridDB for MySQL的线上服务规模遍及国内外十多个region,为阿里云及外部的用户提供了可靠服务,总数据量已经达到TB级,日新增数据达百T级。
二、产品定位
HybridDB for MySQL的定位是使用一份数据同时支持OLTP和OLAP。它的创新包括实现了share noting的架构,支持线性的信息扩展,以及使用了更新颖的高压缩比引擎,可以在大数据规模下有很好的表现。从定位上说,HybridDB
for MySQL与其他分布式数据库产品各有分工。与其他阿里云数据库产品有所偏向不同,HybridDB for MySQL在OLTP和OLAP方面均有不错的扩展能力。HybridDB for MySQL吸收各家所长,希望提供一个通用的数据库解决方案来帮助用户解决大数据场景下基于SQL的业务问题。
三、技术演进路线
2013年从单机数据库加中间件的思路出发,阿里云利用分库分表中间件形成分库分表数据库。之后,阿里云对存储和计算方面进行了大幅度的优化,支持大数据存储的同时大幅降低成本,改进了SQL兼容性。今年开始做行列混合存储引擎,期望在更高的分析领域场景提供更好的服务。明年期望把RDS的PolarDB当作存储引擎,使整套数据能够运行在共享存储上,解决棘手的运维问题。
1、发展起点
单机数据库在遇到大数据场景下有很多瓶颈,以MySQL为例,它对SQL的执行只有一个Session线程,最多只能利用一个CPU的核。当单表数据量超过千万时,它的检索显得力不从心。这时候主流搜索引擎像innoDB被加数层级会变得比较高,致使单次OLTP的查询或更新的代价更大,相应时间变高。
单机数据库几乎无法解决这种问题,因为它所有的数据(数据结构和磁盘存储)都落在一台机器上,没有办法进行线性扩展。在并发密度高的环境下,不同并发线程间会资源争抢。从硬件的CPU、内存,再到软件的锁、日志和事务,都是线程密集争抢的对象。因此并发越高,数据库的整体存储下降地愈发明显。从这个角度出发,阿里云思考如何将单机数据库的性能扩展起来?
2、合久必分
传统解决方案利用中间件把一个大数据库的数据切成多个分片,集成到用户的业务代码中提高并行能力,中间件把用户的大查询拆成多个小查询,并行的计算并行的合并。这个思路让用户的代码背上了沉重的中间件,不同的用户想使用这套体系的时候还需要重复地编码。
从这个角度出发,阿里云研发团队把中间件抽取出来加入到数据库服务器中,对外呈现同一套的数据库访问协议,让用户使用SQL连接数据库进行查询和更新。在这个过程中,中间件代理用户完成并行计算。
整个设计思路偏向于MPP数据库。MPP数据库将用户的语句通过查询解析器、优化器翻译成一个并行控制的执行计划。这样一个执行计划可以最大程度地利用多级计算资源,将数据分而治之,所有用户都可以使用MySQL的协议去访问HybridDB
for MySQL而不再关心额外的业务代码。
在这个设计架构下,阿里云研发团队遇到的问题及解决策略如下:
事务状态机。研发团队需要解决的问题是如何维护多级间数据一致性,尤其是要与原先用户的事务特性保证兼容?研发人员引入两阶段提交来解决分布式事务的问题。用户的跨区更新可以通过两阶段提交协议来保证强一致性。
流式执行器。数据库服务器的内存和磁盘空间都是有限的,不能解决超大规模的查询。例如一个表做一个全局的join in,需要把数据从各个表取出来做本地join in,如果此时再需要按不同维度排序,很可能产生临时表,而临时表往往扛不住这种压力。所以本阶段只考虑可以流式执行的SQL,包括count、sum等聚合函数以及一个维度的order by。
请求级连接池。连接到数据库的用户session很可能超过了单机上限。目前采取的措施是支持一个用户的请求级连接池。数据库从每一个连接请求中提取出执行计划,分析它后端引用的分区,不同的会话可以共享后端的分区连接。这样某些业务的前端并发连接高达数十万,而后端仅需要几千个连接。
最终,研发团队完成了一个连接数、QPS/TPS、容量线性提升,支持动态扩容的一个通用的数据库服务器。用户可以使用MySQL协议顺利接入而不需要繁琐的代码改造。目前线上服务的典型用户包括RDS的新闻数据,日均TPS达到20000多,前端并发连接日常达到8000多,每秒入库量在50000行的级别。
3、存储优化
点击查看全文

相关文章推荐
- BAT解密:互联网技术发展之路(4)- 存储层技术剖析
- 互联网技术发展之路(7)- 网络层技术剖析
- BAT解密:互联网技术发展之路(5)- 开发层技术剖析
- BAT解密:互联网技术发展之路(9)- 业务层技术剖析
- BAT解密:互联网技术发展之路(5)- 开发层技术剖析
- BAT解密:互联网技术发展之路(7)- 网络层技术剖析
- BAT解密:互联网技术发展之路(7)- 网络层技术剖析2
- BAT解密:互联网技术发展之路(7)- 网络层技术剖析
- BAT解密:互联网技术发展之路(4)- 存储层技术剖析
- BAT解密:互联网技术发展之路(5)- 开发层技术剖析
- 数据库技术发展之路
- BAT解密:互联网技术发展之路(5)- 开发层技术剖析
- BAT解密:互联网技术发展之路(4)- 存储层技术剖析
- BAT解密:互联网技术发展之路(4)- 存储层技术剖析
- BAT解密:互联网技术发展之路(7)- 网络层技术剖析
- BAT解密:互联网技术发展之路(5)- 开发层技术剖析
- BAT解密:互联网技术发展之路(6)- 服务层技术剖析
- BAT解密:互联网技术发展之路(8)- 用户层技术剖析
- 互联网技术发展之路(4)- 存储层技术剖析
- BAT解密:互联网技术发展之路(7)- 网络层技术剖析