算法 ----- 排序NB二人组 堆排序 归并排序
2017-09-04 20:21
190 查看
参考博客:基于python的七种经典排序算法 常用排序算法总结(一)
堆排序
堆排序前传 - 树与二叉树
树是一种很常见的非线性的数据结构,称为树形结构,简称树。所谓数据结构就是一组数据的集合连同它们的储存关系和对它们的操作方法。树形结构就像自然界的一颗树的构造一样,有一个根和若干个树枝和树叶。根或主干是第一层的,从主干长出的分枝是第二层的,一层一层直到最后,末端的没有分支的结点叫做叶子,所以树形结构是一个层次结构。在《数据结构》中,则用人类的血统关系来命名,一个结点的分枝叫做该结点的“孩子”,而它的上层结点叫做该结点的父亲。根结点没有父亲,叶子结点没有孩子。在《数据结构》中,用递归的方法给出了树的严格数学定义。
nlargest 现在有n个数(n>10000),设计算法,按大小顺序得到前10小的数。 应用场景:榜单TOP 10 解决思路: 取列表前10个元素建立一个小根堆。堆顶就是目前第10大的数。 依次向后遍历原列表,对于列表中的元素,如果小于堆顶,则忽略该元素;如果大于堆顶,则将堆顶更换为该元素,并且对堆进行一次调整; 遍历列表所有元素后,倒序弹出堆顶。 时间复杂度:O(nlogm) def topn(li, n): heap = li[0:n] # 建堆 for i in range(n // 2 - 1, -1, -1): sift(heap, i, n - 1) # 遍历 for i in range(n, len(li)): if li[i] > heap[0]: heap[0] = li[i] sift(heap, 0, n - 1) # 出数 for i in range(n - 1, -1, -1): heap[0], heap[i] = heap[i], heap[0] sift(heap, 0, i - 1)解决前几大的数问题!
Python内置模块——heapq 利用heapq模块实现堆排序 #每次把一个数加入堆中,向上调整(建立的是小根堆) def heapsort(li): h = [] for value in li: heappush(h, value) return [heappop(h) for i in range(len(h))] 利用heapq模块实现取top-k heapq.nlargest(10, li) #取前10大的数
归并排序 Merge sort
原理:把原始数组分成若干子列表,对每一个子列表进行排序,继续把子列表与子列表合并,合并后仍然有序,直到全部合并完,形成有序的列表。

分解:将列表越分越小,直至分成一个元素。
一个元素是有序的。
合并:将两个有序列表归并,列表越来越大。
归并排序动态演示:
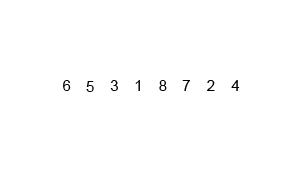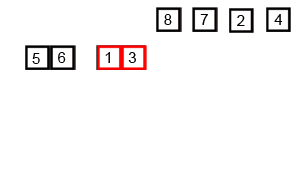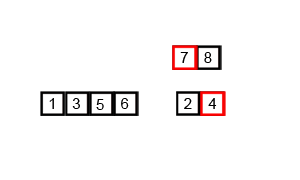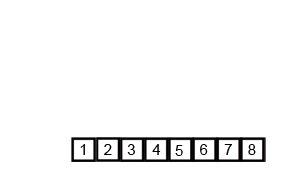

算法实现:
#!/usr/bin/env python # _*_ coding:utf-8 _*_ # 一次归并排序代码 def merge(li, low, mid, high): """ 归并排序,取之间值,对左右两个临时的列表进行排序,排序完成之后再把两个有序列表归并 """ i = low j = mid + 1 ltmp = [] # low ~ high 这一小块的列表 while i <= mid and j <= high: # 中间数左右还有数 if li[i] <= li[j]: ltmp.append(li[i]) i += 1 else: # li[i]>li[j] ltmp.append(li[j]) j += 1 # 判断左边一直有 while i <= mid: ltmp.append(li[i]) i += 1 # 判断右边一直有 while j <= high: ltmp.append(li[j]) j += 1 li[low:high + 1] = ltmp#写回原列表 def merge_sort(li, low, high): """ 利用递归分解【二分】 和归并 """ if low < high: mid = (low + high)//2 # 正当中的值 merge_sort(li, low, mid) # 递归调用左半部分 merge_sort(li, mid+1, high) # 递归调用右半部分 merge(li, low, mid, high) # 归并 return li li = [10, 4, 6, 3, 8, 2, 5, 7] high = len(li)-1 print(merge_sort(li,0,high))
归并排序对原始序列元素分布情况不敏感,其时间复杂度为O(nlogn)。
归并排序在计算过程中需要使用一定的辅助空间【空列表】,用于递归和存放结果,因此其空间复杂度为O(n)。
归并排序中不存在跳跃,只有两两比较,因此是一种稳定排序。
总之,归并排序是一种比较占用内存,但效率高,并且稳定的算法。
快速排序、堆排序、归并排序-小结
三种排序算法的时间复杂度都是O(nlogn)
一般情况下,就运行时间而言:
快速排序 < 归并排序 < 堆排序
三种排序算法的缺点:
快速排序:极端情况下排序效率低
归并排序:需要额外的内存开销
堆排序:在快的排序算法中相对较慢

相关文章推荐
- 选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,而冒泡排序、插入排序、归并排序和基数排序
- 算法基础--快排序,堆排序,归并排序
- 【更新】排序算法比较:插入排序,冒泡排序,归并排序,堆排序,快速排序,计数排序,基数排序,桶排序
- 快速排序、归并排序、堆排序三种算法性能比较
- 笔试面试最常涉及到的12种排序算法(包括插入排序、二分插入排序、希尔排序、选择排序、冒泡排序、鸡尾酒排序、快速排序、堆排序、归并排序、桶排序、计数排序和基数排序)进行了详解。每一种算法都有基本介绍、算
- 数据结构与算法之排序:堆排序、归并排序及快速排序
- 算法导论之插入排序,选择排序,归并排序,冒泡排序,希尔排序,堆排序,快速排序的c语言实现
- 选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,而冒泡排序、插入排序、归并排序和基数排序是稳定的排序算法。
- 排序(快排,冒泡,堆排序,插入排序,归并排序,选择排序)算法Java实现
- 选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法, 冒泡排序、插入排序、归并排序和基数排序是稳定的排序算法。
- 选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,而冒泡排序、插入排序、归并排序和基数排序是稳定的排序算法。
- 基本的排序算法:冒泡排序、插入排序、希尔排序、选择排序、归并排序、快速排序、堆排序
- 快速排序,插入排序,归并排序,计数排序,基数排序,堆排序
- 冒泡排序、选择排序、堆排序、快速排序、插入排序算法复杂度分析与算法实现(自己总结与转)
- 排序1+4:归并排序(MergeSort)和堆排序(HeapSort)
- 数据结构与算法:七种排序算法总结(冒泡排序、选择排序、直接插入排序、希尔排序、堆排序、归并排序、快速排序)
- 算法实现之简单选择排序、二元选择排序和堆排序
- 冒泡排序、插入排序、选择排序、希尔排序、堆排序、归并排序等常用排序算法的比较
- 【Python排序搜索基本算法】之归并排序
- 算法基础:排序之归并排序